快速排序
快速排序(英語:),又稱分区交換排序(),是一種排序演算法,最早由東尼·霍爾提出。在平均狀況下,排序個項目要(大O符号)次比較。在最壞狀況下則需要次比較,但這種狀況並不常見。事實上,快速排序通常明顯比其他演算法更快,因為它的內部循环可以在大部分的架構上很有效率地達成。




| 快速排序 | |
|---|---|
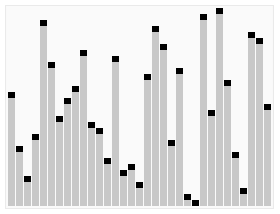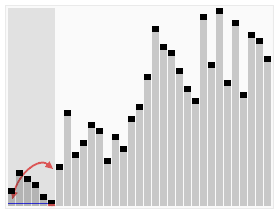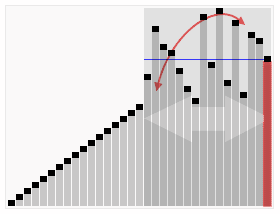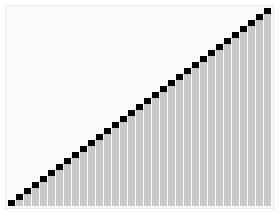 使用快速排序法對一列數字進行排序的過程 | |
| 概况 | |
| 類別 | 排序算法 |
| 資料結構 | 不定 |
| 复杂度 | |
| 平均時間複雜度 | |
| 最坏时间复杂度 | |
| 最优时间复杂度 | |
| 空間複雜度 | 根據實現的方式不同而不同 |
| 最佳解 | 有时是 |
| 相关变量的定义 | |

演算法
快速排序使用分治法策略來把一個序列分為较小和较大的2个子序列,然后递归地排序两个子序列。
步驟為:
- 挑选基准值:從數列中挑出一個元素,稱為「基準」(pivot),
- 分割:重新排序數列,所有比基準值小的元素擺放在基準前面,所有比基準值大的元素擺在基準後面(与基准值相等的數可以到任何一邊)。在這個分割結束之後,对基准值的排序就已经完成,
- 递归排序子序列:递归地将小於基准值元素的子序列和大於基准值元素的子序列排序。
递归到最底部的判断条件是數列的大小是零或一,此时该数列显然已经有序。
选取基准值有数种具体方法,此选取方法对排序的时间性能有决定性影响。
在简单的伪代码中,此算法可以被表示为:
function quicksort(q)
{
var list less, pivotList, greater
if length(q) ≤ 1
return q
else
{
select a pivot value pivot from q
for each x in q except the pivot element
{
if x < pivot then add x to less
if x ≥ pivot then add x to greater
}
add pivot to pivotList
return concatenate(quicksort(less), pivotList, quicksort(greater))
}
}
原地(in-place)分割的版本

上面簡單版本的缺點是,它需要的額外儲存空間,也就跟归并排序一樣不好。額外需要的記憶體空間配置,在實際上的實作,也會極度影響速度和快取的效能。有一個比較複雜使用原地(in-place)分割算法的版本,且在好的基準選擇上,平均可以達到空間的使用複雜度。


function partition(a, left, right, pivotIndex)
{
pivotValue = a[pivotIndex]
swap(a[pivotIndex], a[right]) // 把pivot移到結尾
storeIndex = left
for i from left to right-1
{
if a[i] < pivotValue
{
swap(a[storeIndex], a[i])
storeIndex = storeIndex + 1
}
}
swap(a[right], a[storeIndex]) // 把pivot移到它最後的地方
return storeIndex
}
這是原地分割演算法,它分割了標示為"左邊(left)"和"右邊(right)"的序列部份,藉由移動小於a[pivotIndex]的所有元素到子序列的開頭,留下所有大於或等於的元素接在他們後面。在這個過程它也為基準元素找尋最後擺放的位置,也就是它回傳的值。它暫時地把基準元素移到子序列的結尾,而不會被前述方式影響到。由於演算法只使用交換,因此最後的數列與原先的數列擁有一樣的元素。要注意的是,一個元素在到達它的最後位置前,可能會被交換很多次。
一旦我們有了這個分割演算法,要寫快速排列本身就很容易:
procedure quicksort(a, left, right)
if right > left
select a pivot value a[pivotIndex]
pivotNewIndex := partition(a, left, right, pivotIndex)
quicksort(a, left, pivotNewIndex-1)
quicksort(a, pivotNewIndex+1, right)
這個版本經常會被使用在命令式語言中,像是C語言。
优化的排序演算法
快速排序是二叉查找树(二元搜尋樹)的一個空間最佳化版本。不是循序地把数据项插入到一個明確的樹中,而是由快速排序組織這些数据項到一個由递归调用所隐含的樹中。這兩個演算法完全地產生相同的比較次數,但是順序不同。对于排序算法的稳定性指标,原地分割版本的快速排序算法是不稳定的。其他变种是可以通过牺牲性能和空间来维护稳定性的。
快速排序的最直接競爭者是堆排序。堆排序通常比快速排序稍微慢,但是最壞情況的執行時間總是。快速排序是經常比較快,除了introsort變化版本外,仍然有最壞情況效能的機會。如果事先知道堆排序將會是需要使用的,那麼直接地使用堆排序比等待introsort再切換到它還要快。堆排序也擁有重要的特點,僅使用固定額外的空間(堆排序是原地排序),而即使是最佳的快速排序變化版本也需要的空間。然而,堆排序需要有效率的隨機存取才能變成可行。


快速排序也與归并排序競爭,這是另外一種遞迴排序算法,但有壞情況執行時間的優勢。不像快速排序或堆排序,归并排序是一個穩定排序,且可以輕易地被採用在链表和儲存在慢速存取媒體上像是磁碟儲存或網路連接儲存的非常巨大數列。儘管快速排序可以被重新改寫使用在链串列上,但是它通常會因為無法隨機存取而導致差的基準選擇。归并排序的主要缺點,是在最佳情況下需要額外的空間。
正規分析
從一開始快速排序平均需要花費時間的描述並不明顯。但是不難觀察到的是分割運算,陣列的元素都會在每次迴圈中走訪過一次,使用的時間。在使用結合(concatenation)的版本中,這項運算也是。

在最好的情況,每次我們執行一次分割,我們會把一個數列分為兩個幾近相等的片段。這個意思就是每次遞迴调用處理一半大小的數列。因此,在到達大小為一的數列前,我們只要作次巢狀的调用。這個意思就是调用樹的深度是。但是在同一階層的兩個程序调用中,不會處理到原來數列的相同部份;因此,程序调用的每一階層總共全部僅需要的時間(每個调用有某些共同的額外耗費,但是因為在每一階層僅僅只有個调用,這些被歸納在係數中)。結果是這個演算法僅需使用時間。

另外一個方法是為設立一個遞迴關係式,也就是需要排序大小為的數列所需要的時間。在最好的情況下,因為一個單獨的快速排序调用牽涉了的工作,加上對大小之數列的兩個遞迴调用,這個關係式可以是:



解決這種關係式型態的標準数学归纳法技巧告訴我們。

事實上,並不需要把數列如此精確地分割;即使如果每個基準值將元素分開為99%在一邊和1%在另一邊,调用的深度仍然限制在,所以全部執行時間依然是。

然而,在最壞的情況是,兩子數列擁有大各為 和,且调用樹(call tree)變成為一個個巢狀(nested)呼叫的線性連串(chain)。第 次呼叫作了的工作量,且遞迴關係式為:







亂數快速排序的期望複雜度
亂數快速排序有一個值得注意的特性,在任意輸入資料的狀況下,它只需要的期望時間。是什麼讓隨機的基準變成一個好的選擇?
假設我們排序一個數列,然後把它分為四個部份。在中央的兩個部份將會包含最好的基準值;他們的每一個至少都會比25%的元素大,且至少比25%的元素小。如果我們可以一致地從這兩個中央的部份選出一個元素,在到達大小為1的數列前,我們可能最多僅需要把數列分割次,產生一個演算法。

不幸地,亂數選擇只有一半的時間會從中間的部份選擇。出人意外的事實是這樣就已經足夠好了。想像你正在翻轉一枚硬幣,一直翻轉一直到有次人頭那面出現。儘管這需要很長的時間,平均來說只需要次翻動。且在次翻動中得不到次人頭那面的機會,是像天文數字一樣的非常小。藉由同樣的論證,快速排序的遞迴平均只要的呼叫深度就會終止。但是如果它的平均呼叫深度是且每一階的呼叫樹狀過程最多有個元素,則全部完成的工作量平均上是乘積,也就是。



平均複雜度
即使如果我們無法隨機地選擇基準數值,對於它的輸入之所有可能排列,快速排序仍然只需要時間。因為這個平均是簡單地將輸入之所有可能排列的時間加總起來,除以這個因數,相當於從輸入之中選擇一個隨機的排列。當我們這樣作,基準值本質上就是隨機的,導致這個演算法與亂數快速排序有一樣的執行時間。
更精確地說,對於輸入順序之所有排列情形的平均比較次數,可以藉由解出這個遞迴關係式可以精確地算出來。
。

在這裡,是分割所使用的比較次數。因為基準值是相當均勻地落在排列好的數列次序之任何地方,總和就是所有可能分割的平均。
這個意思是,平均上快速排序比理想的比較次數,也就是最好情況下,只大約比較糟39%。這意味著,它比最壞情況較接近最好情況。這個快速的平均執行時間,是快速排序比其他排序演算法有實際的優勢之另一個原因。
空間複雜度
被快速排序所使用的空間,依照使用的版本而定。使用原地(in-place)分割的快速排序版本,在任何遞迴呼叫前,僅會使用固定的額外空間。然而,如果需要產生巢狀遞迴呼叫,它需要在他們每一個儲存一個固定數量的資訊。因為最好的情況最多需要次的巢狀遞迴呼叫,所以它需要的空間。最壞情況下需要次巢狀遞迴呼叫,因此需要的空間。
然而我們在這裡省略一些小的細節。如果我們考慮排序任意很長的數列,我們必須要記住我們的變數像是left和right,不再被認為是佔據固定的空間;也需要對原來一個項的數列作索引。因為我們在每一個堆疊框架中都有像這些的變數,實際上快速排序在最好跟平均的情況下,需要空間的位元數,以及最壞情況下的空間。然而,這並不會太可怕,因為如果一個數列大部份都是不同的元素,那麼數列本身也會佔據的空間位元組。

非原地版本的快速排序,在它的任何遞迴呼叫前需要使用空間。在最好的情況下,它的空間仍然限制在,因為遞迴的每一階中,使用與上一次所使用最多空間的一半,且
- 。

它的最壞情況是很恐怖的,需要

空間,遠比數列本身還多。如果這些數列元素本身自己不是固定的大小,這個問題會變得更大;舉例來說,如果數列元素的大部份都是不同的,每一個將會需要大約為原來儲存,導致最好情況是和最壞情況是的空間需求。

選擇的關連性
選擇算法(selection algorithm)可以選取一個數列的第個最小值;一般而言這是比排序還簡單的問題。一個簡單但是有效率的選擇算法與快速排序的作法相當類似,除了對兩個子數列都作遞迴呼叫外,它僅僅針對包含想要的元素之子數列作單一的結尾遞迴(tail recursive)呼叫。這個小改變降低了平均複雜度到線性或是時間,且讓它成為一個原地算法。這個算法的一種變化版本,可以讓最壞情況下降為(參考選擇算法來得到更多資訊)。

相反地,一旦我們知道一個最壞情況的選擇算法是可以利用的,我們在快速排序的每一步可以用它來找到理想的基準(中位數),得到一種最坏情況下執行時間的變化版本。然而在實際的實作中,這種版本一般而言相當慢。
實作範例
Julia (程式語言)
# Julia Sample : QuickSort
function QuickSort(A)
i,j = 1,length(A)
if j > i
rndv = A[rand(i:j)]
Left,Right = i,j
while Left <= Right
while A[Left] < rndv
Left += 1
end
while A[Right] > rndv
Right -= 1
end
if Left <= Right
A[Left], A[Right] = A[Right], A[Left]
Left += 1
Right -= 1
end
end
quicksort!(A,i,Right)
quicksort!(A,Left,j)
end
return A
end
# Main Code
A = [16,586,1,31,354,43,3]
println(A) # Original Array
println(QuickSort(A)) # Quick Sort Array
參考
- Hoare, C. A. R. "Partition: Algorithm 63," "Quicksort: Algorithm 64," and "Find: Algorithm 65." Comm. ACM 4, 321-322, 1961
- R. Sedgewick. Implementing quicksort programs, Communications of the ACM, 21(10):847-857, 1978.
- David Musser. Introspective Sorting and Selection Algorithms, Software Practice and Experience vol 27, number 8, pages 983-993, 1997
- A. LaMarca and R. E. Ladner. "The Influence of Caches on the Performance of Sorting." Proceedings of the Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, 1997. pp. 370–379.
- Faron Moller. Analysis of Quicksort. CS 332: Designing Algorithms. Department of Computer Science, University of Wales Swansea.
- Steven Skiena. Lecture 5 - quicksort. CSE 373/548 - Analysis of Algorithms. Department of Computer Science. SUNY Stony Brook.
註腳
1. David M. W. Powers. Parallelized Quicksort with Optimal Speedup (页面存档备份,存于). Proceedings of International Conference on Parallel Computing Technologies. Novosibirsk. 1991.