In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .




Problem statement
An algorithm for the selection problem takes as input a collection of values, and a number . It outputs the th smallest of these values, or, in some versions of the problem, a collection of the smallest values. For this to be well-defined, it should be possible to sort the values into an order from smallest to largest; for instance, they may be integers, floating-point numbers, or some other kind of object with a numeric key. However, they are not assumed to have been already sorted. Often, selection algorithms are restricted to a comparison-based model of computation, as in comparison sort algorithms, where the algorithm has access to a comparison operation that can determine the relative ordering of any two values, but may not perform any other kind of arithmetic operations on these values.[1]
To simplify the problem, some works on this problem assume that the values are all distinct from each other,[2] or that some consistent tie-breaking method has been used to assign an ordering to pairs of items with the same value as each other. Another variation in the problem definition concerns the numbering of the ordered values: is the smallest value obtained by setting , as in zero-based numbering of arrays, or is it obtained by setting , following the usual English-language conventions for the smallest, second-smallest, etc.? This article follows the conventions used by Cormen et al., according to which all values are distinct and the minimum value is obtained from .[2]


With these conventions, the maximum value, among a collection of values, is obtained by setting . When is an odd number, the median of the collection is obtained by setting . When is even, there are two choices for the median, obtained by rounding this choice of down or up, respectively: the lower median with and the upper median with .[2]




Algorithms
Sorting and heapselect
As a baseline algorithm, selection of the th smallest value in a collection of values can be performed by the following two steps:
- Sort the collection
- If the output of the sorting algorithm is an array, retrieve its th element; otherwise, scan the sorted sequence to find the th element.
The time for this method is dominated by the sorting step, which requires time using a comparison sort.[2][3] Even when integer sorting algorithms may be used, these are generally slower than the linear time that may be achieved using specialized selection algorithms. Nevertheless, the simplicity of this approach makes it attractive, especially when a highly-optimized sorting routine is provided as part of a runtime library, but a selection algorithm is not. For inputs of moderate size, sorting can be faster than non-random selection algorithms, because of the smaller constant factors in its running time.[4] This method also produces a sorted version of the collection, which may be useful for other later computations, and in particular for selection with other choices of .[3]

For a sorting algorithm that generates one item at a time, such as selection sort, the scan can be done in tandem with the sort, and the sort can be terminated once the th element has been found. One possible design of a consolation bracket in a single-elimination tournament, in which the teams who lost to the eventual winner play another mini-tournament to determine second place, can be seen as an instance of this method.[5] Applying this optimization to heapsort produces the heapselect algorithm, which can select the th smallest value in time .[6] This is fast when is small relative to , but degenerates to for larger values of , such as the choice used for median finding.


Pivoting
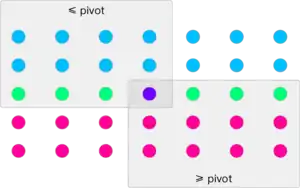
Many methods for selection are based on choosing a special "pivot" element from the input, and using comparisons with this element to divide the remaining input values into two subsets: the set of elements less than the pivot, and the set of elements greater than the pivot. The algorithm can then determine where the th smallest value is to be found, based on a comparison of with the sizes of these sets. In particular, if , the th smallest value is in , and can be found recursively by applying the same selection algorithm to . If , then the th smallest value is the pivot, and it can be returned immediately. In the remaining case, the th smallest value is in , and more specifically it is the element in position of . It can be found by applying a selection algorithm recursively, seeking the value in this position in .[7]






As with the related pivoting-based quicksort algorithm, the partition of the input into and may be done by making new collections for these sets, or by a method that partitions a given list or array data type in-place. Details vary depending on how the input collection is represented.[8] The time to compare the pivot against all the other values is .[7] However, pivoting methods differ in how they choose the pivot, which affects how big the subproblems in each recursive call will be. The efficiency of these methods depends greatly on the choice of the pivot. If the pivot is chosen badly, the running time of this method can be as slow as .[4]

- If the pivot were exactly at the median of the input, then each recursive call would have at most half as many values as the previous call, and the total times would add in a geometric series to . However, finding the median is itself a selection problem, on the entire original input. Trying to find it by a recursive call to a selection algorithm would lead to an infinite recursion, because the problem size would not decrease in each call.[7]
- Quickselect chooses the pivot uniformly at random from the input values. It can be described as a prune and search algorithm,[9] a variant of quicksort, with the same pivoting strategy, but where quicksort makes two recursive calls to sort the two subcollections and , quickselect only makes one of these two calls. Its expected time is .[2][7][9] For any constant , the probability that its number of comparisons exceeds is superexponentially small in .[10]
- The Floyd–Rivest algorithm, a variation of quickselect, chooses a pivot by randomly sampling a subset of data values, for some sample size , and then recursively selecting two elements somewhat above and below position of the sample to use as pivots. With this choice, it is likely that is sandwiched between the two pivots, so that after pivoting only a small number of data values between the pivots are left for a recursive call. This method can achieve an expected number of comparisons that is .[11] In their original work, Floyd and Rivest claimed that the term could be made as small as by a recursive sampling scheme, but the correctness of their analysis has been questioned.[12][13] Instead, more rigorous analysis has shown that a version of their algorithm achieves for this term.[14] Although the usual analysis of both quickselect and the Floyd–Rivest algorithm assumes the use of a true random number generator, a version of the Floyd–Rivest algorithm using a pseudorandom number generator seeded with only logarithmically many true random bits has been proven to run in linear time with high probability.[15]









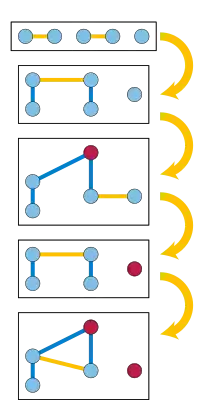
- The median of medians method partitions the input into sets of five elements, and uses some other non-recursive method to find the median of each of these sets in constant time per set. It then recursively calls itself to find the median of these medians. Using the resulting median of medians as the pivot produces a partition with . Thus, a problem on elements is reduced to two recursive problems on elements (to find the pivot) and at most elements (after the pivot is used). The total size of these two recursive subproblems is at most , allowing the total time to be analyzed as a geometric series adding to . Unlike quickselect, this algorithm is deterministic, not randomized.[2][4][5] It was the first linear-time deterministic selection algorithm known,[5] and is commonly taught in undergraduate algorithms classes as an example of a divide and conquer that does not divide into two equal subproblems.[2][4][9][16] However, the high constant factors in its time bound make it slower than quickselect in practice,[3][9] and slower even than sorting for inputs of moderate size.[4]
- Hybrid algorithms such as introselect can be used to achieve the practical performance of quickselect with a fallback to medians of medians guaranteeing worst-case time.[17]




Factories
The deterministic selection algorithms with the smallest known numbers of comparisons, for values of that are far from or , are based on the concept of factories, introduced in 1976 by Arnold Schönhage, Mike Paterson, and Nick Pippenger.[18] These are methods that build partial orders of certain specified types, on small subsets of input values, by using comparisons to combine smaller partial orders. As a very simple example, one type of factory can take as input a sequence of single-element partial orders, compare pairs of elements from these orders, and produce as output a sequence of two-element totally ordered sets. The elements used as the inputs to this factory could either be input values that have not been compared with anything yet, or "waste" values produced by other factories. The goal of a factory-based algorithm is to combine together different factories, with the outputs of some factories going to the inputs of others, in order to eventually obtain a partial order in which one element (the th smallest) is larger than some other elements and smaller than another others. A careful design of these factories leads to an algorithm that, when applied to median-finding, uses at most comparisons. For other values of , the number of comparisons is smaller.[19]




Parallel algorithms
Parallel algorithms for selection have been studied since 1975, when Leslie Valiant introduced the parallel comparison tree model for analyzing these algorithms, and proved that in this model selection using a linear number of comparisons requires parallel steps, even for selecting the minimum or maximum.[20] Researchers later found parallel algorithms for selection in steps, matching this bound.[21][22] In a randomized parallel comparison tree model it is possible to perform selection in a bounded number of steps and a linear number of comparisons.[23] On the more realistic parallel RAM model of computing, with exclusive read exclusive write memory access, selection can be performed in time with processors, which is optimal both in time and in the number of processors.[24] With concurrent memory access, slightly faster parallel time is possible in general,[25] and the term in the time bound can be replaced by .[26]






Sublinear data structures
When data is already organized into a data structure, it may be possible to perform selection in an amount of time that is sublinear in the number of values. As a simple case of this, for data already sorted into an array, selecting the th element may be performed by a single array lookup, in constant time.[27] For values organized into a two-dimensional array of size , with sorted rows and columns, selection may be performed in time , or faster when is small relative to the array dimensions.[27][28] For a collection of one-dimensional sorted arrays, with items less than the selected item in the th array, the time is .[28]






Selection from data in a binary heap takes time . This is independent of the size of the heap, and faster than the time bound that would be obtained from best-first search.[28][29] This same method can be applied more generally to data organized as any kind of heap-ordered tree (a tree in which each node stores one value in which the parent of each non-root node has a smaller value than its child). This method of performing selection in a heap has been applied to problems of listing multiple solutions to combinatorial optimization problems, such as finding the k shortest paths in a weighted graph, by defining a state space of solutions in the form of an implicitly defined heap-ordered tree, and then applying this selection algorithm to this tree.[30] In the other direction, linear time selection algorithms have been used as a subroutine in a priority queue data structure related to the heap, improving the time for extracting its th item from to ; here is the iterated logarithm.[31]




For a collection of data values undergoing dynamic insertions and deletions, the order statistic tree augments a self-balancing binary search tree structure with a constant amount of additional information per tree node, allowing insertions, deletions, and selection queries that ask for the th element in the current set to all be performed in time per operation.[2] Going beyond the comparison model of computation, faster times per operation are possible for values that are small integers, on which binary arithmetic operations are allowed.[32] It is not possible for a streaming algorithm with memory sublinear in both and to solve selection queries exactly for dynamic data, but the count–min sketch can be used to solve selection queries approximately, by finding a value whose position in the ordering of the elements (if it were added to them) would be within steps of , for a sketch whose size is within logarithmic factors of .[33]


Lower bounds
The running time of the selection algorithms described above is necessary, because a selection algorithm that can handle inputs in an arbitrary order must take that much time to look at all of its inputs. If any one of its input values is not compared, that one value could be the one that should have been selected, and the algorithm can be made to produce an incorrect answer.[28] Beyond this simple argument, there has been a significant amount of research on the exact number of comparisons needed for selection, both in the randomized and deterministic cases.
Selecting the minimum of values requires comparisons, because the values that are not selected must each have been determined to be non-minimal, by being the largest in some comparison, and no two of these values can be largest in the same comparison. The same argument applies symmetrically to selecting the maximum.[14]
The next simplest case is selecting the second-smallest. After several incorrect attempts, the first tight lower bound on this case was published in 1964 by Soviet mathematician Sergey Kislitsyn. It can be shown by observing that selecting the second-smallest also requires distinguishing the smallest value from the rest, and by considering the number of comparisons involving the smallest value that an algorithm for this problem makes. Each of the items that were compared to the smallest value is a candidate for second-smallest, and of these values must be found larger than another value in a second comparison in order to rule them out as second-smallest. With values being the larger in at least one comparison, and values being the larger in at least two comparisons, there are a total of at least comparisons. An adversary argument, in which the outcome of each comparison is chosen in order to maximize (subject to consistency with at least one possible ordering) rather than by the numerical values of the given items, shows that it is possible to force to be at least . Therefore, the worst-case number of comparisons needed to select the second smallest is , the same number that would be obtained by holding a single-elimination tournament with a run-off tournament among the values that lost to the smallest value. However, the expected number of comparisons of a randomized selection algorithm can be better than this bound; for instance, selecting the second-smallest of six elements requires seven comparisons in the worst case, but may be done by a randomized algorithm with an expected number of 6.5 comparisons.[14]





More generally, selecting the th element out of requires at least comparisons, in the average case, matching the number of comparisons of the Floyd–Rivest algorithm up to its term. The argument is made directly for deterministic algorithms, with a number of comparisons that is averaged over all possible permutations of the input values.[1] By Yao's principle, it also applies to the expected number of comparisons for a randomized algorithm on its worst-case input.[34]

For deterministic algorithms, it has been shown that selecting the th element requires comparisons, where


is the binary entropy function.[35] The special case of median-finding has a slightly larger lower bound on the number of comparisons, at least , for .[36]


Exact numbers of comparisons
Knuth supplies the following triangle of numbers summarizing pairs of and for which the exact number of comparisons needed by an optimal selection algorithm is known. The th row of the triangle (starting with in the top row) gives the numbers of comparisons for inputs of values, and the th number within each row gives the number of comparisons needed to select the th smallest value from an input of that size. The rows are symmetric because selecting the th smallest requires exactly the same number of comparisons, in the worst case, as selecting the th largest.[14]

Most, but not all, of the entries on the left half of each row can be found using the formula

This describes the number of comparisons made by a method of Abdollah Hadian and Milton Sobel, related to heapselect, that finds the smallest value using a single-elimination tournament and then repeatedly uses a smaller tournament among the values eliminated by the eventual tournament winners to find the next successive values until reaching the th smallest.[14][37] Some of the larger entries were proven to be optimal using a computer search.[14][38]
Language support
Very few languages have built-in support for general selection, although many provide facilities for finding the smallest or largest element of a list. A notable exception is the Standard Template Library for C++, which provides a templated nth_element method with a guarantee of expected linear time.[3]
Python's standard library (since 2.4) includes heapq.nsmallest and heapq.nlargest subroutines for returning the smallest or largest elements from a collection, in sorted order. Different versions of Python have used different algorithms for these subroutines. As of Python version 3.13, the implementation maintains a binary heap, limited to holding elements, and initialized to the first elements in the collection. Then, each subsequent items of the collection may replace the largest or smallest element in the heap (respectively for heapq.nsmallest and heapq.nlargest) if it is smaller or larger than this element. The worst-case time for this implementation is , worse than the that would be achieved by heapselect. However, for random input sequences, there are likely to be few heap updates and most input elements are processed with only a single comparison.[39]

Since 2017, Matlab has included maxk() and mink() functions, which return the maximal (minimal) values in a vector as well as their indices. The Matlab documentation does not specify which algorithm these functions use or what their running time is.[40]
History
Quickselect was presented without analysis by Tony Hoare in 1965,[41] and first analyzed in a 1971 technical report by Donald Knuth.[11] The first known linear time deterministic selection algorithm is the median of medians method, published in 1973 by Manuel Blum, Robert W. Floyd, Vaughan Pratt, Ron Rivest, and Robert Tarjan.[5] They trace the formulation of the selection problem to work of Charles L. Dodgson (better known as Lewis Carroll) who in 1883 pointed out that the usual design of single-elimination sports tournaments does not guarantee that the second-best player wins second place,[5][42] and to work of Hugo Steinhaus circa 1930, who followed up this same line of thought by asking for a tournament design that can make this guarantee, with a minimum number of games played (that is, comparisons).[5]
See also
- Geometric median § Computation, algorithms for higher-dimensional generalizations of medians
- Median filter, application of median-finding algorithms in image processing
References
- 1 2 Cunto, Walter; Munro, J. Ian (1989). "Average case selection". Journal of the ACM. 36 (2): 270–279. doi:10.1145/62044.62047. MR 1072421. S2CID 10947879.
- 1 2 3 4 5 6 7 8 Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. "Chapter 9: Medians and order statistics". Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. pp. 213–227. ISBN 0-262-03384-4.; "Section 14.1: Dynamic order statistics", pp. 339–345
- 1 2 3 4 Skiena, Steven S. (2020). "17.3: Median and selection". The Algorithm Design Manual. Texts in Computer Science (Third ed.). Springer. pp. 514–516. doi:10.1007/978-3-030-54256-6. ISBN 978-3-030-54255-9. MR 4241430. S2CID 22382667.
- 1 2 3 4 5 Erickson, Jeff (June 2019). "1.8: Linear-time selection". Algorithms. pp. 35–39.
- 1 2 3 4 5 6 Blum, Manuel; Floyd, Robert W.; Pratt, Vaughan; Rivest, Ronald L.; Tarjan, Robert E. (1973). "Time bounds for selection" (PDF). Journal of Computer and System Sciences. 7 (4): 448–461. doi:10.1016/S0022-0000(73)80033-9. MR 0329916.
- ↑ Brodal, Gerth Stølting (2013). "A survey on priority queues". In Brodnik, Andrej; López-Ortiz, Alejandro; Raman, Venkatesh; Viola, Alfredo (eds.). Space-Efficient Data Structures, Streams, and Algorithms – Papers in Honor of J. Ian Munro on the Occasion of His 66th Birthday. Lecture Notes in Computer Science. Vol. 8066. Springer. pp. 150–163. doi:10.1007/978-3-642-40273-9_11.
- 1 2 3 4 Kleinberg, Jon; Tardos, Éva (2006). "13.5 Randomized divide and conquer: median-finding and quicksort". Algorithm Design. Addison-Wesley. pp. 727–734. ISBN 9780321295354.
- ↑ For instance, Cormen et al. use an in-place array partition, while Kleinberg and Tardos describe the input as a set and use a method that partitions it into two new sets.
- 1 2 3 4 Goodrich, Michael T.; Tamassia, Roberto (2015). "9.2: Selection". Algorithm Design and Applications. Wiley. pp. 270–275. ISBN 978-1-118-33591-8.
- ↑ Devroye, Luc (1984). "Exponential bounds for the running time of a selection algorithm" (PDF). Journal of Computer and System Sciences. 29 (1): 1–7. doi:10.1016/0022-0000(84)90009-6. MR 0761047. Devroye, Luc (2001). "On the probabilistic worst-case time of 'find'" (PDF). Algorithmica. 31 (3): 291–303. doi:10.1007/s00453-001-0046-2. MR 1855252. S2CID 674040.
- 1 2 Floyd, Robert W.; Rivest, Ronald L. (March 1975). "Expected time bounds for selection". Communications of the ACM. 18 (3): 165–172. doi:10.1145/360680.360691. S2CID 3064709. See also "Algorithm 489: the algorithm SELECT—for finding the th smallest of elements", p. 173, doi:10.1145/360680.360694.
- ↑ Brown, Theodore (September 1976). "Remark on Algorithm 489". ACM Transactions on Mathematical Software. 2 (3): 301–304. doi:10.1145/355694.355704. S2CID 13985011.
- ↑ Postmus, J. T.; Rinnooy Kan, A. H. G.; Timmer, G. T. (1983). "An efficient dynamic selection method". Communications of the ACM. 26 (11): 878–881. doi:10.1145/182.358440. MR 0784120. S2CID 3211474.
- 1 2 3 4 5 6 Knuth, Donald E. (1998). "Section 5.3.3: Minimum-comparison selection". The Art of Computer Programming, Volume 3: Sorting and Searching (2nd ed.). Addison-Wesley. pp. 207–219. ISBN 0-201-89685-0.
- ↑ Karloff, Howard J.; Raghavan, Prabhakar (1993). "Randomized algorithms and pseudorandom numbers". Journal of the ACM. 40 (3): 454–476. doi:10.1145/174130.174132. MR 1370358. S2CID 17956460.
- ↑ Gurwitz, Chaya (1992). "On teaching median-finding algorithms". IEEE Transactions on Education. 35 (3): 230–232. Bibcode:1992ITEdu..35..230G. doi:10.1109/13.144650.
- ↑ Musser, David R. (August 1997). "Introspective sorting and selection algorithms". Software: Practice and Experience. Wiley. 27 (8): 983–993. doi:10.1002/(sici)1097-024x(199708)27:8<983::aid-spe117>3.0.co;2-#.
- ↑ Schönhage, A.; Paterson, M.; Pippenger, N. (1976). "Finding the median". Journal of Computer and System Sciences. 13 (2): 184–199. doi:10.1016/S0022-0000(76)80029-3. MR 0428794. S2CID 29867292.
- ↑ Dor, Dorit; Zwick, Uri (1999). "Selecting the median". SIAM Journal on Computing. 28 (5): 1722–1758. doi:10.1137/S0097539795288611. MR 1694164. S2CID 2633282.
- ↑ Valiant, Leslie G. (1975). "Parallelism in comparison problems". SIAM Journal on Computing. 4 (3): 348–355. doi:10.1137/0204030. MR 0378467.
- ↑ Ajtai, Miklós; Komlós, János; Steiger, W. L.; Szemerédi, Endre (1989). "Optimal parallel selection has complexity ". Journal of Computer and System Sciences. 38 (1): 125–133. doi:10.1016/0022-0000(89)90035-4. MR 0990052.
- ↑ Azar, Yossi; Pippenger, Nicholas (1990). "Parallel selection". Discrete Applied Mathematics. 27 (1–2): 49–58. doi:10.1016/0166-218X(90)90128-Y. MR 1055590.
- ↑ Reischuk, Rüdiger (1985). "Probabilistic parallel algorithms for sorting and selection". SIAM Journal on Computing. 14 (2): 396–409. doi:10.1137/0214030. MR 0784745.
- ↑ Han, Yijie (2007). "Optimal parallel selection". ACM Transactions on Algorithms. 3 (4): A38:1–A38:11. doi:10.1145/1290672.1290675. MR 2364962. S2CID 9645870.
- ↑ Chaudhuri, Shiva; Hagerup, Torben; Raman, Rajeev (1993). "Approximate and exact deterministic parallel selection". In Borzyszkowski, Andrzej M.; Sokolowski, Stefan (eds.). Mathematical Foundations of Computer Science 1993, 18th International Symposium, MFCS'93, Gdansk, Poland, August 30 – September 3, 1993, Proceedings. Lecture Notes in Computer Science. Vol. 711. Springer. pp. 352–361. doi:10.1007/3-540-57182-5_27. hdl:11858/00-001M-0000-0014-B748-C.
- ↑ Dietz, Paul F.; Raman, Rajeev (1999). "Small-rank selection in parallel, with applications to heap construction". Journal of Algorithms. 30 (1): 33–51. doi:10.1006/jagm.1998.0971. MR 1661179.
- 1 2 Frederickson, Greg N.; Johnson, Donald B. (1984). "Generalized selection and ranking: sorted matrices". SIAM Journal on Computing. 13 (1): 14–30. doi:10.1137/0213002. MR 0731024.
- 1 2 3 4 Kaplan, Haim; Kozma, László; Zamir, Or; Zwick, Uri (2019). "Selection from heaps, row-sorted matrices, and using soft heaps". In Fineman, Jeremy T.; Mitzenmacher, Michael (eds.). 2nd Symposium on Simplicity in Algorithms, SOSA 2019, January 8–9, 2019, San Diego, CA, USA. OASIcs. Vol. 69. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. pp. 5:1–5:21. arXiv:1802.07041. doi:10.4230/OASIcs.SOSA.2019.5.
- ↑ Frederickson, Greg N. (1993). "An optimal algorithm for selection in a min-heap". Information and Computation. 104 (2): 197–214. doi:10.1006/inco.1993.1030. MR 1221889.
- ↑ Eppstein, David (1999). "Finding the shortest paths". SIAM Journal on Computing. 28 (2): 652–673. doi:10.1137/S0097539795290477. MR 1634364.
- ↑ Babenko, Maxim; Kolesnichenko, Ignat; Smirnov, Ivan (2019). "Cascade heap: towards time-optimal extractions". Theory of Computing Systems. 63 (4): 637–646. doi:10.1007/s00224-018-9866-1. MR 3942251. S2CID 253740380.
- ↑ Pătraşcu, Mihai; Thorup, Mikkel (2014). "Dynamic integer sets with optimal rank, select, and predecessor search". 55th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2014, Philadelphia, PA, USA, October 18–21, 2014. IEEE Computer Society. pp. 166–175. arXiv:1408.3045. doi:10.1109/FOCS.2014.26.
- ↑ Cormode, Graham; Muthukrishnan, S. (2005). "An improved data stream summary: the count-min sketch and its applications". Journal of Algorithms. 55 (1): 58–75. doi:10.1016/j.jalgor.2003.12.001. MR 2132028.
- ↑ Chan, Timothy M. (2010). "Comparison-based time-space lower bounds for selection". ACM Transactions on Algorithms. 6 (2): A26:1–A26:16. doi:10.1145/1721837.1721842. MR 2675693. S2CID 11742607.
- ↑ Bent, Samuel W.; John, John W. (1985). "Finding the median requires comparisons". In Sedgewick, Robert (ed.). Proceedings of the 17th Annual ACM Symposium on Theory of Computing, May 6–8, 1985, Providence, Rhode Island, USA. Association for Computing Machinery. pp. 213–216. doi:10.1145/22145.22169.
- ↑ Dor, Dorit; Zwick, Uri (2001). "Median selection requires comparisons". SIAM Journal on Discrete Mathematics. 14 (3): 312–325. doi:10.1137/S0895480199353895. MR 1857348.
- ↑ Hadian, Abdollah; Sobel, Milton (May 1969). Selecting the -th largest using binary errorless comparisons (Report). School of Statistics Technical Reports. Vol. 121. University of Minnesota. hdl:11299/199105.
- ↑ Gasarch, William; Kelly, Wayne; Pugh, William (July 1996). "Finding the th largest of for small ". ACM SIGACT News. 27 (2): 88–96. doi:10.1145/235767.235772. S2CID 3133332.
- ↑ "heapq package source code". Python library. Retrieved 2023-08-06.; see also the linked comparison of algorithm performance on best-case data.
- ↑ "mink: Find k smallest elements of array". Matlab R2023a documentation. Mathworks. Retrieved 2023-03-30.
- ↑ Hoare, C. A. R. (July 1961). "Algorithm 65: Find". Communications of the ACM. 4 (7): 321–322. doi:10.1145/366622.366647.
- ↑ Dodgson, Charles L. (1883). Lawn Tennis Tournaments: The True Method of Assigning Prizes with a Proof of the Fallacy of the Present Method. London: Macmillan and Co. See also Wilson, Robin; Moktefi, Amirouche, eds. (2019). "Lawn tennis tournaments". The Mathematical World of Charles L. Dodgson (Lewis Carroll). Oxford University Press. p. 129. ISBN 9780192549013.




