| Part of a series on Statistics |
| Correlation and covariance |
|---|
 |





In probability theory and statistics, a covariance matrix (also known as auto-covariance matrix, dispersion matrix, variance matrix, or variance–covariance matrix) is a square matrix giving the covariance between each pair of elements of a given random vector.
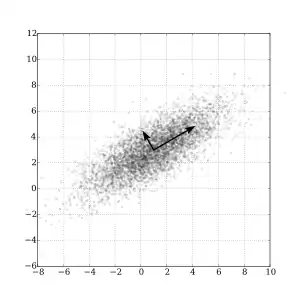
Intuitively, the covariance matrix generalizes the notion of variance to multiple dimensions. As an example, the variation in a collection of random points in two-dimensional space cannot be characterized fully by a single number, nor would the variances in the and directions contain all of the necessary information; a matrix would be necessary to fully characterize the two-dimensional variation.
Any covariance matrix is symmetric and positive semi-definite and its main diagonal contains variances (i.e., the covariance of each element with itself).
The covariance matrix of a random vector is typically denoted by , or .




Definition
Throughout this article, boldfaced unsubscripted and are used to refer to random vectors, and Roman subscripted and are used to refer to scalar random variables.



If the entries in the column vector

are random variables, each with finite variance and expected value, then the covariance matrix is the matrix whose entry is the covariance[1]: p. 177

![{\displaystyle \operatorname {K} _{X_{i}X_{j}}=\operatorname {cov} [X_{i},X_{j}]=\operatorname {E} [(X_{i}-\operatorname {E} [X_{i}])(X_{j}-\operatorname {E} [X_{j}])]}](../I/83bec85f5e2cab5d3406677dd806e554a442331f.svg)
where the operator denotes the expected value (mean) of its argument.

Conflicting nomenclatures and notations
Nomenclatures differ. Some statisticians, following the probabilist William Feller in his two-volume book An Introduction to Probability Theory and Its Applications,[2] call the matrix the variance of the random vector , because it is the natural generalization to higher dimensions of the 1-dimensional variance. Others call it the covariance matrix, because it is the matrix of covariances between the scalar components of the vector .
![{\displaystyle \operatorname {var} (\mathbf {X} )=\operatorname {cov} (\mathbf {X} ,\mathbf {X} )=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\rm {T}}\right].}](../I/92051943c03f3ff5b282d8090e65118c40ca400b.svg)
Both forms are quite standard, and there is no ambiguity between them. The matrix is also often called the variance-covariance matrix, since the diagonal terms are in fact variances.
By comparison, the notation for the cross-covariance matrix between two vectors is
![{\displaystyle \operatorname {cov} (\mathbf {X} ,\mathbf {Y} )=\operatorname {K} _{\mathbf {X} \mathbf {Y} }=\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {Y} -\operatorname {E} [\mathbf {Y} ])^{\rm {T}}\right].}](../I/1112b836c2cd9fde4ac076a44dfdbd213395a56b.svg)
Properties
Relation to the autocorrelation matrix
The auto-covariance matrix is related to the autocorrelation matrix by

![{\displaystyle \operatorname {K} _{\mathbf {X} \mathbf {X} }=\operatorname {E} [(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\rm {T}}]=\operatorname {R} _{\mathbf {X} \mathbf {X} }-\operatorname {E} [\mathbf {X} ]\operatorname {E} [\mathbf {X} ]^{\rm {T}}}](../I/00175de2c055b834a6f012910f7a5a3d1ed96353.svg)
where the autocorrelation matrix is defined as .
![{\displaystyle \operatorname {R} _{\mathbf {X} \mathbf {X} }=\operatorname {E} [\mathbf {X} \mathbf {X} ^{\rm {T}}]}](../I/375369663d22bba80d770f6374289f95dd22cf63.svg)
Relation to the correlation matrix
An entity closely related to the covariance matrix is the matrix of Pearson product-moment correlation coefficients between each of the random variables in the random vector , which can be written as

where is the matrix of the diagonal elements of (i.e., a diagonal matrix of the variances of for ).


Equivalently, the correlation matrix can be seen as the covariance matrix of the standardized random variables for .

![{\displaystyle \operatorname {corr} (\mathbf {X} )={\begin{bmatrix}1&{\frac {\operatorname {E} [(X_{1}-\mu _{1})(X_{2}-\mu _{2})]}{\sigma (X_{1})\sigma (X_{2})}}&\cdots &{\frac {\operatorname {E} [(X_{1}-\mu _{1})(X_{n}-\mu _{n})]}{\sigma (X_{1})\sigma (X_{n})}}\\\\{\frac {\operatorname {E} [(X_{2}-\mu _{2})(X_{1}-\mu _{1})]}{\sigma (X_{2})\sigma (X_{1})}}&1&\cdots &{\frac {\operatorname {E} [(X_{2}-\mu _{2})(X_{n}-\mu _{n})]}{\sigma (X_{2})\sigma (X_{n})}}\\\\\vdots &\vdots &\ddots &\vdots \\\\{\frac {\operatorname {E} [(X_{n}-\mu _{n})(X_{1}-\mu _{1})]}{\sigma (X_{n})\sigma (X_{1})}}&{\frac {\operatorname {E} [(X_{n}-\mu _{n})(X_{2}-\mu _{2})]}{\sigma (X_{n})\sigma (X_{2})}}&\cdots &1\end{bmatrix}}.}](../I/df091a047aa8a9d829b25f68a5bbe6d56938b146.svg)
Each element on the principal diagonal of a correlation matrix is the correlation of a random variable with itself, which always equals 1. Each off-diagonal element is between −1 and +1 inclusive.
Inverse of the covariance matrix
The inverse of this matrix, , if it exists, is the inverse covariance matrix (or inverse concentration matrix), also known as the precision matrix (or concentration matrix).[3]

Just as the covariance matrix can be written as the rescaling of a correlation matrix by the marginal variances:

So, using the idea of partial correlation, and partial variance, the inverse covariance matrix can be expressed analogously:

This duality motivates a number of other dualities between marginalizing and conditioning for gaussian random variables.
Basic properties
For and , where is a -dimensional random variable, the following basic properties apply:[4]
![{\displaystyle \operatorname {K} _{\mathbf {X} \mathbf {X} }=\operatorname {var} (\mathbf {X} )=\operatorname {E} \left[\left(\mathbf {X} -\operatorname {E} [\mathbf {X} ]\right)\left(\mathbf {X} -\operatorname {E} [\mathbf {X} ]\right)^{\rm {T}}\right]}](../I/bed55fb51d1aad5b83b37076bdbd9ad0177a813b.svg)
![{\displaystyle \mathbf {\mu _{X}} =\operatorname {E} [{\textbf {X}}]}](../I/25987aa171cbd6ec023a92eb06b6ee750de39309.svg)


- is positive-semidefinite, i.e.
- is symmetric, i.e.
- For any constant (i.e. non-random) matrix and constant vector , one has
- If is another random vector with the same dimension as , then where is the cross-covariance matrix of and .











Block matrices
The joint mean and joint covariance matrix of and can be written in block form



where , and .



and can be identified as the variance matrices of the marginal distributions for and respectively.


If and are jointly normally distributed,

then the conditional distribution for given is given by

defined by conditional mean


The matrix is known as the matrix of regression coefficients, while in linear algebra is the Schur complement of in .


The matrix of regression coefficients may often be given in transpose form, , suitable for post-multiplying a row vector of explanatory variables rather than pre-multiplying a column vector . In this form they correspond to the coefficients obtained by inverting the matrix of the normal equations of ordinary least squares (OLS).


Partial covariance matrix
A covariance matrix with all non-zero elements tells us that all the individual random variables are interrelated. This means that the variables are not only directly correlated, but also correlated via other variables indirectly. Often such indirect, common-mode correlations are trivial and uninteresting. They can be suppressed by calculating the partial covariance matrix, that is the part of covariance matrix that shows only the interesting part of correlations.
If two vectors of random variables and are correlated via another vector , the latter correlations are suppressed in a matrix[6]


The partial covariance matrix is effectively the simple covariance matrix as if the uninteresting random variables were held constant.


Covariance matrix as a parameter of a distribution
If a column vector of possibly correlated random variables is jointly normally distributed, or more generally elliptically distributed, then its probability density function can be expressed in terms of the covariance matrix as follows[6]


where and is the determinant of .
![{\displaystyle \mathbf {\mu =\operatorname {E} [X]} }](../I/d9c821aa85a1cbc2edfffb9343c51c7cd3541b34.svg)

Covariance matrix as a linear operator
Applied to one vector, the covariance matrix maps a linear combination c of the random variables X onto a vector of covariances with those variables: . Treated as a bilinear form, it yields the covariance between the two linear combinations: . The variance of a linear combination is then , its covariance with itself.



Similarly, the (pseudo-)inverse covariance matrix provides an inner product , which induces the Mahalanobis distance, a measure of the "unlikelihood" of c.

Which matrices are covariance matrices?
From the identity just above, let be a real-valued vector, then



which must always be nonnegative, since it is the variance of a real-valued random variable, so a covariance matrix is always a positive-semidefinite matrix.
The above argument can be expanded as follows:
![{\displaystyle {\begin{aligned}&w^{\rm {T}}\operatorname {E} \left[(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\rm {T}}\right]w=\operatorname {E} \left[w^{\rm {T}}(\mathbf {X} -\operatorname {E} [\mathbf {X} ])(\mathbf {X} -\operatorname {E} [\mathbf {X} ])^{\rm {T}}w\right]\\&=\operatorname {E} {\big [}{\big (}w^{\rm {T}}(\mathbf {X} -\operatorname {E} [\mathbf {X} ]){\big )}^{2}{\big ]}\geq 0,\end{aligned}}}](../I/4c9fb5265a1f97a7cc67b23c9942182f63051a73.svg)
where the last inequality follows from the observation that is a scalar.
![{\displaystyle w^{\rm {T}}(\mathbf {X} -\operatorname {E} [\mathbf {X} ])}](../I/127bb7293f5d9738d76b0c9461d4236befd8dccb.svg)
Conversely, every symmetric positive semi-definite matrix is a covariance matrix. To see this, suppose is a symmetric positive-semidefinite matrix. From the finite-dimensional case of the spectral theorem, it follows that has a nonnegative symmetric square root, which can be denoted by M1/2. Let be any column vector-valued random variable whose covariance matrix is the identity matrix. Then




Complex random vectors
The variance of a complex scalar-valued random variable with expected value is conventionally defined using complex conjugation:

![{\displaystyle \operatorname {var} (Z)=\operatorname {E} \left[(Z-\mu _{Z}){\overline {(Z-\mu _{Z})}}\right],}](../I/b3a3d7abfa56fdb689ebd3c01388715ad4773d4a.svg)
where the complex conjugate of a complex number is denoted ; thus the variance of a complex random variable is a real number.


If is a column vector of complex-valued random variables, then the conjugate transpose is formed by both transposing and conjugating. In the following expression, the product of a vector with its conjugate transpose results in a square matrix called the covariance matrix, as its expectation:[7]: p. 293


- ,
![{\displaystyle \operatorname {K} _{\mathbf {Z} \mathbf {Z} }=\operatorname {cov} [\mathbf {Z} ,\mathbf {Z} ]=\operatorname {E} \left[(\mathbf {Z} -\mathbf {\mu _{Z}} )(\mathbf {Z} -\mathbf {\mu _{Z}} )^{\mathrm {H} }\right]}](../I/88c60e556c5e5f705d6448f79339174ec62b1ffd.svg)
The matrix so obtained will be Hermitian positive-semidefinite,[8] with real numbers in the main diagonal and complex numbers off-diagonal.
- Properties
- The covariance matrix is a Hermitian matrix, i.e. .[1]: p. 179
- The diagonal elements of the covariance matrix are real.[1]: p. 179

Pseudo-covariance matrix
For complex random vectors, another kind of second central moment, the pseudo-covariance matrix (also called relation matrix) is defined as follows:
![{\displaystyle \operatorname {J} _{\mathbf {Z} \mathbf {Z} }=\operatorname {cov} [\mathbf {Z} ,{\overline {\mathbf {Z} }}]=\operatorname {E} \left[(\mathbf {Z} -\mathbf {\mu _{Z}} )(\mathbf {Z} -\mathbf {\mu _{Z}} )^{\mathrm {T} }\right]}](../I/bba62bd04d95107abdaa72eb5b505496ad4151ea.svg)
In contrast to the covariance matrix defined above, Hermitian transposition gets replaced by transposition in the definition. Its diagonal elements may be complex valued; it is a complex symmetric matrix.
Estimation
If and are centred data matrices of dimension and respectively, i.e. with n columns of observations of p and q rows of variables, from which the row means have been subtracted, then, if the row means were estimated from the data, sample covariance matrices and can be defined to be







or, if the row means were known a priori,

These empirical sample covariance matrices are the most straightforward and most often used estimators for the covariance matrices, but other estimators also exist, including regularised or shrinkage estimators, which may have better properties.
Applications
The covariance matrix is a useful tool in many different areas. From it a transformation matrix can be derived, called a whitening transformation, that allows one to completely decorrelate the data or, from a different point of view, to find an optimal basis for representing the data in a compact way (see Rayleigh quotient for a formal proof and additional properties of covariance matrices). This is called principal component analysis (PCA) and the Karhunen–Loève transform (KL-transform).
The covariance matrix plays a key role in financial economics, especially in portfolio theory and its mutual fund separation theorem and in the capital asset pricing model. The matrix of covariances among various assets' returns is used to determine, under certain assumptions, the relative amounts of different assets that investors should (in a normative analysis) or are predicted to (in a positive analysis) choose to hold in a context of diversification.
Use in optimization
The evolution strategy, a particular family of Randomized Search Heuristics, fundamentally relies on a covariance matrix in its mechanism. The characteristic mutation operator draws the update step from a multivariate normal distribution using an evolving covariance matrix. There is a formal proof that the evolution strategy's covariance matrix adapts to the inverse of the Hessian matrix of the search landscape, up to a scalar factor and small random fluctuations (proven for a single-parent strategy and a static model, as the population size increases, relying on the quadratic approximation).[9] Intuitively, this result is supported by the rationale that the optimal covariance distribution can offer mutation steps whose equidensity probability contours match the level sets of the landscape, and so they maximize the progress rate.
Covariance mapping
In covariance mapping the values of the or matrix are plotted as a 2-dimensional map. When vectors and are discrete random functions, the map shows statistical relations between different regions of the random functions. Statistically independent regions of the functions show up on the map as zero-level flatland, while positive or negative correlations show up, respectively, as hills or valleys.

In practice the column vectors , and are acquired experimentally as rows of samples, e.g.

![{\displaystyle [\mathbf {X} _{1},\mathbf {X} _{2},...\mathbf {X} _{n}]={\begin{bmatrix}X_{1}(t_{1})&X_{2}(t_{1})&\cdots &X_{n}(t_{1})\\\\X_{1}(t_{2})&X_{2}(t_{2})&\cdots &X_{n}(t_{2})\\\\\vdots &\vdots &\ddots &\vdots \\\\X_{1}(t_{m})&X_{2}(t_{m})&\cdots &X_{n}(t_{m})\end{bmatrix}},}](../I/be824f93648e01daa17bd4e9d99b4398026b0149.svg)
where is the i-th discrete value in sample j of the random function . The expected values needed in the covariance formula are estimated using the sample mean, e.g.



and the covariance matrix is estimated by the sample covariance matrix

where the angular brackets denote sample averaging as before except that the Bessel's correction should be made to avoid bias. Using this estimation the partial covariance matrix can be calculated as

where the backslash denotes the left matrix division operator, which bypasses the requirement to invert a matrix and is available in some computational packages such as Matlab.[10]

Fig. 1 illustrates how a partial covariance map is constructed on an example of an experiment performed at the FLASH free-electron laser in Hamburg.[11] The random function is the time-of-flight spectrum of ions from a Coulomb explosion of nitrogen molecules multiply ionised by a laser pulse. Since only a few hundreds of molecules are ionised at each laser pulse, the single-shot spectra are highly fluctuating. However, collecting typically such spectra, , and averaging them over produces a smooth spectrum , which is shown in red at the bottom of Fig. 1. The average spectrum reveals several nitrogen ions in a form of peaks broadened by their kinetic energy, but to find the correlations between the ionisation stages and the ion momenta requires calculating a covariance map.





In the example of Fig. 1 spectra and are the same, except that the range of the time-of-flight differs. Panel a shows , panel b shows and panel c shows their difference, which is (note a change in the colour scale). Unfortunately, this map is overwhelmed by uninteresting, common-mode correlations induced by laser intensity fluctuating from shot to shot. To suppress such correlations the laser intensity is recorded at every shot, put into and is calculated as panels d and e show. The suppression of the uninteresting correlations is, however, imperfect because there are other sources of common-mode fluctuations than the laser intensity and in principle all these sources should be monitored in vector . Yet in practice it is often sufficient to overcompensate the partial covariance correction as panel f shows, where interesting correlations of ion momenta are now clearly visible as straight lines centred on ionisation stages of atomic nitrogen.





Two-dimensional infrared spectroscopy
Two-dimensional infrared spectroscopy employs correlation analysis to obtain 2D spectra of the condensed phase. There are two versions of this analysis: synchronous and asynchronous. Mathematically, the former is expressed in terms of the sample covariance matrix and the technique is equivalent to covariance mapping.[12]
See also
References
- 1 2 3 Park,Kun Il (2018). Fundamentals of Probability and Stochastic Processes with Applications to Communications. Springer. ISBN 978-3-319-68074-3.
- ↑ William Feller (1971). An introduction to probability theory and its applications. Wiley. ISBN 978-0-471-25709-7. Retrieved 10 August 2012.
- ↑ Wasserman, Larry (2004). All of Statistics: A Concise Course in Statistical Inference. Springer. ISBN 0-387-40272-1.
- ↑ Taboga, Marco (2010). "Lectures on probability theory and mathematical statistics".
- ↑ Eaton, Morris L. (1983). Multivariate Statistics: a Vector Space Approach. John Wiley and Sons. pp. 116–117. ISBN 0-471-02776-6.
- 1 2 W J Krzanowski "Principles of Multivariate Analysis" (Oxford University Press, New York, 1988), Chap. 14.4; K V Mardia, J T Kent and J M Bibby "Multivariate Analysis (Academic Press, London, 1997), Chap. 6.5.3; T W Anderson "An Introduction to Multivariate Statistical Analysis" (Wiley, New York, 2003), 3rd ed., Chaps. 2.5.1 and 4.3.1.
- ↑ Lapidoth, Amos (2009). A Foundation in Digital Communication. Cambridge University Press. ISBN 978-0-521-19395-5.
- ↑ Brookes, Mike. "The Matrix Reference Manual".
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Shir, O.M.; A. Yehudayoff (2020). "On the covariance-Hessian relation in evolution strategies". Theoretical Computer Science. Elsevier. 801: 157–174. arXiv:1806.03674. doi:10.1016/j.tcs.2019.09.002.
- ↑ L J Frasinski "Covariance mapping techniques" J. Phys. B: At. Mol. Opt. Phys. 49 152004 (2016), open access
- 1 2 O Kornilov, M Eckstein, M Rosenblatt, C P Schulz, K Motomura, A Rouzée, J Klei, L Foucar, M Siano, A Lübcke, F. Schapper, P Johnsson, D M P Holland, T Schlatholter, T Marchenko, S Düsterer, K Ueda, M J J Vrakking and L J Frasinski "Coulomb explosion of diatomic molecules in intense XUV fields mapped by partial covariance" J. Phys. B: At. Mol. Opt. Phys. 46 164028 (2013), open access
- ↑ I Noda "Generalized two-dimensional correlation method applicable to infrared, Raman, and other types of spectroscopy" Appl. Spectrosc. 47 1329–36 (1993)
Further reading
- "Covariance matrix", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- "Covariance Matrix Explained With Pictures", an easy way to visualize covariance matrices!
- Weisstein, Eric W. "Covariance Matrix". MathWorld.
- van Kampen, N. G. (1981). Stochastic processes in physics and chemistry. New York: North-Holland. ISBN 0-444-86200-5.
Matrix classes | |
|---|---|
| Explicitly constrained entries |
|
| Constant | |
| Conditions on eigenvalues or eigenvectors | |
| Satisfying conditions on products or inverses | |
| With specific applications |
|
| Used in statistics | |
| Used in graph theory | |
| Used in science and engineering | |
| Related terms | |
| |