In computing, cache replacement policies (also known as cache replacement algorithms or cache algorithms) are optimizing instructions or algorithms which a computer program or hardware-maintained structure can utilize to manage a cache of information. Caching improves performance by keeping recent or often-used data items in memory locations which are faster, or computationally cheaper to access, than normal memory stores. When the cache is full, the algorithm must choose which items to discard to make room for new data.
Overview
The average memory reference time is[1]

where
- = miss ratio = 1 - (hit ratio)
- = time to make main-memory access when there is a miss (or, with a multi-level cache, average memory reference time for the next-lower cache)
- = latency: time to reference the cache (should be the same for hits and misses)
- = secondary effects, such as queuing effects in multiprocessor systems




A cache has two primary figures of merit: latency and hit ratio. A number of secondary factors also affect cache performance.[1]
The hit ratio of a cache describes how often a searched-for item is found. More-efficient replacement policies track more usage information to improve the hit rate for a given cache size. The latency of a cache describes how long after requesting a desired item the cache can return that item when there is a hit. Faster replacement strategies typically track of less usage information—or, with a direct-mapped cache, no information—to reduce the time required to update the information. Each replacement strategy is a compromise between hit rate and latency.
Hit-rate measurements are typically performed on benchmark applications, and the hit ratio varies by application. Video and audio streaming applications often have a hit ratio near zero, because each bit of data in the stream is read once (a compulsory miss), used, and then never read or written again. Many cache algorithms (particularly LRU) allow streaming data to fill the cache, pushing out information which will soon be used again (cache pollution).[2] Other factors may be size, length of time to obtain, and expiration. Depending on cache size, no further caching algorithm to discard items may be needed. Algorithms also maintain cache coherence when several caches are used for the same data, such as multiple database servers updating a shared data file.
Policies
Bélády's Anomaly in Page Replacement Algorithms
The most efficient caching algorithm would be to discard information which would not be needed for the longest time; this is known as Bélády's optimal algorithm, optimal replacement policy, or the clairvoyant algorithm. Since it is generally impossible to predict how far in the future information will be needed, this is unfeasible in practice. The practical minimum can be calculated after experimentation, and the effectiveness of a chosen cache algorithm can be compared.
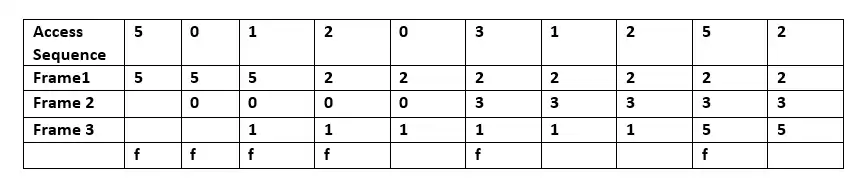
When a page fault occurs, a set of pages is in memory. In the example, the sequence of 5, 0, 1 is accessed by Frame 1, Frame 2, and Frame 3 respectively. When 2 is accessed, it replaces value 5 (which is in frame 1, predicting that value 5 will not be accessed in the near future. Because a general-purpose operating system cannot predict when 5 will be accessed, Bélády's algorithm cannot be implemented there.
Random replacement (RR)
Random replacement selects an item and discards it to make space when necessary. This algorithm does not require keeping any access history. It has been used in ARM processors due to its simplicity,[3] and it allows efficient stochastic simulation.[4]
Simple queue-based policies
First in first out (FIFO)
With this algorithm, the cache behaves like a FIFO queue; it evicts blocks in the order in which they were added, regardless of how often or how many times they were accessed before.
Last in first out (LIFO) or First in last out (FILO)
The cache behaves like a stack, and unlike a FIFO queue. The cache evicts the block added most recently first, regardless of how often or how many times it was accessed before.
Simple recency-based policies
Least recently used (LRU)
Discards least-recently-used items first. This algorithm requires keeping track of what was used and when, which is cumbersome. It requires "age bits" for cache lines, and tracks the least-recently-used cache line based on them. When a cache line is used, the age of the other cache lines changes. LRU is a family of caching algorithms, which includes 2Q by Theodore Johnson and Dennis Shasha[5] and LRU/K by Pat O'Neil, Betty O'Neil and Gerhard Weikum.[6] The access sequence for the example is A B C D E D F:
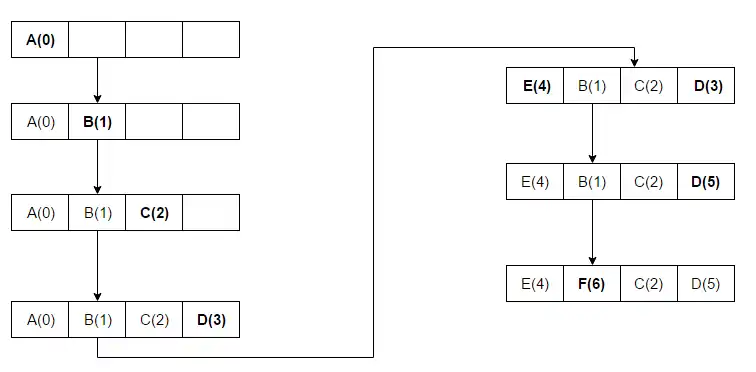
When A B C D is installed in the blocks with sequence numbers (increment 1 for each new access) and E is accessed, it is a miss and must be installed in a block. With the LRU algorithm, E will replace A because A has the lowest rank (A(0)). In the next-to-last step, D is accessed and the sequence number is updated. F is then accessed, replacing B – which had the lowest rank, (B(1)).
Time-aware, least-recently used
Time-aware, least-recently-used (TLRU)[7] is a variant of LRU designed for when the contents of a cache have a valid lifetime. The algorithm is suitable for network cache applications such as information-centric networking (ICN), content delivery networks (CDNs) and distributed networks in general. TLRU introduces a term: TTU (time to use), a timestamp of content (or a page) which stipulates the usability time for the content based on its locality and the content publisher. TTU provides more control to a local administrator in regulating network storage.
When content subject to TLRU arrives, a cache node calculates the local TTU based on the TTU assigned by the content publisher. The local TTU value is calculated with a locally-defined function. When the local TTU value is calculated, content replacement is performed on a subset of the total content of the cache node. TLRU ensures that less-popular and short-lived content is replaced with incoming content.
Most-recently-used (MRU)
Unlike LRU, MRU discards the most-recently-used items first. At the 11th VLDB conference, Chou and DeWitt said: "When a file is being repeatedly scanned in a [looping sequential] reference pattern, MRU is the best replacement algorithm."[8] Researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (also known as cyclic access patterns), MRU cache algorithms have more hits than LRU due to their tendency to retain older data.[9] MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed. The access sequence for the example is A B C D E C D B:
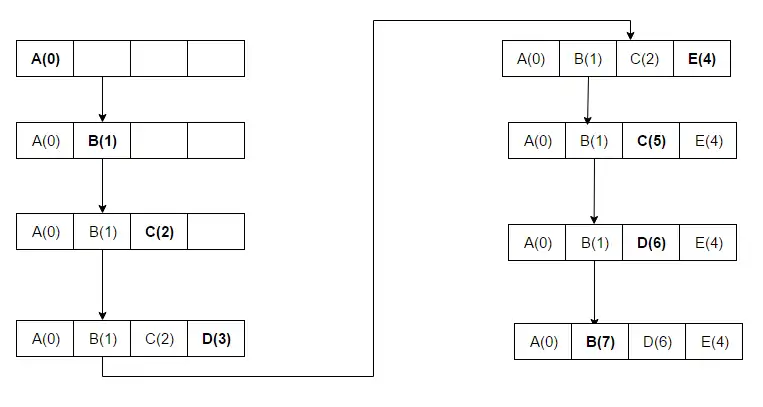
A B C D are placed in the cache, since there is space available. At the fifth access (E), the block which held D is replaced with E since this block was used most recently. At the next access (to D), C is replaced since it was the block accessed just before D.
Segmented LRU (SLRU)
An SLRU cache is divided into two segments: probationary and protected. Lines in each segment are ordered from most- to least-recently-accessed. Data from misses is added to the cache at the most-recently-accessed end of the probationary segment. Hits are removed from where they reside and added to the most-recently-accessed end of the protected segment; lines in the protected segment have been accessed at least twice. The protected segment is finite; migration of a line from the probationary segment to the protected segment may force the migration of the LRU line in the protected segment to the most-recently-used end of the probationary segment, giving this line another chance to be accessed before being replaced. The size limit of the protected segment is an SLRU parameter which varies according to I/O workload patterns. When data must be discarded from the cache, lines are obtained from the LRU end of the probationary segment.[10]
LRU approximations
LRU may be expensive in caches with higher associativity. Practical hardware usually employs an approximation to achieve similar performance at a lower hardware cost.
Pseudo-LRU (PLRU)
For CPU caches with large associativity (generally > four ways), the implementation cost of LRU becomes prohibitive. In many CPU caches, an algorithm which almost always discards one of the least-recently-used items is sufficient; many CPU designers choose a PLRU algorithm, which only needs one bit per cache item to work. PLRU typically has a slightly-worse miss ratio, slightly-better latency, uses slightly less power than LRU, and has a lower overhead than LRU.
Bits work as a binary tree of one-bit pointers which point to a less-recently-used sub-tree. Following the pointer chain to the leaf node identifies the replacement candidate. With an access, all pointers in the chain from the accessed way's leaf node to the root node are set to point to a sub-tree which does not contain the accessed path. The access sequence in the example is A B C D E:
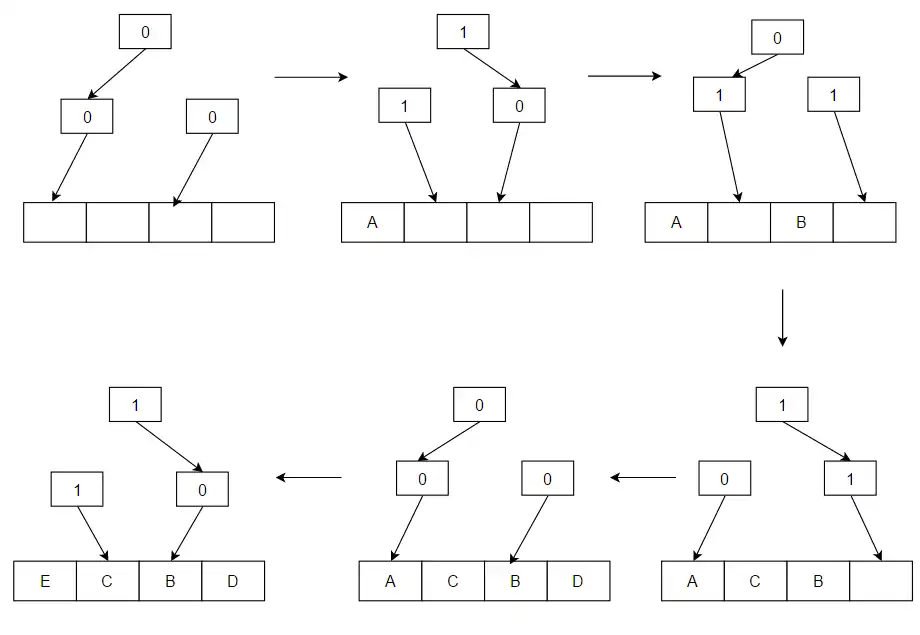
When there is access to a value (such as A) and it is not in the cache, it is loaded from memory and placed in the block where the arrows are pointing in the example. After that block is placed, the arrows are flipped to point the opposite way. A, B, C and D are placed; E replaces A as the cache fills because that was where the arrows were pointing, and the arrows which led to A flip to point in the opposite direction (to B, the block which will be replaced on the next cache miss).
Clock-Pro
The LRU algorithm cannot be implemented in the critical path of computer systems, such as operating systems, due to its high overhead; Clock, an approximation of LRU, is commonly used instead. Clock-Pro is an approximation of LIRS for low-cost implementation in systems.[11] Clock-Pro has the basic Clock framework, with three advantages. It has three "clock hands" (unlike Clock's single "hand"), and can approximately measure the reuse distance of data accesses. Like LIRS, it can quickly evict one-time-access or low-locality data items. Clock-Pro is as complex as Clock, and is easy to implement at low cost. The buffer-cache replacement implementation in the 2017 version of Linux combines LRU and Clock-Pro.[12][13]
Simple frequency-based policies
Least frequently used (LFU)
The LFU algorithm counts how often an item is needed; those used less often are discarded first. This is similar to LRU, except that how many times a block was accessed is stored instead of how recently. While running an access sequence, the block which was used the fewest times will be removed from the cache.
Least frequent recently used (LFRU)
The least frequent recently used (LFRU)[14] algorithm combines the benefits of LFU and LRU. LFRU is suitable for network cache applications such as ICN, CDNs, and distributed networks in general. In LFRU, the cache is divided into two partitions: privileged and unprivileged. The privileged partition is protected and, if content is popular, it is pushed into the privileged partition. In replacing the privileged partition, LFRU evicts content from the unprivileged partition; pushes content from the privileged to the unprivileged partition, and inserts new content into the privileged partition. LRU is used for the privileged partition, and an approximated LFU (ALFU) algorithm for the unprivileged partition.
LFU with dynamic aging (LFUDA)
A variant, LFU with dynamic aging (LFUDA), uses dynamic aging to accommodate shifts in a set of popular objects; it adds a cache-age factor to the reference count when a new object is added to the cache or an existing object is re-referenced. LFUDA increments cache age when evicting blocks by setting it to the evicted object's key value, and the cache age is always less than or equal to the minimum key value in the cache.[15] If an object was frequently accessed in the past and becomes unpopular, it will remain in the cache for a long time (preventing newly- or less-popular objects from replacing it). Dynamic aging reduces the number of such objects, making them eligible for replacement, and LFUDA reduces cache pollution caused by LFU when a cache is small.
RRIP-style policies
RRIP-style policies are the basis for other cache replacement policies, including Hawkeye.[16]
Re-Reference Interval Prediction (RRIP)
RRIP[17] is a flexible policy, proposed by Intel, which attempts to provide good scan resistance while allowing older cache lines that have not been reused to be evicted. All cache lines have a prediction value, the RRPV (re-reference prediction value), that should correlate with when the line is expected to be reused. The RRPV is usually high on insertion; if a line is not reused soon, it will be evicted to prevent scans (large amounts of data used only once) from filling the cache. When a cache line is reused the RRPV is set to zero, indicating that the line has been reused once and is likely to be reused again.
On a cache miss, the line with an RRPV equal to the maximum possible RRPV is evicted; with 3-bit values, a line with an RRPV of 23 - 1 = 7 is evicted. If no lines have this value, all RRPVs in the set are increased by 1 until one reaches it. A tie-breaker is needed, and usually it is the first line on the left. The increase is needed to ensure that older lines are aged properly and will be evicted if they are not reused.
Static RRIP (SRRIP)
SRRIP inserts lines with an RRPV value of maxRRPV; a line which has just been inserted will be the most likely to be evicted on a cache miss.
Bimodal RRIP (BRRIP)
SRRIP performs well normally, but suffers when the working set is much larger than the cache size and causes cache thrashing. This is remedied by inserting lines with an RRPV value of maxRRPV most of the time, and inserting lines with an RRPV value of maxRRPV - 1 randomly with a low probability. This causes some lines to "stick" in the cache, and helps prevent thrashing. BRRIP degrades performance, however, on non-thrashing accesses. SRRIP performs best when the working set is smaller than the cache, and BRRIP performs best when the working set is larger than the cache.
Dynamic RRIP (DRRIP)
DRRIP[17] uses set dueling[18] to select whether to use SRRIP or BRRIP. It dedicates a few sets (typically 32) to use SRRIP and another few to use BRRIP, and uses a policy counter which monitors set performance to determine which policy will be used by the rest of the cache.
Policies approximating Bélády's algorithm
Bélády's algorithm is the optimal cache replacement policy, but it requires knowledge of the future to evict lines that will be reused farthest in the future. A number of replacement policies have been proposed which attempt to predict future reuse distances from past access patterns,[19] allowing them to approximate the optimal replacement policy. Some of the best-performing cache replacement policies attempt to imitate Bélády's algorithm.
Hawkeye
Hawkeye[16] attempts to emulate Bélády's algorithm by using past accesses by a PC to predict whether the accesses it produces generate cache-friendly (used later) or cache-averse accesses (not used later). It samples a number of non-aligned cache sets, uses a history of length and emulates Bélády's algorithm on these accesses. This allows the policy to determine which lines should have been cached and which should not, predicting whether an instruction is cache-friendly or cache-averse. This data is then fed into an RRIP; accesses from cache-friendly instructions have a lower RRPV value (likely to be evicted later), and accesses from cache-averse instructions have a higher RRPV value (likely to be evicted sooner). The RRIP backend makes the eviction decisions. The sampled cache and OPT generator set the initial RRPV value of the inserted cache lines. Hawkeye won the CRC2 cache championship in 2017,[20] and Harmony[21] is an extension of Hawkeye which improves prefetching performance.

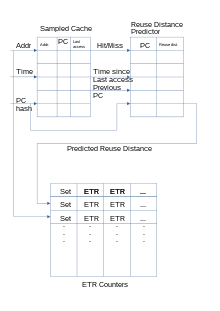
Mockingjay
Mockingjay[22] tries to improve on Hawkeye in several ways. It drops the binary prediction, allowing it to make more fine-grained decisions about which cache lines to evict, and leaves the decision about which cache line to evict for when more information is available.
Mockingjay keeps a sampled cache of unique accesses, the PCs that produced them, and their timestamps. When a line in the sampled cache is accessed again, the time difference will be sent to the reuse distance predictor. The RDP uses temporal difference learning,[23] where the new RDP value will be increased or decreased by a small number to compensate for outliers; the number is calculated as . If the value has not been initialized, the observed reuse distance is inserted directly. If the sampled cache is full and a line needs to be discarded, the RDP is instructed that the PC which last accessed it produces streaming accesses.

On an access or insertion, the estimated time of reuse (ETR) for this line is updated to reflect the predicted reuse distance. On a cache miss, the line with the highest ETR value is evicted. Mockingjay has results which are close to the optimal Bélády's algorithm.
Machine-learning policies
A number of policies have attempted to use perceptrons, markov chains or other types of machine learning to predict which line to evict.[24][25] Learning augmented algorithms also exist for cache replacement. [26][27]
Other policies
Low inter-reference recency set (LIRS)
LIRS is a page replacement algorithm with better performance than LRU and other, newer replacement algorithms. Reuse distance is a metric for dynamically ranking accessed pages to make a replacement decision.[28] LIRS addresses the limits of LRU by using recency to evaluate inter-reference recency (IRR) to make a replacement decision.
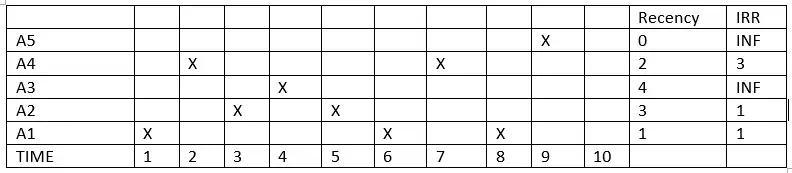
In the diagram, X indicates that a block is accessed at a particular time. If block A1 is accessed at time 1, its recency will be 0; this is the first-accessed block and the IRR will be 1, since it predicts that A1 will be accessed again in time 3. In time 2, since A4 is accessed, the recency will become 0 for A4 and 1 for A1; A4 is the most recently accessed object, and the IRR will become 4. At time 10, the LIRS algorithm will have two sets: an LIR set = {A1, A2} and an HIR set = {A3, A4, A5}. At time 10, if there is access to A4 a miss occurs; LIRS will evict A5 instead of A2 because of its greater recency.
Adaptive replacement cache
Adaptive replacement cache (ARC) constantly balances between LRU and LFU to improve the combined result.[29] It improves SLRU by using information about recently-evicted cache items to adjust the size of the protected and probationary segments to make the best use of available cache space.[30]
Clock with adaptive replacement
Clock with adaptive replacement (CAR) combines the advantages of ARC and Clock. CAR performs comparably to ARC, and outperforms LRU and Clock. Like ARC, CAR is self-tuning and requires no user-specified parameters.
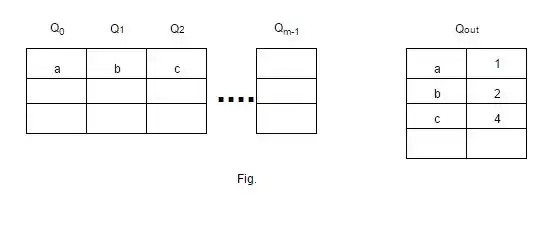
Multi-queue
The multi-queue replacement (MQ) algorithm was developed to improve the performance of a second-level buffer cache, such as a server buffer cache, and was introduced in a paper by Zhou, Philbin, and Li.[31] The MQ cache contains an m number of LRU queues: Q0, Q1, ..., Qm-1. The value of m represents a hierarchy based on the lifetime of all blocks in that queue.[32]
Pannier
Pannier[33] is a container-based flash caching mechanism which identifies containers whose blocks have variable access patterns. Pannier has a priority-queue-based survival-queue structure to rank containers based on their survival time, which is proportional to live data in the container.
Static analysis
Static analysis determines which accesses are cache hits or misses to indicate the worst-case execution time of a program.[34] An approach to analyzing properties of LRU caches is to give each block in the cache an "age" (0 for the most recently used) and compute intervals for possible ages.[35] This analysis can be refined to distinguish cases where the same program point is accessible by paths that result in misses or hits.[36] An efficient analysis may be obtained by abstracting sets of cache states by antichains which are represented by compact binary decision diagrams.[37]
LRU static analysis does not extend to pseudo-LRU policies. According to computational complexity theory, static-analysis problems posed by pseudo-LRU and FIFO are in higher complexity classes than those for LRU.[38][39]
See also
References
- 1 2 Alan Jay Smith. "Design of CPU Cache Memories". Proc. IEEE TENCON, 1987.
- ↑ Paul V. Bolotoff. "Functional Principles of Cache Memory" Archived 14 March 2012 at the Wayback Machine. 2007.
- ↑ ARM Cortex-R Series Programmer's Guide
- ↑ An Efficient Simulation Algorithm for Cache of Random Replacement Policy
- ↑ Johnson, Theodore; Shasha, Dennis (12 September 1994). "2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm" (PDF). Proceedings of the 20th International Conference on Very Large Data Bases. VLDB '94. San Francisco, CA: Morgan Kaufmann Publishers Inc.: 439–450. ISBN 978-1-55860-153-6. S2CID 6259428.
- ↑ O'Neil, Elizabeth J.; O'Neil, Patrick E.; Weikum, Gerhard (1993). "The LRU-K page replacement algorithm for database disk buffering". Proceedings of the 1993 ACM SIGMOD international conference on Management of data - SIGMOD '93. New York, NY, USA: ACM. pp. 297–306. CiteSeerX 10.1.1.102.8240. doi:10.1145/170035.170081. ISBN 978-0-89791-592-2. S2CID 207177617.
- ↑ Bilal, Muhammad; et al. (2014). "Time Aware Least Recent Used (TLRU) cache management policy in ICN". 16th International Conference on Advanced Communication Technology. pp. 528–532. arXiv:1801.00390. Bibcode:2018arXiv180100390B. doi:10.1109/ICACT.2014.6779016. ISBN 978-89-968650-3-2. S2CID 830503.
- ↑ Hong-Tai Chou and David J. DeWitt. An Evaluation of Buffer Management Strategies for Relational Database Systems. VLDB, 1985.
- ↑ Shaul Dar, Michael J. Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan. Semantic Data Caching and Replacement. VLDB, 1996.
- ↑ Ramakrishna Karedla, J. Spencer Love, and Bradley G. Wherry. Caching Strategies to Improve Disk System Performance. In Computer, 1994.
- ↑ Jiang, Song; Chen, Feng; Zhang, Xiaodong (2005). "CLOCK-Pro: An Effective Improvement of the CLOCK Replacement" (PDF). Proceedings of the Annual Conference on USENIX Annual Technical Conference. USENIX Association: 323–336.
- ↑ "Linux Memory Management: Page Replacement Design". 30 December 2017. Retrieved 30 June 2020.
- ↑ "A CLOCK-Pro page replacement implementation". LWN.net. 16 August 2005. Retrieved 30 June 2020.
- ↑ Bilal, Muhammad; et al. (2017). "A Cache Management Scheme for Efficient Content Eviction and Replication in Cache Networks". IEEE Access. 5: 1692–1701. arXiv:1702.04078. Bibcode:2017arXiv170204078B. doi:10.1109/ACCESS.2017.2669344. S2CID 14517299.
- ↑ Jayarekha, P.; Nair, T (2010). "An Adaptive Dynamic Replacement Approach for a Multicast based Popularity Aware Prefix Cache Memory System". arXiv:1001.4135 [cs.MM].
- 1 2 Jain, Akanksha; Lin, Calvin (June 2016). "Back to the Future: Leveraging Belady's Algorithm for Improved Cache Replacement". 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA). pp. 78–89. doi:10.1109/ISCA.2016.17. ISBN 978-1-4673-8947-1.
- 1 2 Jaleel, Aamer; Theobald, Kevin B.; Steely, Simon C.; Emer, Joel (19 June 2010). "High performance cache replacement using re-reference interval prediction (RRIP)". Proceedings of the 37th annual international symposium on Computer architecture. ISCA '10. New York, NY, USA: Association for Computing Machinery. pp. 60–71. doi:10.1145/1815961.1815971. ISBN 978-1-4503-0053-7. S2CID 856628.
- ↑ Qureshi, Moinuddin K.; Jaleel, Aamer; Patt, Yale N.; Steely, Simon C.; Emer, Joel (9 June 2007). "Adaptive insertion policies for high performance caching". ACM SIGARCH Computer Architecture News. 35 (2): 381–391. doi:10.1145/1273440.1250709. ISSN 0163-5964.
- ↑ Keramidas, Georgios; Petoumenos, Pavlos; Kaxiras, Stefanos (2007). "Cache replacement based on reuse-distance prediction". 2007 25th International Conference on Computer Design. pp. 245–250. doi:10.1109/ICCD.2007.4601909. ISBN 978-1-4244-1257-0. S2CID 14260179.
- ↑ "THE 2ND CACHE REPLACEMENT CHAMPIONSHIP – Co-located with ISCA June 2017". crc2.ece.tamu.edu. Retrieved 24 March 2022.
- ↑ Jain, Akanksha; Lin, Calvin (June 2018). "Rethinking Belady's Algorithm to Accommodate Prefetching". 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). pp. 110–123. doi:10.1109/ISCA.2018.00020. ISBN 978-1-5386-5984-7. S2CID 5079813.
- ↑ Shah, Ishan; Jain, Akanksha; Lin, Calvin (April 2022). "Effective Mimicry of Belady's MIN Policy". HPCA.
- ↑ Sutton, Richard S. (1 August 1988). "Learning to predict by the methods of temporal differences". Machine Learning. 3 (1): 9–44. doi:10.1007/BF00115009. ISSN 1573-0565. S2CID 207771194.
- ↑ Liu, Evan; Hashemi, Milad; Swersky, Kevin; Ranganathan, Parthasarathy; Ahn, Junwhan (21 November 2020). "An Imitation Learning Approach for Cache Replacement". International Conference on Machine Learning. PMLR: 6237–6247. arXiv:2006.16239.
- ↑ Jiménez, Daniel A.; Teran, Elvira (14 October 2017). "Multiperspective reuse prediction". Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture. New York, NY, USA: ACM. pp. 436–448. doi:10.1145/3123939.3123942. ISBN 9781450349529. S2CID 1811177.
- ↑ Lykouris, Thodoris; Vassilvitskii, Sergei (7 July 2021). "Competitive Caching with Machine Learned Advice". Journal of the ACM. 68 (4): 1–25. arXiv:1802.05399. doi:10.1145/3447579. eISSN 1557-735X. ISSN 0004-5411. S2CID 3625405.
- ↑ Mitzenmacher, Michael; Vassilvitskii, Sergei (31 December 2020). "Algorithms with Predictions". Beyond the Worst-Case Analysis of Algorithms. Cambridge University Press. pp. 646–662. arXiv:2006.09123. doi:10.1017/9781108637435.037. ISBN 9781108637435.
- ↑ Jiang, Song; Zhang, Xiaodong (June 2002). "LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance" (PDF). ACM Sigmetrics Performance Evaluation Review. Association for Computing Machinery. 30 (1): 31–42. doi:10.1145/511399.511340. ISSN 0163-5999.
- ↑ Nimrod Megiddo and Dharmendra S. Modha. ARC: A Self-Tuning, Low Overhead Replacement Cache. FAST, 2003.
- ↑ "Some insight into the read cache of ZFS - or: The ARC - c0t0d0s0.org". Archived from the original on 24 February 2009.
- ↑ Yuanyuan Zhou, James Philbin, and Kai Li. The Multi-Queue Replacement Algorithm for Second Level Buffer Caches. USENIX, 2002.
- ↑ Eduardo Pinheiro, Ricardo Bianchini, Energy conservation techniques for disk array-based servers, Proceedings of the 18th annual international conference on Supercomputing, June 26-July 01, 2004, Malo, France
- ↑ Cheng Li, Philip Shilane, Fred Douglis and Grant Wallace. Pannier: A Container-based Flash Cache for Compound Objects. ACM/IFIP/USENIX Middleware, 2015.
- ↑ Christian Ferdinand; Reinhard Wilhelm (1999). "Efficient and precise cache behavior prediction for real-time systems". Real-Time Syst. 17 (2–3): 131–181. doi:10.1023/A:1008186323068. S2CID 28282721.
- ↑ Christian Ferdinand; Florian Martin; Reinhard Wilhelm; Martin Alt (November 1999). "Cache Behavior Prediction by Abstract Interpretation". Science of Computer Programming. Springer. 35 (2–3): 163–189. doi:10.1016/S0167-6423(99)00010-6.
- ↑ Valentin Touzeau; Claire Maïza; David Monniaux; Jan Reineke (2017). "Ascertaining Uncertainty for Efficient Exact Cache Analysis". Computer-aided verification (2). arXiv:1709.10008. doi:10.1007/978-3-319-63390-9_2.
- ↑ Valentin Touzeau; Claire Maïza; David Monniaux; Jan Reineke (2019). "Fast and exact analysis for LRU caches". Proc. {ACM} Program. Lang. 3 (POPL): 54:1–54:29. arXiv:1811.01670.
- ↑ David Monniaux; Valentin Touzeau (11 November 2019). "On the complexity of cache analysis for different replacement policies". Journal of the ACM. Association for Computing Machinery. 66 (6): 1–22. doi:10.1145/3366018. S2CID 53219937.
- ↑ David Monniaux (13 May 2022). "The complexity gap in the static analysis of cache accesses grows if procedure calls are added". Formal Methods in System Design. Springer Verlag. 59 (1–3): 1–20. arXiv:2201.13056. doi:10.1007/s10703-022-00392-w. S2CID 246430884.