| KH domain | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
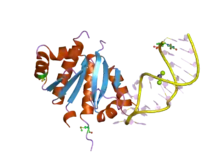 Structure of a KH domain from the human protein vigilin. | |||||||||||
| Identifiers | |||||||||||
| Symbol | KH_1 | ||||||||||
| Pfam | PF00013 | ||||||||||
| Pfam clan | CL0007 | ||||||||||
| InterPro | IPR018111 | ||||||||||
| SMART | KH | ||||||||||
| SCOP2 | 1vig / SCOPe / SUPFAM | ||||||||||
| |||||||||||
| KH domain | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||
| Symbol | KH_2 | ||||||||||
| Pfam | PF07650 | ||||||||||
| InterPro | IPR004044 | ||||||||||
| SMART | KH | ||||||||||
| PROSITE | PS50823 | ||||||||||
| |||||||||||
The K Homology (KH) domain is a protein domain that was first identified in the human heterogeneous nuclear ribonucleoprotein (hnRNP) K. An evolutionarily conserved sequence of around 70 amino acids, the KH domain is present in a wide variety of nucleic acid-binding proteins. The KH domain binds RNA, and can function in RNA recognition.[1] It is found in multiple copies in several proteins, where they can function cooperatively or independently. For example, in the AU-rich element RNA-binding protein KSRP, which has 4 KH domains, KH domains 3 and 4 behave as independent binding modules to interact with different regions of the AU-rich RNA targets.[1] The solution structure of the first KH domain of FMR1 and of the C-terminal KH domain of hnRNP K determined by nuclear magnetic resonance (NMR) revealed a beta-alpha-alpha-beta-beta-alpha structure.[2][3] Autoantibodies to NOVA1, a KH domain protein, cause paraneoplastic opsoclonus ataxia. The KH domain is found at the N-terminus of the ribosomal protein S3. This domain is unusual in that it has a different fold compared to the normal KH domain.[4]
Nucleic acid binding
KH domains bind to either RNA or single stranded DNA. The nucleic acid is bound in an extended conformation across one side of the domain. The binding occurs in a cleft formed between alpha helix 1, alpha helix 2 the GXXG loop (contains a highly conserved sequence motif) and the variable loop.[5] The binding cleft is hydrophobic in nature with a variety of additional protein specific interactions to stabilise the complex. Valverde and colleagues note that, "Nucleic acid base-to-protein aromatic side chain stacking interactions which are prevalent in other types of single stranded nucleic acid binding motifs, are notably absent in KH domain nucleic acid recognition".[5]
Structural groups

Structurally there are two different types of KH domains identified by Grishin which are called type I and type II.[4] The type I domains are mainly found in eukaryotic proteins, while the type II domains are predominantly found in prokaryotes. While both types share a minimal consensus sequence motif they have different structural folds. The type I KH domains have a three stranded beta-sheet where all three strands are anti-parallel. In the type II domain two of the three beta strands are in a parallel orientation. While type I domains are usually found in multiple copies within proteins, the type II are typically found in a single copy per protein.[5]
Human proteins containing this domain
AKAP1; ANKHD1; ANKRD17; ASCC1; BICC1; DDX43; DDX53; DPPA5; FMR1; FUBP1; FUBP3; FXR1; FXR2; GLD1; HDLBP; HNRPK; IGF2BP1; IGF2BP2; IGF2BP3; KHDRBS1; KHDRBS2; KHDRBS3; KHSRP; KRR1; MEX3A; MEX3B; MEX3C; MEX3D; NOVA1; NOVA2; PCBP1; PCBP2; PCBP3; PCBP4; PNO1; PNPT1; QKI; SF1; TDRKH;
References
- 1 2 García-Mayoral MF, Hollingworth D, Masino L, et al. (April 2007). "The structure of the C-terminal KH domains of KSRP reveals a noncanonical motif important for mRNA degradation" (PDF). Structure. 15 (4): 485–98. doi:10.1016/j.str.2007.03.006. PMID 17437720.
- ↑ Musco G, Kharrat A, Stier G, et al. (September 1997). "The solution structure of the first KH domain of FMR1, the protein responsible for the fragile X syndrome". Nat. Struct. Biol. 4 (9): 712–6. doi:10.1038/nsb0997-712. PMID 9302998. S2CID 11166126.
- ↑ Baber JL, Libutti D, Levens D, Tjandra N (June 1999). "High precision solution structure of the C-terminal KH domain of heterogeneous nuclear ribonucleoprotein K, a c-myc transcription factor". J. Mol. Biol. 289 (4): 949–62. doi:10.1006/jmbi.1999.2818. PMID 10369774.
- 1 2 Grishin NV (February 2001). "KH domain: one motif, two folds". Nucleic Acids Res. 29 (3): 638–43. doi:10.1093/nar/29.3.638. PMC 30387. PMID 11160884.
- 1 2 3 Valverde R, Edwards L, Regan L (June 2008). "Structure and function of KH domains". FEBS J. 275 (11): 2712–26. doi:10.1111/j.1742-4658.2008.06411.x. PMID 18422648.