Isolation Forest is an algorithm for data anomaly detection initially developed by Fei Tony Liu in 2008.[1] Isolation Forest detects anomalies using binary trees. The algorithm has a linear time complexity and a low memory requirement, which works well with high-volume data.[2][3] In essence, the algorithm relies upon the characteristics of anomalies, i.e., being few and different, in order to detect anomalies. No density estimation is performed in the algorithm. The algorithm is different from decision tree algorithms in that only the path-length measure or approximation is being used to generate the anomaly score, no leaf node statistics on class distribution or target value is needed.
Isolation Forest is fast because it splits the data space randomly, using randomly selected attribute and randomly selected split point. The anomaly score is invertedly associated with the path-length as anomalies need fewer splits to be isolated, due to the fact that they are few and different.
History
The Isolation Forest (iForest) algorithm was initially proposed by Fei Tony Liu, Kai Ming Ting and Zhi-Hua Zhou in 2008.[2] In 2010, an extension of the algorithm - SCiforest [4] was developed to address clustered and axis-paralleled anomalies. In 2012[3] the same authors demonstrated that iForest has linear time complexity, a small memory requirement, and is applicable to high dimensional data.
Algorithm
The premise of the Isolation Forest algorithm is that anomalous data points are easier to separate from the rest of the sample. In order to isolate a data point, the algorithm recursively generates partitions on the sample by randomly selecting an attribute and then randomly selecting a split value between the minimum and maximum values allowed for that attribute.
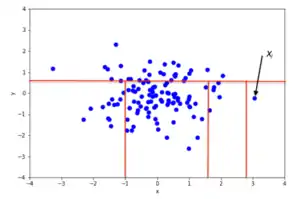
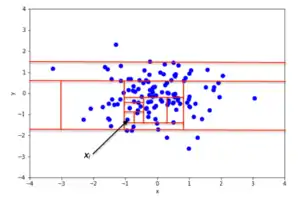
An example of random partitioning in a 2D dataset of normally distributed points is given in Fig. 2 for a non-anomalous point and Fig. 3 for a point that's more likely to be an anomaly. It is apparent from the pictures how anomalies require fewer random partitions to be isolated, compared to normal points.
Recursive partitioning can be represented by a tree structure named Isolation Tree, while the number of partitions required to isolate a point can be interpreted as the length of the path, within the tree, to reach a terminating node starting from the root. For example, the path length of point in Fig. 2 is greater than the path length of in Fig. 3.


Let be a set of d-dimensional points and . An Isolation Tree (iTree) is defined as a data structure with the following properties:


- for each node in the Tree, is either an external-node with no child, or an internal-node with one “test” and exactly two child nodes ( and )
- a test at node consists of an attribute and a split value such that the test determines the traversal of a data point to either or .






In order to build an iTree, the algorithm recursively divides by randomly selecting an attribute and a split value , until either

- the node has only one instance, or
- all data at the node have the same values.
When the iTree is fully grown, each point in is isolated at one of the external nodes. Intuitively, the anomalous points are those (easier to isolate, hence) with the smaller path length in the tree, where the path length of point is defined as the number of edges traverses from the root node to get to an external node.



A probabilistic explanation of iTree is provided in the original iForest paper.[2]
Properties of isolation forest
- Sub-sampling: As iForest does not need to isolate all normal instances, it can frequently ignore the majority of the training sample. As a consequence, iForest works very well when the sampling size is kept small, a property that is in contrast with the great majority of existing methods, where a large sampling size is usually desirable.[2][3]
- Swamping: When normal instances are too close to anomalies, the number of partitions required to separate anomalies increases, a phenomenon known as swamping, which makes it more difficult for iForest to discriminate between anomalies and normal points. One of the main reasons for swamping is the presence of too much data for the purpose of anomaly detection, which implies one possible solution to the problem is sub-sampling. Since it responds very well to sub-sampling in terms of performance, the reduction of the number of points in the sample is also a good way to reduce the effect of swamping.[2]
- Masking: When the number of anomalies is high it is possible that some of those aggregate in a dense and large cluster, making it more difficult to separate the single anomalies and, in turn, to detect such points as anomalous. Similarly, to swamping, this phenomenon (known as “masking”) is also more likely when the number of points in the sample is big and can be alleviated through sub-sampling.[2]
- High Dimensional Data: One of the main limitations of standard, distance-based methods is their inefficiency in dealing with high dimensional datasets.[5] The main reason for that is, in a high dimensional space every point is equally sparse, so using a distance-based measure of separation is pretty ineffective. Unfortunately, high-dimensional data also affects the detection performance of iForest, but the performance can be vastly improved by adding a features selection test, like Kurtosis, to reduce the dimensionality of the sample space.[2][4]
- Normal Instances Only: iForest performs well even if the training set does not contain any anomalous point,[4] the reason being that iForest describes data distributions in such a way that high values of the path length correspond to the presence of data points. As a consequence, the presence of anomalies is pretty irrelevant to iForest's detection performance.
Anomaly detection with isolation forest
Anomaly detection with Isolation Forest is a process composed of two main stages:[4]
- in the first stage, a training dataset is used to build iTrees.
- in the second stage, each instance in the test set is passed through these iTrees, and a proper “anomaly score” is assigned to the instance.
Once all the instances in the test set have been assigned an anomaly score, it is possible to mark as “anomaly” any point whose score is greater than a predefined threshold, which depends on the domain the analysis is being applied to.
Anomaly score
The algorithm for computing the anomaly score of a data point is based on the observation that the structure of iTrees is equivalent to that of Binary Search Trees (BST): a termination to an external node of the iTree corresponds to an unsuccessful search in the BST.[4] As a consequence, the estimation of average for external node terminations is the same as that of the unsuccessful searches in BST, that is[6]


where is the testing data size, is the size of the sample set and is the harmonic number, which can be estimated by , where is the Euler-Mascheroni constant.





The value of c(m) above represents the average of given , so we can use it to normalize and get an estimation of the anomaly score for a given instance x:

where is the average value of from a collection of iTrees. It is interesting to note that for any given instance :


- if is close to then is very likely to be an anomaly
- if is smaller than then is likely to be a normal value
- if for a given sample all instances are assigned an anomaly score of around , then it is safe to assume that the sample doesn't have any anomaly



Open source implementations
Original implementation by the paper authors was Isolation Forest in R.
Other implementations (in alphabetical order):
- ELKI contains a Java implementation.
- Isolation Forest - A Spark/Scala implementation.[7]
- Isolation Forest by H2O-3 - A Python implementation.
- Package solitude implementation in R.
- Python implementation with examples in scikit-learn.
- Spark iForest - A distributed Apache Spark implementation in Scala/Python.
- PyOD IForest - Another Python implementation in the popular Python Outlier Detection (PyOD) library.
Other variations of Isolation Forest algorithm implementations:
- Extended Isolation Forest – An implementation of Extended Isolation Forest.[8]
- Extended Isolation Forest by H2O-3 - An implementation of Extended Isolation Forest.
- (Python, R, C/C++) Isolation Forest and variations - An implementation of Isolation Forest and its variations.[9]
See also
References
- ↑ Liu, Fei Tony. "First Isolation Forest implementation on Sourceforge".
- 1 2 3 4 5 6 7 Liu, Fei Tony; Ting, Kai Ming; Zhou, Zhi-Hua (December 2008). "Isolation Forest". 2008 Eighth IEEE International Conference on Data Mining. pp. 413–422. doi:10.1109/ICDM.2008.17. ISBN 978-0-7695-3502-9. S2CID 6505449.
- 1 2 3 Liu, Fei Tony; Ting, Kai Ming; Zhou, Zhi-Hua (December 2008). "Isolation-Based Anomaly Detection". ACM Transactions on Knowledge Discovery from Data. 6: 3:1–3:39. doi:10.1145/2133360.2133363. S2CID 207193045.
- 1 2 3 4 5 Liu, Fei Tony; Ting, Kai Ming; Zhou, Zhi-Hua (September 2010). "On Detecting Clustered Anomalies Using SCiForest". Joint European Conference on Machine Learning and Knowledge Discovery in Databases - ECML PKDD 2010: Machine Learning and Knowledge Discovery in Databases. Lecture Notes in Computer Science. 6322: 274–290. doi:10.1007/978-3-642-15883-4_18. ISBN 978-3-642-15882-7.
- ↑ Dilini Talagala, Priyanga; Hyndman, Rob J.; Smith-Miles, Kate (12 Aug 2019). "Anomaly Detection in High Dimensional Data". arXiv:1908.04000 [stat.ML].
- ↑ Shaffer, Clifford A. (2011). Data structures & algorithm analysis in Java (3rd Dover ed.). Mineola, NY: Dover Publications. ISBN 9780486485812. OCLC 721884651.
- ↑ Verbus, James (13 August 2019). "Detecting and preventing abuse on LinkedIn using isolation forests". LinkedIn Engineering Blog. Retrieved 2023-07-02.
- ↑ Hariri, Sahand; Kind, Matias Carrasco; Brunner, Robert J. (April 2021). "Extended Isolation Forest". IEEE Transactions on Knowledge and Data Engineering. 33 (4): 1479–1489. arXiv:1811.02141. doi:10.1109/TKDE.2019.2947676. ISSN 1558-2191. S2CID 53236735.
- ↑ Cortes, David (2019). "Distance approximation using Isolation Forests". arXiv:1910.12362 [stat.ML].