Query optimization is a feature of many relational database management systems and other databases such as NoSQL and graph databases. The query optimizer attempts to determine the most efficient way to execute a given query by considering the possible query plans.[1]
Generally, the query optimizer cannot be accessed directly by users: once queries are submitted to the database server, and parsed by the parser, they are then passed to the query optimizer where optimization occurs.[2][3] However, some database engines allow guiding the query optimizer with hints.
A query is a request for information from a database. It can be as simple as "find the address of a person with Social Security number 123-45-6789," or more complex like "find the average salary of all the employed married men in California between the ages 30 to 39 who earn less than their spouses." The result of a query is generated by processing the rows in a database in a way that yields the requested information. Since database structures are complex, in most cases, and especially for not-very-simple queries, the needed data for a query can be collected from a database by accessing it in different ways, through different data-structures, and in different orders.[4] Each different way typically requires different processing time. Processing times of the same query may have large variance, from a fraction of a second to hours, depending on the chosen method. The purpose of query optimization, which is an automated process, is to find the way to process a given query in minimum time. The large possible variance in time justifies performing query optimization, though finding the exact optimal query plan, among all possibilities, is typically very complex, time-consuming by itself, may be too costly, and often practically impossible. Thus query optimization typically tries to approximate the optimum by comparing several common-sense alternatives to provide in a reasonable time a "good enough" plan which typically does not deviate much from the best possible result.
General considerations
There is a trade-off between the amount of time spent figuring out the best query plan and the quality of the choice; the optimizer may not choose the best answer on its own. Different qualities of database management systems have different ways of balancing these two. Cost-based query optimizers evaluate the resource footprint of various query plans and use this as the basis for plan selection.[5] These assign an estimated "cost" to each possible query plan, and choose the plan with the smallest cost. Costs are used to estimate the runtime cost of evaluating the query, in terms of the number of I/O operations required, CPU path length, amount of disk buffer space, disk storage service time, and interconnect usage between units of parallelism, and other factors determined from the data dictionary. The set of query plans examined is formed by examining the possible access paths (e.g., primary index access, secondary index access, full file scan) and various relational table join techniques (e.g., merge join, hash join, product join). The search space can become quite large depending on the complexity of the SQL query. There are two types of optimization. These consist of logical optimization—which generates a sequence of relational algebra to solve the query—and physical optimization—which is used to determine the means of carrying out each operation.
Implementation
Most query optimizers represent query plans as a tree of "plan nodes". A plan node encapsulates a single operation that is required to execute the query. The nodes are arranged as a tree, in which intermediate results flow from the bottom of the tree to the top. Each node has zero or more child nodes—those are nodes whose output is fed as input to the parent node. For example, a join node will have two child nodes, which represent the two join operands, whereas a sort node would have a single child node (the input to be sorted). The leaves of the tree are nodes which produce results by scanning the disk, for example by performing an index scan or a sequential scan.
Join ordering
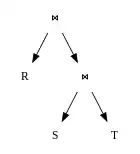
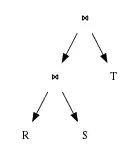
The performance of a query plan is determined largely by the order in which the tables are joined. For example, when joining 3 tables A, B, C of size 10 rows, 10,000 rows, and 1,000,000 rows, respectively, a query plan that joins B and C first can take several orders-of-magnitude more time to execute than one that joins A and C first. Most query optimizers determine join order via a dynamic programming algorithm pioneered by IBM's System R database project . This algorithm works in two stages:
- First, all ways to access each relation in the query are computed. Every relation in the query can be accessed via a sequential scan. If there is an index on a relation that can be used to answer a predicate in the query, an index scan can also be used. For each relation, the optimizer records the cheapest way to scan the relation, as well as the cheapest way to scan the relation that produces records in a particular sorted order.
- The optimizer then considers combining each pair of relations for which a join condition exists. For each pair, the optimizer will consider the available join algorithms implemented by the DBMS. It will preserve the cheapest way to join each pair of relations, in addition to the cheapest way to join each pair of relations that produces its output according to a particular sort order.
- Then all three-relation query plans are computed, by joining each two-relation plan produced by the previous phase with the remaining relations in the query.
Sort order can avoid a redundant sort operation later on in processing the query. Second, a particular sort order can speed up a subsequent join because it clusters the data in a particular way.
Query planning for nested SQL queries
A SQL query to a modern relational DBMS does more than just selections and joins. In particular, SQL queries often nest several layers of SPJ blocks (Select-Project-Join), by means of group by, exists, and not exists operators. In some cases such nested SQL queries can be flattened into a select-project-join query, but not always. Query plans for nested SQL queries can also be chosen using the same dynamic programming algorithm as used for join ordering, but this can lead to an enormous escalation in query optimization time. So some database management systems use an alternative rule-based approach that uses a query graph model.[6]
Cost estimation
One of the hardest problems in query optimization is to accurately estimate the costs of alternative query plans. Optimizers cost query plans using a mathematical model of query execution costs that relies heavily on estimates of the cardinality, or number of tuples, flowing through each edge in a query plan. Cardinality estimation in turn depends on estimates of the selection factor of predicates in the query. Traditionally, database systems estimate selectivities through fairly detailed statistics on the distribution of values in each column, such as histograms. This technique works well for estimation of selectivities of individual predicates.
However many queries have conjunctions of predicates such as select count(*) from R where R.make='Honda' and R.model='Accord'.
Query predicates are often highly correlated (for example, model='Accord' implies make='Honda'), and it is very hard to estimate the selectivity of the conjunct in general. Poor cardinality estimates and uncaught correlation are one of the main reasons why query optimizers pick poor query plans. This is one reason why a database administrator should regularly update the database statistics, especially after major data loads/unloads.
Extensions
Classical query optimization assumes that query plans are compared according to one single cost metric, usually execution time, and that the cost of each query plan can be calculated without uncertainty. Both assumptions are sometimes violated in practice[7] and multiple extensions of classical query optimization have been studied in the research literature that overcome those limitations. Those extended problem variants differ in how they model the cost of single query plans and in terms of their optimization goal.
Parametric query optimization
Classical query optimization associates each query plan with one scalar cost value. Parametric query optimization[8] assumes that query plan cost depends on parameters whose values are unknown at optimization time. Such parameters can for instance represent the selectivity of query predicates that are not fully specified at optimization time but will be provided at execution time. Parametric query optimization therefore associates each query plan with a cost function that maps from a multi-dimensional parameter space to a one-dimensional cost space.
The goal of optimization is usually to generate all query plans that could be optimal for any of the possible parameter value combinations. This yields a set of relevant query plans. At run time, the best plan is selected out of that set once the true parameter values become known. The advantage of parametric query optimization is that optimization (which is in general a very expensive operation) is avoided at run time.
Multi-objective query optimization
There are often other cost metrics in addition to execution time that are relevant to compare query plans. In a cloud computing scenario for instance, one should compare query plans not only in terms of how much time they take to execute but also in terms of how much money their execution costs. Or in the context of approximate query optimization, it is possible to execute query plans on randomly selected samples of the input data in order to obtain approximate results with reduced execution overhead. In such cases, alternative query plans must be compared in terms of their execution time but also in terms of the precision or reliability of the data they generate.
Multi-objective query optimization[9] models the cost of a query plan as a cost vector where each vector component represents cost according to a different cost metric. Classical query optimization can be considered as a special case of multi-objective query optimization where the dimension of the cost space (i.e., the number of cost vector components) is one.
Different cost metrics might conflict with each other (e.g., there might be one plan with minimal execution time and a different plan with minimal monetary execution fees in a cloud computing scenario). Therefore, the goal of optimization cannot be to find a query plan that minimizes all cost metrics but must be to find a query plan that realizes the best compromise between different cost metrics. What the best compromise is depends on user preferences (e.g., some users might prefer a cheaper plan while others prefer a faster plan in a cloud scenario). The goal of optimization is therefore either to find the best query plan based on some specification of user preferences provided as input to the optimizer (e.g., users can define weights between different cost metrics to express relative importance or define hard cost bounds on certain metrics) or to generate an approximation of the set of Pareto-optimal query plans (i.e., plans such that no other plan has better cost according to all metrics) such that the user can select the preferred cost tradeoff out of that plan set.
Multi-objective parametric query optimization
Multi-objective parametric query optimization[7] generalizes parametric and multi-objective query optimization. Plans are compared according to multiple cost metrics and plan costs may depend on parameters whose values are unknown at optimization time. The cost of a query plan is therefore modeled as a function from a multi-dimensional parameter space to a multi-dimensional cost space. The goal of optimization is to generate the set of query plans that can be optimal for each possible combination of parameter values and user preferences.
A number of tools display query execution plans to show which operations have the highest processing cost. Microsoft SMS, ApexSQLPlan, Hana, and Tableau are some examples. Fixing these issues found in these plans can shave tens of percent execution time, and in some cases can cut two-dimensional searches to linear ones.
One of the primary and simplest optimization checklists is to use operations that most RDMS are designed to execute efficiently. See Sargable.
See also
References
- ↑ "IBM Knowledge Center". www.ibm.com.
- ↑ Ioannidis, Yannis (March 1996). "Query optimization". ACM Computing Surveys. 28 (1): 121–123. doi:10.1145/234313.234367. S2CID 47190708.
- ↑ Chaudhuri, Surajit (1998). "An Overview of Query Optimization in Relational Systems". Proceedings of the ACM Symposium on Principles of Database Systems. pp. 34–43. doi:10.1145/275487.275492.
- ↑ Selinger, P. G.; Astrahan, M. M.; Chamberlin, D. D.; Lorie, R. A.; Price, T. G. (1979). "Access Path Selection in a Relational Database Management System". Proceedings of the 1979 ACM SIGMOD International Conference on Management of Data. pp. 23–34. doi:10.1145/582095.582099. ISBN 089791001X.
- ↑ "Oracle SQL cost based optimization". www.dba-oracle.com.
- ↑ "EXPLAIN QUERY PLAN". www.sqlite.org.
- 1 2 Trummer, Immanuel; Koch, Christoph (2015). "Multi-Objective Parametric Query Optimization". VLDB: 221–232.
- ↑ Ioannidis, Yannis; Ng, Raymond T.; Shim, Kyuseok; Sellis, Timos K. (1997). "Parametric Query Optimization". VLDB. 6 (2): 132–151. CiteSeerX 10.1.1.33.696. doi:10.1007/s007780050037. S2CID 3060505.
- ↑ Trummer, Immanuel; Koch, Christoph (2014). Approximation Schemes for Many-Objective Query Optimization. SIGMOD. pp. 1299–1310. arXiv:1404.0046.
| Types | |
|---|---|
| Concepts | |
| Objects | |
| Components | |
| Functions | |
| Related topics | |
| |