| Part of a series on |
| Machine learning and data mining |
|---|
In machine learning, diffusion models, also known as diffusion probabilistic models or score-based generative models, are a class of latent variable generative models. A diffusion model consists of three major components: the forward process, the reverse process, and the sampling procedure.[1] The goal of diffusion models is to learn a diffusion process that generates the probability distribution of a given dataset. They learn the latent structure of a dataset by modeling the way in which data points diffuse through their latent space.[2]
In the case of computer vision, diffusion models can be applied to a variety of tasks, including image denoising, inpainting, super-resolution, and image generation. This typically involves training a neural network to sequentially denoise images blurred with Gaussian noise.[2][3] The model is trained to reverse the process of adding noise to an image. After training to convergence, it can be used for image generation by starting with an image composed of random noise for the network to iteratively denoise. Announced on 13 April 2022, OpenAI's text-to-image model DALL-E 2 is an example that uses diffusion models for both the model's prior (which produces an image embedding given a text caption) and the decoder that generates the final image.[4]
Diffusion models are typically formulated as markov chains and trained using variational inference.[5] Examples of generic diffusion modeling frameworks used in computer vision are denoising diffusion probabilistic models, noise conditioned score networks, and stochastic differential equations.[6]
Denoising diffusion model
Non-equilibrium thermodynamics
Diffusion models were introduced in 2015 as a method to learn a model that can sample from a highly complex probability distribution. They used techniques from non-equilibrium thermodynamics, especially diffusion.[7]
Consider, for example, how one might model the distribution of all naturally-occurring photos. Each image is a point in the space of all images, and the distribution of naturally-occurring photos is a "cloud" in space, which, by repeatedly adding noise to the images, diffuses out to the rest of the image space, until the cloud becomes all but indistinguishable from a Gaussian distribution . A model that can approximately undo the diffusion can then be used to sample from the original distribution. This is studied in "non-equilibrium" thermodynamics, as the starting distribution is not in equilibrium, unlike the final distribution.

The equilibrium distribution is the Gaussian distribution , with pdf . This is just the Boltzmann distribution of particles in a potential well at temperature 1. The initial distribution, being very much out of equilibrium, would diffuse towards the equilibrium distribution, making biased random steps that are a sum of pure randomness (like a Brownian walker) and gradient descent down the potential well. The randomness is necessary: if the particles were to undergo only gradient descent, then they will all fall to the origin, collapsing the distribution.


Denoising Diffusion Probabilistic Model (DDPM)
The 2020 paper proposed the Denoising Diffusion Probabilistic Model (DDPM), which improves upon the previous method by variational inference.[5]
Forward diffusion
To present the model, we need some notation.
- are fixed constants.
- is the normal distribution with mean and variance , and is the probability density at .
- A vertical bar denotes conditioning.










A forward diffusion process starts at some starting point , where is the probability distribution to be learned, then repeatedly adds noise to it by



where are IID samples from . This is designed so that for any starting distribution of , we have converging to . The entire diffusion process then satisfies




or

where is a normalization constant and often omitted. In particular, we note that is a gaussian process, which affords us considerable freedom in reparameterization. For example, by standard manipulation with gaussian process,




In particular, notice that for large , the variable converges to . That is, after a long enough diffusion process, we end up with some that is very close to , with all traces of the original gone. For example, since


we can sample directly "in one step", instead of going through all the intermediate steps .







There are 5 variables and two linear equations. The two sources of randomness are , which can be reparameterized by rotation, since the IID gaussian distribution is rotationally symmetric.
By plugging in the equations, we can solve for the first reparameterization:








Backward diffusion
The key idea of DDPM is to use a neural network parametrized by . The network takes in two arguments , and outputs a vector and a matrix , such that each step in the forward diffusion process can be approximately undone by . This then gives us a backward diffusion process defined by








The goal now is to learn the parameters such that is as close to as possible. To do that, we use maximum likelihood estimation with variational inference.


Variational inference
The ELBO inequality states that , and taking one more expectation, we get
![{\displaystyle \ln p_{\theta }(x_{0})\geq E_{x_{1:T}\sim q(\cdot |x_{0})}[\ln p_{\theta }(x_{0:T})-\ln q(x_{1:T}|x_{0})]}](../I/e710509ac655cc141dedf47bdd4b1ff40466f4c2.svg)
![{\displaystyle E_{x_{0}\sim q}[\ln p_{\theta }(x_{0})]\geq E_{x_{0:T}\sim q}[\ln p_{\theta }(x_{0:T})-\ln q(x_{1:T}|x_{0})]}](../I/5eebb4676ee4edc320e675f3ae81e43656ae3961.svg)
We see that maximizing the quantity on the right would give us a lower bound on the likelihood of observed data. This allows us to perform variational inference. Define the loss function
![{\displaystyle L(\theta ):=-E_{x_{0:T}\sim q}[\ln p_{\theta }(x_{0:T})-\ln q(x_{1:T}|x_{0})]}](../I/d5e673829767320a5170ee6dcc54a0d8f37431a6.svg)
and now the goal is to minimize the loss by stochastic gradient descent. The expression may be simplified to[8]
![{\displaystyle L(\theta )=\sum _{t=1}^{T}E_{x_{t-1},x_{t}\sim q}[-\ln p_{\theta }(x_{t-1}|x_{t})]+E_{x_{0}\sim q}[D_{KL}(q(x_{T}|x_{0})\|p_{\theta }(x_{T}))]+C}](../I/670cec14d06abb89873f4eb072df8dce0b951b58.svg)
where does not depend on the parameter, and thus can be ignored. Since also does not depend on the parameter, the term can also be ignored. This leaves just with to be minimized.
![{\displaystyle E_{x_{0}\sim q}[D_{KL}(q(x_{T}|x_{0})\|p_{\theta }(x_{T}))]}](../I/928347b3890d1cfce85d1168ba30a84ad71a3883.svg)

![{\displaystyle L_{t}=E_{x_{t-1},x_{t}\sim q}[-\ln p_{\theta }(x_{t-1}|x_{t})]}](../I/8125411c9950a9347615b2c2b936b46ae50762da.svg)
Noise prediction network
Since , this suggests that we should use ; however, the network does not have access to , and so it has to estimate it instead. Now, since , we may write , where is some unknown gaussian noise. Now we see that estimating is equivalent to estimating .



Therefore, let the network output a noise vector , and let it predict


It remains to design . The DDPM paper suggested not learning it (since it resulted in "unstable training and poorer sample quality"), but fixing it at some value , where either yielded similar performance. With this, the loss simplifies to


![{\displaystyle L_{t}={\frac {\beta _{t}^{2}}{2\alpha _{t}(1-{\bar {\alpha }}_{t})\sigma _{t}^{2}}}E_{x_{0}\sim q;z\sim N(0,I)}\left[\left\|\epsilon _{\theta }(x_{t},t)-z\right\|^{2}\right]+C}](../I/06994a54199a63faa4b561c5ca596f197bb0885b.svg)
which may be minimized by stochastic gradient descent. The paper noted empirically that an even simpler loss function
![{\displaystyle L_{simple,t}=E_{x_{0}\sim q;z\sim N(0,I)}\left[\left\|\epsilon _{\theta }(x_{t},t)-z\right\|^{2}\right]}](../I/1b8bd4fba3c7ed0c479de83a4b129fa95ef00dd2.svg)
resulted in better models.
Score-based generative model
Score-based generative model is another formulation of diffusion modelling. They are also called noise conditional score network (NCSN) or score-matching with Langevin dynamics (SMLD).[9][10]
Score matching
The idea of score functions
Consider the problem of image generation. Let represent an image, and let be the probability distribution over all possible images. If we have itself, then we can say for certain how likely a certain image is. However, this is intractable in general.

Most often, we are uninterested in knowing the absolute probability of a certain image. Instead, we are usually only interested in knowing how likely a certain image is compared to its immediate neighbors — e.g. how much more likely is an image of cat compared to some small variants of it? Is it more likely if the image contains two whiskers, or three, or with some Gaussian noise added?
Consequently, we are actually quite uninterested in itself, but rather, . This has two major effects:

- One, we no longer need to normalize , but can use any , where is any unknown constant that is of no concern to us.
- Two, we are comparing neighbors , by




Let the score function be ; then consider what we can do with .


As it turns out, allows us to sample from using thermodynamics. Specifically, if we have a potential energy function , and a lot of particles in the potential well, then the distribution at thermodynamic equilibrium is the Boltzmann distribution . At temperature , the Boltzmann distribution is exactly .



Therefore, to model , we may start with a particle sampled at any convenient distribution (such as the standard gaussian distribution), then simulate the motion of the particle forwards according to the Langevin equation

and the Boltzmann distribution is, by Fokker-Planck equation, the unique thermodynamic equilibrium. So no matter what distribution has, the distribution of converges in distribution to as .


Learning the score function
Given a density , we wish to learn a score function approximation . This is score matching.[11] Typically, score matching is formalized as minimizing Fisher divergence function . By expanding the integral, and performing an integration by parts,

![{\displaystyle E_{q}[\|f_{\theta }(x)-\nabla \ln q(x)\|^{2}]}](../I/629f17805d6fd5182bc671e725d453403e337b40.svg)
![{\displaystyle E_{q}[\|f_{\theta }(x)-\nabla \ln q(x)\|^{2}]=E_{q}[\|f_{\theta }\|^{2}+2\nabla ^{2}\cdot f_{\theta }]+C}](../I/a0bfb65d5f886fb82b1fabe5d0783d47569a699e.svg)
giving us a loss function, also known as the Hyvärinen scoring rule, that can be minimized by stochastic gradient descent.
Annealing the score function
Suppose we need to model the distribution of images, and we want , a white-noise image. Now, most white-noise images do not look like real images, so for large swaths of . This presents a problem for learning the score function, because if there are no samples around a certain point, then we can't learn the score function at that point. If we do not know the score function at that point, then we cannot impose the time-evolution equation on a particle:




To deal with this problem, we perform annealing. If is too different from a white-noise distribution, then progressively add noise until it is indistinguishable from one. That is, we perform a forward diffusion, then learn the score function, then use the score function to perform a backward diffusion.
Continuous diffusion processes
Forward diffusion process
Consider again the forward diffusion process, but this time in continuous time:
By taking the limit, we obtain a continuous diffusion process, in the form of a stochastic differential equation:


where is a Wiener process (multidimensional Brownian motion). Now, the equation is exactly a special case of the overdamped Langevin equation


where is diffusion tensor, is temperature, and is potential energy field. If we substitute in , we recover the above equation. This explains why the phrase "Langevin dynamics" is sometimes used in diffusion models. Now the above equation is for the stochastic motion of a single particle. Suppose we have a cloud of particles distributed according to at time , then after a long time, the cloud of particles would settle into the stable distribution of . Let be the density of the cloud of particles at time , then we have







and the goal is to somehow reverse the process, so that we can start at the end and diffuse back to the beginning. By Fokker-Planck equation, the density of the cloud evolves according to

where is the dimension of space, and is the Laplace operator.


Backward diffusion process
If we have solved for time , then we can exactly reverse the evolution of the cloud. Suppose we start with another cloud of particles with density , and let the particles in the cloud evolve according to
![{\displaystyle t\in [0,T]}](../I/4b7ea7b28971838e52f450c48053939e81daa26f.svg)


then by plugging into the Fokker-Planck equation, we find that . Thus this cloud of points is the original cloud, evolving backwards.[12]

Noise conditional score network (NCSN)
At the continuous limit,

and so

In particular, we see that we can directly sample from any point in the continuous diffusion process without going through the intermediate steps, by first sampling , then get . That is, we can quickly sample for any . Now, define a certain probability distribution over , then the score-matching loss function is defined as the expected Fisher divergence:






![{\displaystyle L(\theta )=E_{t\sim \gamma ,x_{t}\sim \rho _{t}}[\|f_{\theta }(x_{t},t)\|^{2}+2\nabla \cdot f_{\theta }(x_{t},t)]}](../I/6d8505a3a440a3ddfa923515122f9a4402570df9.svg)
After training, , so we can perform the backwards diffusion process by first sampling , then integrating the SDE from to :




This may be done by any SDE integration method, such as Euler–Maruyama method.
The name "noise conditional score network" is explained thus:
- "network", because is implemented as a neural network.
- "score", because the output of the network is interpreted as approximating the score function .
- "noise conditional", because is equal to blurred by an added gaussian noise that increases with time, and so the score function depends on the amount of noise added.



Their equivalence
DDPM and score-based generative model are equivalent.[13] This means that a network trained using DDPM can be used as a NCSN, and vice versa.
We know that , so by Tweedie's formula, we have
![{\displaystyle \nabla _{x_{t}}\ln q(x_{t})={\frac {1}{1-{\bar {\alpha }}_{t}}}(-x_{t}+{\sqrt {{\bar {\alpha }}_{t}}}E_{q}[x_{0}|x_{t}])}](../I/ce2c98a0b9f9d8c5fb8c9f7f985b7911772f3dcb.svg)
As described previously, the DDPM loss function is with

where . By a change of variables,
![{\displaystyle L_{simple,t}=E_{x_{0},x_{t}\sim q}\left[\left\|\epsilon _{\theta }(x_{t},t)-{\frac {x_{t}-{\sqrt {{\bar {\alpha }}_{t}}}x_{0}}{\sqrt {1-{\bar {\alpha }}_{t}}}}\right\|^{2}\right]=E_{x_{t}\sim q,x_{0}\sim q(\cdot |x_{t})}\left[\left\|\epsilon _{\theta }(x_{t},t)-{\frac {x_{t}-{\sqrt {{\bar {\alpha }}_{t}}}x_{0}}{\sqrt {1-{\bar {\alpha }}_{t}}}}\right\|^{2}\right]}](../I/2104b044236422276afad7f1b2d52287777a5978.svg)
and the term inside becomes a least squares regression, so if the network actually reaches the global minimum of loss, then we have . Now, the continuous limit of the backward equation
![{\displaystyle \epsilon _{\theta }(x_{t},t)={\frac {x_{t}-{\sqrt {{\bar {\alpha }}_{t}}}E_{q}[x_{0}|x_{t}]}{\sqrt {1-{\bar {\alpha }}_{t}}}}=-{\sqrt {1-{\bar {\alpha }}_{t}}}\nabla _{x_{t}}\ln q(x_{t})}](../I/09cbdb09a02698bc9262d2e3d44a7ed1568d748a.svg)


gives us precisely the same equation as score-based diffusion:

Main variants
Denoising Diffusion Implicit Model (DDIM)
The original DDPM method for generating images is slow, since the forward diffusion process usually takes to make the distribution of to appear close to gaussian. However this means the backward diffusion process also take 1000 steps. Unlike the forward diffusion process, which can skip steps as is gaussian for all , the backward diffusion process does not allow skipping steps. For example, to sample requires the model to first sample . Attempting to directly sample would require us to marginalize out , which is generally intractable.





DDIM[14] is a method to take any model trained on DDPM loss, and use it to sample with some steps skipped, sacrificing an adjustable amount of quality. The original DDPM is a special case of DDIM.
Latent diffusion model (LDM)
Since the diffusion model is a general method for modelling probability distributions, if one wants to model a distribution over images, one can first encode the images into a lower-dimensional space by an encoder, then use a diffusion model to model the distribution over encoded images. Then to generate an image, one can sample from the diffusion model, then use a decoder to decode it into an image.[15]
The encoder-decoder pair is most often a variational autoencoder (VAE).
Classifier guidance
Suppose we wish to sample not from the entire distribution of images, but conditional on the image description. We don't want to sample a generic image, but an image that fits the description "black cat with red eyes". Generally, we want to sample from the distribution , where ranges over images, and ranges over classes of images (a description "black cat with red eyes" is just a very detailed class, and a class "cat" is just a very vague description).


Taking the perspective of the noisy channel model, we can understand the process as follows: To generate an image conditional on description , we imagine that the requester really had in mind an image , but the image is passed through a noisy channel and came out garbled, as . Image generation is then nothing but inferring which the requester had in mind.
In other words, conditional image generation is simply "translating from a textual language into a pictorial language". Then, as in noisy-channel model, we use Bayes theorem to get

in other words, if we have a good model of the space of all images, and a good image-to-class translator, we get a class-to-image translator "for free". In the equation for backward diffusion, the score can be replaced by


where is the score function, trained as previously described, and is found by using a differentiable image classifier.


With temperature
The classifier-guided diffusion model samples from , which is concentrated around the maximum a posteriori estimate . If we want to force the model to move towards the maximum likelihood estimate , we can use



where is interpretable as inverse temperature. In the context of diffusion models, it is usually called the guidance scale. A high would force the model to sample from a distribution concentrated around . This often improves quality of generated images.[16] This can be done simply by SGLD with



Classifier-free guidance (CFG)
If we do not have a classifier , we could still extract one out of the image model itself:[17]


Such a model is usually trained by presenting it with both and , allowing it to model both and .



Samplers
Given a diffusion model, one may regard it either as a continuous process, and sample from it by integrating a SDE, or one can regard it as a discrete process, and sample from it by iterating the discrete steps. The choice of the "noise schedule" can also affect the quality of samples. In the DDPM perspective, one can use the DDPM itself (with noise), or DDIM (with adjustable amount of noise). The case where one adds noise is sometimes called ancestral sampling.[18] One can interpolate between noise and no noise. The amount of noise is denoted ("eta value") in the DDIM paper, with denoting no noise (as in deterministic DDIM), and denoting full noise (as in DDPM).




In the perspective of SDE, one can use any of the numerical integration methods, such as Euler–Maruyama method, Heun's method, linear multistep methods, etc. Just as in the discrete case, one can add an adjustable amount of noise during the integration.
A survey and comparison of samplers in the context of image generation is in.[19]
Choice of architecture
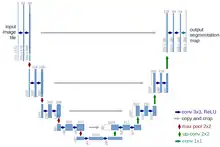
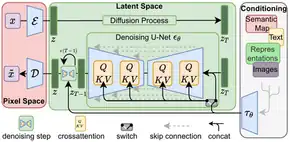

Diffusion model
For generating images by DDPM, we need a neural network that takes a time and a noisy image , and predicts a noise from it. Since predicting the noise is the same as predicting the denoised image, then subtracting it from , denoising architectures tend to work well. For example, the most common architecture is U-Net, which is also good at denoising images.[20]
For non-image data, we can use other architectures. For example,[21] models human motion trajectory by DDPM. Each human motion trajectory is a sequence of poses, represented by either joint rotations or positions. It uses a Transformer network to generate a less noisy trajectory out of a noisy one.
Conditioning
The base diffusion model can only generate unconditionally from the whole distribution. For example, a diffusion model learned on ImageNet would generate images that look like a random image from ImageNet. To generate images from just one category, one would need to impose the condition. Whatever condition one wants to impose, one needs to first convert the conditioning into a vector of floating point numbers, then feed it into the underlying diffusion model neural network. However, one has freedom in choosing how to convert the conditioning into a vector.
Stable Diffusion, for example, imposes conditioning in the form of cross-attention mechanism, where the query is an intermediate representation of the image in the U-Net, and both key and value are the conditioning vectors.[22] The conditioning can be selectively applied to only parts of an image, and new kinds of conditionings can be finetuned upon the base model, as used in ControlNet.[22]
As a particularly simple example, consider image inpainting. The conditions are , the reference image, and , the inpainting mask. The conditioning is imposed at each step of the backward diffusion process, by first sampling , a noisy version of , then replacing with , where means elementwise multiplication.[23]





Conditioning is not limited to just generating images from a specific category, or according to a specific caption (as in text-to-image). For example,[21] demonstrated generating human motion, conditioned on an audio clip of human walking (allowing syncing motion to a soundtrack), or video of human running, or a text description of human motion, etc.
Upscaling
As generating an image takes a long time, one can try to generate a small image by a base diffusion model, then upscale it by other models. Upscaling can be done by GAN,[24] Transformer,[25] or signal processing methods like Lanczos resampling.
Diffusion models themselves can be used to perform upscaling. Cascading diffusion model stacks multiple diffusion models one after another, in the style of Progressive GAN. The lowest level is a standard diffusion model that generate 32x32 image, then the image would be upscaled by a diffusion model specifically trained for upscaling, and the process repeats.[20]
Examples
This section collects some notable diffusion models, and briefly describes their architecture.
OpenAI
The DALL-E series by OpenAI are text-conditional diffusion models of images.
The first version of DALL-E (2021) is not actually a diffusion model. Instead, it uses a Transformer architecture that generates a sequence of tokens, which is then converted to an image by the decoder of a discrete VAE. Released with DALL-E was the CLIP classifier, which was used by DALL-E to rank generated images according to how close the image fits the text.
GLIDE (2022-03)[26] is a 3.5-billion diffusion model, and a small version was released publicly.[4] Soon after, DALL-E 2 was released (2022-04).[27] DALL-E 2 is a 3.5-billion cascaded diffusion model that generates images from text by "inverting the CLIP image encoder", the technique which they termed "unCLIP".
Stability AI
Stable Diffusion (2022-08), released by Stability AI, consists of a latent diffusion model (860 million parameters), a VAE, and a text encoder. The diffusion model is a U-Net, with cross-attention blocks to allow for conditional image generation.[28][15]
See also
Further reading
- Guidance: a cheat code for diffusion models. Overview of classifier guidance and classifier-free guidance, light on mathematical details.
- Mathematical details omitted in the article.
- "Power of Diffusion Models". AstraBlog. 2022-09-25. Retrieved 2023-09-25.
- Weng, Lilian (2021-07-11). "What are Diffusion Models?". lilianweng.github.io. Retrieved 2023-09-25.
References
- ↑ Chang, Ziyi; Koulieris, George Alex; Shum, Hubert P. H. (2023). "On the Design Fundamentals of Diffusion Models: A Survey". arXiv:2306.04542 [cs.LG].
- 1 2 Song, Yang; Sohl-Dickstein, Jascha; Kingma, Diederik P.; Kumar, Abhishek; Ermon, Stefano; Poole, Ben (2021-02-10). "Score-Based Generative Modeling through Stochastic Differential Equations". arXiv:2011.13456 [cs.LG].
- ↑ Gu, Shuyang; Chen, Dong; Bao, Jianmin; Wen, Fang; Zhang, Bo; Chen, Dongdong; Yuan, Lu; Guo, Baining (2021). "Vector Quantized Diffusion Model for Text-to-Image Synthesis". arXiv:2111.14822 [cs.CV].
- 1 2 GLIDE, OpenAI, 2023-09-22, retrieved 2023-09-24
- 1 2 Ho, Jonathan; Jain, Ajay; Abbeel, Pieter (2020). "Denoising Diffusion Probabilistic Models". Advances in Neural Information Processing Systems. Curran Associates, Inc. 33: 6840–6851.
- ↑ Croitoru, Florinel-Alin; Hondru, Vlad; Ionescu, Radu Tudor; Shah, Mubarak (2023). "Diffusion Models in Vision: A Survey". IEEE Transactions on Pattern Analysis and Machine Intelligence. 45 (9): 10850–10869. arXiv:2209.04747. doi:10.1109/TPAMI.2023.3261988. PMID 37030794. S2CID 252199918.
- ↑ Sohl-Dickstein, Jascha; Weiss, Eric; Maheswaranathan, Niru; Ganguli, Surya (2015-06-01). "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" (PDF). Proceedings of the 32nd International Conference on Machine Learning. PMLR. 37: 2256–2265.
- ↑ Weng, Lilian (2021-07-11). "What are Diffusion Models?". lilianweng.github.io. Retrieved 2023-09-24.
- ↑ "Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song". yang-song.net. Retrieved 2023-09-24.
- ↑ Song, Yang; Sohl-Dickstein, Jascha; Kingma, Diederik P.; Kumar, Abhishek; Ermon, Stefano; Poole, Ben (2021-02-10). "Score-Based Generative Modeling through Stochastic Differential Equations". arXiv:2011.13456 [cs.LG].
- ↑ "Sliced Score Matching: A Scalable Approach to Density and Score Estimation | Yang Song". yang-song.net. Retrieved 2023-09-24.
- ↑ Anderson, Brian D.O. (May 1982). "Reverse-time diffusion equation models". Stochastic Processes and Their Applications. 12 (3): 313–326. doi:10.1016/0304-4149(82)90051-5. ISSN 0304-4149.
- ↑ Luo, Calvin (2022). "Understanding Diffusion Models: A Unified Perspective". arXiv:2208.11970.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Song, Jiaming; Meng, Chenlin; Ermon, Stefano (2020). "Denoising Diffusion Implicit Models". arXiv:2010.02502.
{{cite journal}}: Cite journal requires|journal=(help) - 1 2 Rombach, Robin; Blattmann, Andreas; Lorenz, Dominik; Esser, Patrick; Ommer, Björn (2022). "High-Resolution Image Synthesis With Latent Diffusion Models": 10684–10695. arXiv:2112.10752.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Dhariwal, Prafulla; Nichol, Alex (2021-06-01). "Diffusion Models Beat GANs on Image Synthesis". arXiv:2105.05233 [cs.LG].
- ↑ Ho, Jonathan; Salimans, Tim (2022-07-25). "Classifier-Free Diffusion Guidance". arXiv:2207.12598 [cs.LG].
- ↑ Yang, Ling; Zhang, Zhilong; Song, Yang; Hong, Shenda; Xu, Runsheng; Zhao, Yue; Zhang, Wentao; Cui, Bin; Yang, Ming-Hsuan (2022). "Diffusion Models: A Comprehensive Survey of Methods and Applications". arXiv:2209.00796.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Karras, Tero; Aittala, Miika; Aila, Timo; Laine, Samuli (2022). "Elucidating the Design Space of Diffusion-Based Generative Models". arXiv:2206.00364.
{{cite journal}}: Cite journal requires|journal=(help) - 1 2 Ho, Jonathan; Saharia, Chitwan; Chan, William; Fleet, David J.; Norouzi, Mohammad; Salimans, Tim (2022-01-01). "Cascaded diffusion models for high fidelity image generation". The Journal of Machine Learning Research. 23 (1): 47:2249–47:2281. arXiv:2106.15282. ISSN 1532-4435.
- 1 2 Tevet, Guy; Raab, Sigal; Gordon, Brian; Shafir, Yonatan; Cohen-Or, Daniel; Bermano, Amit H. (2022). "Human Motion Diffusion Model". arXiv:2209.14916.
{{cite journal}}: Cite journal requires|journal=(help) - 1 2 Zhang, Lvmin; Rao, Anyi; Agrawala, Maneesh (2023). "Adding Conditional Control to Text-to-Image Diffusion Models". arXiv:2302.05543.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Lugmayr, Andreas; Danelljan, Martin; Romero, Andres; Yu, Fisher; Timofte, Radu; Van Gool, Luc (2022). "RePaint: Inpainting Using Denoising Diffusion Probabilistic Models": 11461–11471.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Wang, Xintao; Xie, Liangbin; Dong, Chao; Shan, Ying (2021). "Real-ESRGAN: Training Real-World Blind Super-Resolution With Pure Synthetic Data": 1905–1914. arXiv:2107.10833.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Liang, Jingyun; Cao, Jiezhang; Sun, Guolei; Zhang, Kai; Van Gool, Luc; Timofte, Radu (2021). "SwinIR: Image Restoration Using Swin Transformer": 1833–1844. arXiv:2108.10257.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Nichol, Alex; Dhariwal, Prafulla; Ramesh, Aditya; Shyam, Pranav; Mishkin, Pamela; McGrew, Bob; Sutskever, Ilya; Chen, Mark (2022-03-08). "GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models". arXiv:2112.10741 [cs.CV].
- ↑ Ramesh, Aditya; Dhariwal, Prafulla; Nichol, Alex; Chu, Casey; Chen, Mark (2022-04-12). "Hierarchical Text-Conditional Image Generation with CLIP Latents". arXiv:2204.06125 [cs.CV].
- ↑ Alammar, Jay. "The Illustrated Stable Diffusion". jalammar.github.io. Retrieved 2022-10-31.