
In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string.[1] Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.[2][3]
The figure illustrates a deterministic finite automaton using a state diagram. In this example automaton, there are three states: S0, S1, and S2 (denoted graphically by circles). The automaton takes a finite sequence of 0s and 1s as input. For each state, there is a transition arrow leading out to a next state for both 0 and 1. Upon reading a symbol, a DFA jumps deterministically from one state to another by following the transition arrow. For example, if the automaton is currently in state S0 and the current input symbol is 1, then it deterministically jumps to state S1. A DFA has a start state (denoted graphically by an arrow coming in from nowhere) where computations begin, and a set of accept states (denoted graphically by a double circle) which help define when a computation is successful.
A DFA is defined as an abstract mathematical concept, but is often implemented in hardware and software for solving various specific problems such as lexical analysis and pattern matching. For example, a DFA can model software that decides whether or not online user input such as email addresses are syntactically valid.[4]
DFAs have been generalized to nondeterministic finite automata (NFA) which may have several arrows of the same label starting from a state. Using the powerset construction method, every NFA can be translated to a DFA that recognizes the same language. DFAs, and NFAs as well, recognize exactly the set of regular languages.[1]
Formal definition
A deterministic finite automaton M is a 5-tuple, (Q, Σ, δ, q0, F), consisting of
- a finite set of states Q
- a finite set of input symbols called the alphabet Σ
- a transition function δ : Q × Σ → Q
- an initial or start state
- a set of accept states


Let w = a1a2…an be a string over the alphabet Σ. The automaton M accepts the string w if a sequence of states, r0, r1, …, rn, exists in Q with the following conditions:
- r0 = q0
- ri+1 = δ(ri, ai+1), for i = 0, …, n − 1
- .

In words, the first condition says that the machine starts in the start state q0. The second condition says that given each character of string w, the machine will transition from state to state according to the transition function δ. The last condition says that the machine accepts w if the last input of w causes the machine to halt in one of the accepting states. Otherwise, it is said that the automaton rejects the string. The set of strings that M accepts is the language recognized by M and this language is denoted by L(M).
A deterministic finite automaton without accept states and without a starting state is known as a transition system or semiautomaton.
For more comprehensive introduction of the formal definition see automata theory.
Example
The following example is of a DFA M, with a binary alphabet, which requires that the input contains an even number of 0s.
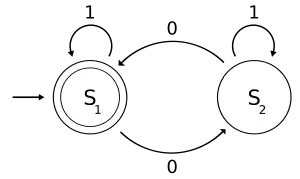
M = (Q, Σ, δ, q0, F) where
- Q = {S1, S2}
- Σ = {0, 1}
- q0 = S1
- F = {S1} and
- δ is defined by the following state transition table:
- 01
S1 S2 S1 S2 S1 S2
The state S1 represents that there has been an even number of 0s in the input so far, while S2 signifies an odd number. A 1 in the input does not change the state of the automaton. When the input ends, the state will show whether the input contained an even number of 0s or not. If the input did contain an even number of 0s, M will finish in state S1, an accepting state, so the input string will be accepted.
The language recognized by M is the regular language given by the regular expression (1*) (0 (1*) 0 (1*))*, where * is the Kleene star, e.g., 1* denotes any number (possibly zero) of consecutive ones.
Variations
Complete and incomplete
According to the above definition, deterministic finite automata are always complete: they define from each state a transition for each input symbol.
While this is the most common definition, some authors use the term deterministic finite automaton for a slightly different notion: an automaton that defines at most one transition for each state and each input symbol; the transition function is allowed to be partial.[5] When no transition is defined, such an automaton halts.
Local automata
A local automaton is a DFA, not necessarily complete, for which all edges with the same label lead to a single vertex. Local automata accept the class of local languages, those for which membership of a word in the language is determined by a "sliding window" of length two on the word.[6][7]
A Myhill graph over an alphabet A is a directed graph with vertex set A and subsets of vertices labelled "start" and "finish". The language accepted by a Myhill graph is the set of directed paths from a start vertex to a finish vertex: the graph thus acts as an automaton.[6] The class of languages accepted by Myhill graphs is the class of local languages.[8]
Randomness
When the start state and accept states are ignored, a DFA of n states and an alphabet of size k can be seen as a digraph of n vertices in which all vertices have k out-arcs labeled 1, …, k (a k-out digraph). It is known that when k ≥ 2 is a fixed integer, with high probability, the largest strongly connected component (SCC) in such a k-out digraph chosen uniformly at random is of linear size and it can be reached by all vertices.[9] It has also been proven that if k is allowed to increase as n increases, then the whole digraph has a phase transition for strong connectivity similar to Erdős–Rényi model for connectivity.[10]
In a random DFA, the maximum number of vertices reachable from one vertex is very close to the number of vertices in the largest SCC with high probability.[9][11] This is also true for the largest induced sub-digraph of minimum in-degree one, which can be seen as a directed version of 1-core.[10]
Closure properties
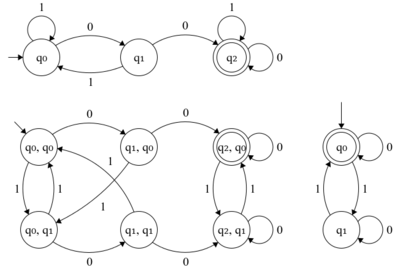
If DFAs recognize the languages that are obtained by applying an operation on the DFA recognizable languages then DFAs are said to be closed under the operation. The DFAs are closed under the following operations.
- Union
- Intersection[12]: 59–60 (see picture)
- Concatenation
- Complement
- Kleene closure
- Reversal
- Quotient
- Substitution
- Homomorphism
For each operation, an optimal construction with respect to the number of states has been determined in state complexity research. Since DFAs are equivalent to nondeterministic finite automata (NFA), these closures may also be proved using closure properties of NFA.
As a transition monoid
A run of a given DFA can be seen as a sequence of compositions of a very general formulation of the transition function with itself. Here we construct that function.
For a given input symbol , one may construct a transition function by defining for all . (This trick is called currying.) From this perspective, "acts" on a state in Q to yield another state. One may then consider the result of function composition repeatedly applied to the various functions , , and so on. Given a pair of letters , one may define a new function , where denotes function composition.









Clearly, this process may be recursively continued, giving the following recursive definition of :

- , where is the empty string and
- , where and .




is defined for all words . A run of the DFA is a sequence of compositions of with itself.


Repeated function composition forms a monoid. For the transition functions, this monoid is known as the transition monoid, or sometimes the transformation semigroup. The construction can also be reversed: given a , one can reconstruct a , and so the two descriptions are equivalent.

Advantages and disadvantages
DFAs are one of the most practical models of computation, since there is a trivial linear time, constant-space, online algorithm to simulate a DFA on a stream of input. Also, there are efficient algorithms to find a DFA recognizing:
- the complement of the language recognized by a given DFA.
- the union/intersection of the languages recognized by two given DFAs.
Because DFAs can be reduced to a canonical form (minimal DFAs), there are also efficient algorithms to determine:
- whether a DFA accepts any strings (Emptiness Problem)
- whether a DFA accepts all strings (Universality Problem)
- whether two DFAs recognize the same language (Equality Problem)
- whether the language recognized by a DFA is included in the language recognized by a second DFA (Inclusion Problem)
- the DFA with a minimum number of states for a particular regular language (Minimization Problem)
DFAs are equivalent in computing power to nondeterministic finite automata (NFAs). This is because, firstly any DFA is also an NFA, so an NFA can do what a DFA can do. Also, given an NFA, using the powerset construction one can build a DFA that recognizes the same language as the NFA, although the DFA could have exponentially larger number of states than the NFA.[13][14] However, even though NFAs are computationally equivalent to DFAs, the above-mentioned problems are not necessarily solved efficiently also for NFAs. The non-universality problem for NFAs is PSPACE complete since there are small NFAs with shortest rejecting word in exponential size. A DFA is universal if and only if all states are final states, but this does not hold for NFAs. The Equality, Inclusion and Minimization Problems are also PSPACE complete since they require forming the complement of an NFA which results in an exponential blow up of size.[15]
On the other hand, finite-state automata are of strictly limited power in the languages they can recognize; many simple languages, including any problem that requires more than constant space to solve, cannot be recognized by a DFA. The classic example of a simply described language that no DFA can recognize is bracket or Dyck language, i.e., the language that consists of properly paired brackets such as word "(()())". Intuitively, no DFA can recognize the Dyck language because DFAs are not capable of counting: a DFA-like automaton needs to have a state to represent any possible number of "currently open" parentheses, meaning it would need an unbounded number of states. Another simpler example is the language consisting of strings of the form anbn for some finite but arbitrary number of a's, followed by an equal number of b's.[16]
DFA identification from labeled words
Given a set of positive words and a set of negative words one can construct a DFA that accepts all words from and rejects all words from : this problem is called DFA identification (synthesis, learning). While some DFA can be constructed in linear time, the problem of identifying a DFA with the minimal number of states is NP-complete.[17] The first algorithm for minimal DFA identification has been proposed by Trakhtenbrot and Barzdin[18] and is called the TB-algorithm. However, the TB-algorithm assumes that all words from up to a given length are contained in either .






Later, K. Lang proposed an extension of the TB-algorithm that does not use any assumptions about and , the Traxbar algorithm.[19] However, Traxbar does not guarantee the minimality of the constructed DFA. In his work[17] E.M. Gold also proposed a heuristic algorithm for minimal DFA identification. Gold's algorithm assumes that and contain a characteristic set of the regular language; otherwise, the constructed DFA will be inconsistent either with or . Other notable DFA identification algorithms include the RPNI algorithm,[20] the Blue-Fringe evidence-driven state-merging algorithm,[21] and Windowed-EDSM.[22] Another research direction is the application of evolutionary algorithms: the smart state labeling evolutionary algorithm[23] allowed to solve a modified DFA identification problem in which the training data (sets and ) is noisy in the sense that some words are attributed to wrong classes.
Yet another step forward is due to application of SAT solvers by Marjin J. H. Heule and S. Verwer: the minimal DFA identification problem is reduced to deciding the satisfiability of a Boolean formula.[24] The main idea is to build an augmented prefix-tree acceptor (a trie containing all input words with corresponding labels) based on the input sets and reduce the problem of finding a DFA with states to coloring the tree vertices with states in such a way that when vertices with one color are merged to one state, the generated automaton is deterministic and complies with and . Though this approach allows finding the minimal DFA, it suffers from exponential blow-up of execution time when the size of input data increases. Therefore, Heule and Verwer's initial algorithm has later been augmented with making several steps of the EDSM algorithm prior to SAT solver execution: the DFASAT algorithm.[25] This allows reducing the search space of the problem, but leads to loss of the minimality guarantee. Another way of reducing the search space has been proposed by Ulyantsev et al.[26] by means of new symmetry breaking predicates based on the breadth-first search algorithm: the sought DFA's states are constrained to be numbered according to the BFS algorithm launched from the initial state. This approach reduces the search space by by eliminating isomorphic automata.


Equivalent models
Read-only right-moving Turing machines
Read-only right-moving Turing machines are a particular type of Turing machine that only moves right; these are almost exactly equivalent to DFAs.[27] The definition based on a singly infinite tape is a 7-tuple

where
- is a finite set of states;
- is a finite set of the tape alphabet/symbols;
- is the blank symbol (the only symbol allowed to occur on the tape infinitely often at any step during the computation);
- , a subset of not including b, is the set of input symbols;
- is a function called the transition function, R is a right movement (a right shift);
- is the initial state;
- is the set of final or accepting states.




The machine always accepts a regular language. There must exist at least one element of the set F (a HALT state) for the language to be nonempty.
Example of a 3-state, 2-symbol read-only Turing machine
| Current state A | Current state B | Current state C | |||||||
| tape symbol | Write symbol | Move tape | Next state | Write symbol | Move tape | Next state | Write symbol | Move tape | Next state |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | R | B | 1 | R | A | 1 | R | B |
| 1 | 1 | R | C | 1 | R | B | 1 | N | HALT |
- , "blank";
- , empty set;
- see state-table above;
- , initial state;
- the one element set of final states: .








See also
Notes
- 1 2 Hopcroft 2001
- ↑ McCulloch and Pitts (1943)
- ↑ Rabin and Scott (1959)
- ↑ Gouda, Prabhakar, Application of Finite automata
- ↑ Mogensen, Torben Ægidius (2011). "Lexical Analysis". Introduction to Compiler Design. Undergraduate Topics in Computer Science. London: Springer. p. 12. doi:10.1007/978-0-85729-829-4_1. ISBN 978-0-85729-828-7.
- 1 2 Lawson (2004) p.129
- ↑ Sakarovitch (2009) p.228
- ↑ Lawson (2004) p.128
- 1 2 Grusho, A. A. (1973). "Limit distributions of certain characteristics of random automaton graphs". Mathematical Notes of the Academy of Sciences of the USSR. 4: 633–637. doi:10.1007/BF01095785. S2CID 121723743.
- 1 2 Cai, Xing Shi; Devroye, Luc (October 2017). "The graph structure of a deterministic automaton chosen at random". Random Structures & Algorithms. 51 (3): 428–458. arXiv:1504.06238. doi:10.1002/rsa.20707. S2CID 13013344.
- ↑ Carayol, Arnaud; Nicaud, Cyril (February 2012). Distribution of the number of accessible states in a random deterministic automaton. STACS'12 (29th Symposium on Theoretical Aspects of Computer Science). Vol. 14. Paris, France. pp. 194–205.
- ↑ John E. Hopcroft and Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Reading/MA: Addison-Wesley. ISBN 0-201-02988-X.
- ↑ Sakarovitch (2009) p.105
- ↑ Lawson (2004) p.63
- ↑ Esparza Estaun, Francisco Javier; Sickert, Salomon; Blondin, Michael (16 November 2016). "Operations and tests on sets: Implementation on DFAs" (PDF). Automata and Formal Languages 2017/18. Archived from the original (PDF) on 8 August 2018.
- ↑ Lawson (2004) p.46
- 1 2 Gold, E. M. (1978). "Complexity of Automaton Identification from Given Data". Information and Control. 37 (3): 302–320. doi:10.1016/S0019-9958(78)90562-4.
- ↑ De Vries, A. (28 June 2014). Finite Automata: Behavior and Synthesis. Elsevier. ISBN 9781483297293.
- ↑ Lang, Kevin J. (1992). "Random DFA's can be approximately learned from sparse uniform examples". Proceedings of the fifth annual workshop on Computational learning theory - COLT '92. pp. 45–52. doi:10.1145/130385.130390. ISBN 089791497X. S2CID 7480497.
- ↑ Oncina, J.; García, P. (1992). "Inferring Regular Languages in Polynomial Updated Time". Pattern Recognition and Image Analysis. Series in Machine Perception and Artificial Intelligence. Vol. 1. pp. 49–61. doi:10.1142/9789812797902_0004. ISBN 978-981-02-0881-3.
- ↑ Lang, Kevin J.; Pearlmutter, Barak A.; Price, Rodney A. (1998). "Results of the Abbadingo one DFA learning competition and a new evidence-driven state merging algorithm". Grammatical Inference (PDF). Lecture Notes in Computer Science. Vol. 1433. pp. 1–12. doi:10.1007/BFb0054059. ISBN 978-3-540-64776-8.
- ↑ Beyond EDSM | Proceedings of the 6th International Colloquium on Grammatical Inference: Algorithms and Applications. 23 September 2002. pp. 37–48. ISBN 9783540442394.
- ↑ Lucas, S.M.; Reynolds, T.J. (2005). "Learning deterministic finite automata with a smart state labeling evolutionary algorithm". IEEE Transactions on Pattern Analysis and Machine Intelligence. 27 (7): 1063–1074. doi:10.1109/TPAMI.2005.143. PMID 16013754. S2CID 14062047.
- ↑ Heule, M. J. H. (2010). "Exact DFA Identification Using SAT Solvers". Grammatical Inference: Theoretical Results and Applications. Grammatical Inference: Theoretical Results and Applications. ICGI 2010. Lecture Notes in Computer Science. Lecture Notes in Computer Science. Vol. 6339. pp. 66–79. doi:10.1007/978-3-642-15488-1_7. ISBN 978-3-642-15487-4.
- ↑ Heule, Marijn J. H.; Verwer, Sicco (2013). "Software model synthesis using satisfiability solvers". Empirical Software Engineering. 18 (4): 825–856. doi:10.1007/s10664-012-9222-z. hdl:2066/103766. S2CID 17865020.
- ↑ Ulyantsev, Vladimir; Zakirzyanov, Ilya; Shalyto, Anatoly (2015). "BFS-Based Symmetry Breaking Predicates for DFA Identification". Language and Automata Theory and Applications. Lecture Notes in Computer Science. Vol. 8977. pp. 611–622. doi:10.1007/978-3-319-15579-1_48. ISBN 978-3-319-15578-4.
- ↑ Davis, Martin; Ron Sigal; Elaine J. Weyuker (1994). Second Edition: Computability, Complexity, and Languages and Logic: Fundamentals of Theoretical Computer Science (2nd ed.). San Diego: Academic Press, Harcourt, Brace & Company. ISBN 0-12-206382-1.
References
- Hopcroft, John E.; Motwani, Rajeev; Ullman, Jeffrey D. (2001). Introduction to Automata Theory, Languages, and Computation (2 ed.). Boston: Addison Wesley. ISBN 0-201-44124-1.
- Lawson, Mark V. (2004). Finite automata. Chapman and Hall/CRC. ISBN 1-58488-255-7. Zbl 1086.68074.
- McCulloch, W. S.; Pitts, W. (1943). "A Logical Calculus of the Ideas Immanent in Nervous Activity". Bulletin of Mathematical Biophysics. 5 (4): 115–133. doi:10.1007/BF02478259. PMID 2185863.
- Rabin, M. O.; Scott, D. (1959). "Finite automata and their decision problems". IBM J. Res. Dev. 3 (2): 114–125. doi:10.1147/rd.32.0114.
- Sakarovitch, Jacques (2009). Elements of automata theory. Translated from the French by Reuben Thomas. Cambridge: Cambridge University Press. ISBN 978-0-521-84425-3. Zbl 1188.68177.
- Sipser, Michael (1997). Introduction to the Theory of Computation. Boston: PWS. ISBN 0-534-94728-X.. Section 1.1: Finite Automata, pp. 31–47. Subsection "Decidable Problems Concerning Regular Languages" of section 4.1: Decidable Languages, pp. 152–155.4.4 DFA can accept only regular language