The Mahalanobis distance is a measure of the distance between a point and a distribution , introduced by P. C. Mahalanobis in 1936.[1] Mahalanobis's definition was prompted by the problem of identifying the similarities of skulls based on measurements in 1927.[2]


It is a multivariate generalization of the square of the standard score : how many standard deviations away is from the mean of . This distance is zero for at the mean of and grows as moves away from the mean along each principal component axis. If each of these axes is re-scaled to have unit variance, then the Mahalanobis distance corresponds to standard Euclidean distance in the transformed space. The Mahalanobis distance is thus unitless, scale-invariant, and takes into account the correlations of the data set.

Definition
Given a probability distribution on , with mean and positive-definite covariance matrix , the Mahalanobis distance of a point from is[3]






Given two points and in , the Mahalanobis distance between them with respect to is



which means that .

Since is positive-definite, so is , thus the square roots are always defined.

We can find useful decompositions of the squared Mahalanobis distance that help to explain some reasons for the outlyingness of multivariate observations and also provide a graphical tool for identifying outliers.[4]
By the spectral theorem, can be decomposed as for some real matrix, which gives us the equivalent definition



where is the Euclidean norm. That is, the Mahalanobis distance is the Euclidean distance after a whitening transformation.

The existence of is guaranteed by the spectral theorem, but it is not unique. Different choices have different theoretical and practical advantages.[5]

In practice, the distribution is usually the sample distribution from a set of IID samples from an underlying unknown distribution, so is the sample mean, and is the covariance matrix of the samples.

When the affine span of the samples is not the entire , the covariance matrix would not be positive-definite, which means the above definition would not work. However, in general, the Mahalanobis distance is preserved under any full-rank affine transformation of the affine span of the samples. So in case the affine span is not the entire , the samples can be first orthogonally projected to , where is the dimension of the affine span of the samples, then the Mahalanobis distance can be computed as usual.


Intuitive explanation
Consider the problem of estimating the probability that a test point in N-dimensional Euclidean space belongs to a set, where we are given sample points that definitely belong to that set. Our first step would be to find the centroid or center of mass of the sample points. Intuitively, the closer the point in question is to this center of mass, the more likely it is to belong to the set.
However, we also need to know if the set is spread out over a large range or a small range, so that we can decide whether a given distance from the center is noteworthy or not. The simplistic approach is to estimate the standard deviation of the distances of the sample points from the center of mass. If the distance between the test point and the center of mass is less than one standard deviation, then we might conclude that it is highly probable that the test point belongs to the set. The further away it is, the more likely that the test point should not be classified as belonging to the set.
This intuitive approach can be made quantitative by defining the normalized distance between the test point and the set to be , which reads: . By plugging this into the normal distribution, we can derive the probability of the test point belonging to the set.


The drawback of the above approach was that we assumed that the sample points are distributed about the center of mass in a spherical manner. Were the distribution to be decidedly non-spherical, for instance ellipsoidal, then we would expect the probability of the test point belonging to the set to depend not only on the distance from the center of mass, but also on the direction. In those directions where the ellipsoid has a short axis the test point must be closer, while in those where the axis is long the test point can be further away from the center.
Putting this on a mathematical basis, the ellipsoid that best represents the set's probability distribution can be estimated by building the covariance matrix of the samples. The Mahalanobis distance is the distance of the test point from the center of mass divided by the width of the ellipsoid in the direction of the test point.
Normal distributions
For a normal distribution in any number of dimensions, the probability density of an observation is uniquely determined by the Mahalanobis distance :

![{\displaystyle {\begin{aligned}\Pr[{\vec {x}}]\,d{\vec {x}}&={\frac {1}{\sqrt {\det(2\pi \mathbf {S} )}}}\exp \left(-{\frac {({\vec {x}}-{\vec {\mu }})^{\mathsf {T}}\mathbf {S} ^{-1}({\vec {x}}-{\vec {\mu }})}{2}}\right)\,d{\vec {x}}\\[6pt]&={\frac {1}{\sqrt {\det(2\pi \mathbf {S} )}}}\exp \left(-{\frac {d^{2}}{2}}\right)\,d{\vec {x}}.\end{aligned}}}](../I/39751fd0f39f3f5d60f87e6702cc9f67dadddb6b.svg)
Specifically, follows the chi-squared distribution with degrees of freedom, where is the number of dimensions of the normal distribution. If the number of dimensions is 2, for example, the probability of a particular calculated being less than some threshold is . To determine a threshold to achieve a particular probability, , use , for 2 dimensions. For number of dimensions other than 2, the cumulative chi-squared distribution should be consulted.





In a normal distribution, the region where the Mahalanobis distance is less than one (i.e. the region inside the ellipsoid at distance one) is exactly the region where the probability distribution is concave.
The Mahalanobis distance is proportional, for a normal distribution, to the square root of the negative log-likelihood (after adding a constant so the minimum is at zero).
Other forms of multivariate location and scatter
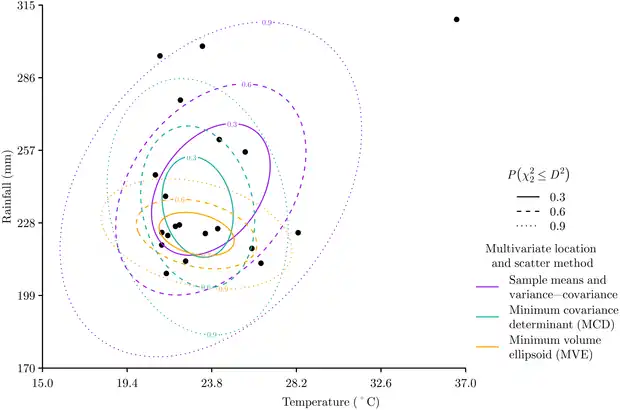
The sample mean and covariance matrix can be quite sensitive to outliers, therefore other approaches for calculating the multivariate location and scatter of data are also commonly used when calculating the Mahalanobis distance. The Minimum Covariance Determinant approach estimates multivariate location and scatter from a subset numbering data points that has the smallest variance-covariance matrix determinant.[6] The Minimum Volume Ellipsoid approach is similar to the Minimum Covariance Determinant approach in that it works with a subset of size data points, but the Minimum Volume Ellipsoid estimates multivariate location and scatter from the ellipsoid of minimal volume that encapsulates the data points.[7] Each method varies in its definition of the distribution of the data, and therefore produces different Mahalanobis distances. The Minimum Covariance Determinant and Minimum Volume Ellipsoid approaches are more robust to samples that contain outliers, while the sample mean and covariance matrix tends to be more reliable with small and biased data sets.[8]

Relationship to normal random variables
In general, given a normal (Gaussian) random variable with variance and mean , any other normal random variable (with mean and variance ) can be defined in terms of by the equation Conversely, to recover a normalized random variable from any normal random variable, one can typically solve for . If we square both sides, and take the square-root, we will get an equation for a metric that looks a lot like the Mahalanobis distance:









The resulting magnitude is always non-negative and varies with the distance of the data from the mean, attributes that are convenient when trying to define a model for the data.
Relationship to leverage
Mahalanobis distance is closely related to the leverage statistic, , but has a different scale:

Applications
Mahalanobis distance is widely used in cluster analysis and classification techniques. It is closely related to Hotelling's T-square distribution used for multivariate statistical testing and Fisher's Linear Discriminant Analysis that is used for supervised classification.[9]
In order to use the Mahalanobis distance to classify a test point as belonging to one of N classes, one first estimates the covariance matrix of each class, usually based on samples known to belong to each class. Then, given a test sample, one computes the Mahalanobis distance to each class, and classifies the test point as belonging to that class for which the Mahalanobis distance is minimal.
Mahalanobis distance and leverage are often used to detect outliers, especially in the development of linear regression models. A point that has a greater Mahalanobis distance from the rest of the sample population of points is said to have higher leverage since it has a greater influence on the slope or coefficients of the regression equation. Mahalanobis distance is also used to determine multivariate outliers. Regression techniques can be used to determine if a specific case within a sample population is an outlier via the combination of two or more variable scores. Even for normal distributions, a point can be a multivariate outlier even if it is not a univariate outlier for any variable (consider a probability density concentrated along the line , for example), making Mahalanobis distance a more sensitive measure than checking dimensions individually.

Mahalanobis distance has also been used in ecological niche modelling,[10][11] as the convex elliptical shape of the distances relates well to the concept of the fundamental niche.
Another example of usage is in finance, where Mahalanobis distance has been used to compute an indicator called the "turbulence index",[12] which is a statistical measure of financial markets abnormal behaviour. An implementation as a Web API of this indicator is available online.[13]
Software implementations
Many programming languages and statistical packages, such as R, Python, etc., include implementations of Mahalanobis distance.
| Language/program | Function | Ref. |
|---|---|---|
| Julia | mahalanobis(x, y, Q) | |
| MATLAB | mahal(x, y) | Mahalanobis distance |
| R | mahalanobis(x, center, cov, inverted = FALSE, ...) | |
| SciPy (Python) | mahalanobis(u, v, VI) |
See also
- Bregman divergence (the Mahalanobis distance is an example of a Bregman divergence)
- Bhattacharyya distance related, for measuring similarity between data sets (and not between a point and a data set)
- Hamming distance identifies the difference bit by bit of two strings
- Hellinger distance, also a measure of distance between data sets
- Similarity learning, for other approaches to learn a distance metric from examples.
References
- ↑ Mahalanobis, Prasanta Chandra (1936). "On the generalised distance in statistics" (PDF). Proceedings of the National Institute of Sciences of India. 2 (1): 49–55. Retrieved 2016-09-27.
- ↑ Mahalanobis, Prasanta Chandra (1927); Analysis of race mixture in Bengal, Journal and Proceedings of the Asiatic Society of Bengal, 23:301–333.
- ↑ De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D. L. (2000). "The Mahalanobis distance". Chemometrics and Intelligent Laboratory Systems. 50 (1): 1–18. doi:10.1016/s0169-7439(99)00047-7.
- ↑ Kim, M. G. (2000). "Multivariate outliers and decompositions of Mahalanobis distance". Communications in Statistics – Theory and Methods. 29 (7): 1511–1526. doi:10.1080/03610920008832559. S2CID 218567835.
- ↑ Kessy, Agnan; Lewin, Alex; Strimmer, Korbinian (2018-10-02). "Optimal Whitening and Decorrelation". The American Statistician. 72 (4): 309–314. arXiv:1512.00809. doi:10.1080/00031305.2016.1277159. ISSN 0003-1305. S2CID 55075085.
- ↑ Hubert, Mia; Debruyne, Michiel (2010). "Minimum covariance determinant". WIREs Computational Statistics. 2 (1): 36–43. doi:10.1002/wics.61. ISSN 1939-5108. S2CID 123086172.
- ↑ Van Aelst, Stefan; Rousseeuw, Peter (2009). "Minimum volume ellipsoid". Wiley Interdisciplinary Reviews: Computational Statistics. 1 (1): 71–82. doi:10.1002/wics.19. ISSN 1939-5108. S2CID 122106661.
- ↑ Etherington, Thomas R. (2021-05-11). "Mahalanobis distances for ecological niche modelling and outlier detection: implications of sample size, error, and bias for selecting and parameterising a multivariate location and scatter method". PeerJ. 9: e11436. doi:10.7717/peerj.11436. ISSN 2167-8359. PMC 8121071. PMID 34026369.
- ↑ McLachlan, Geoffrey (4 August 2004). Discriminant Analysis and Statistical Pattern Recognition. John Wiley & Sons. pp. 13–. ISBN 978-0-471-69115-0.
- ↑ Etherington, Thomas R. (2019-04-02). "Mahalanobis distances and ecological niche modelling: correcting a chi-squared probability error". PeerJ. 7: e6678. doi:10.7717/peerj.6678. ISSN 2167-8359. PMC 6450376. PMID 30972255.
- ↑ Farber, Oren; Kadmon, Ronen (2003). "Assessment of alternative approaches for bioclimatic modeling with special emphasis on the Mahalanobis distance". Ecological Modelling. 160 (1–2): 115–130. doi:10.1016/S0304-3800(02)00327-7.
- ↑ Kritzman, M.; Li, Y. (2019-04-02). "Skulls, Financial Turbulence, and Risk Management". Financial Analysts Journal. 66 (5): 30–41. doi:10.2469/faj.v66.n5.3. S2CID 53478656.
- ↑ "Portfolio Optimizer". portfoliooptimizer.io/. Retrieved 2022-04-23.
External links
- "Mahalanobis distance", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Mahalanobis distance tutorial – interactive online program and spreadsheet computation
- Mahalanobis distance (Nov-17-2006) – overview of Mahalanobis distance, including MATLAB code
- What is Mahalanobis distance? – intuitive, illustrated explanation, from Rick Wicklin on blogs.sas.com