快速选择
在计算机科学中,快速选择(英語:)是一种从无序列表找到第k小元素的选择算法。它从原理上来说与快速排序有关。与快速排序一样都由托尼·霍尔提出的,因而也被称为霍尔选择算法。[1] 同样地,它在实际应用是一种高效的算法,具有很好的平均时间复杂度,然而最坏时间复杂度则不理想。快速选择及其变种是实际应用中最常使用的高效选择算法。
| 快速选择 | |
|---|---|
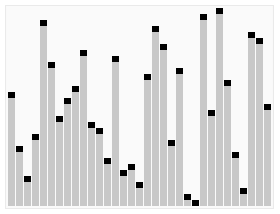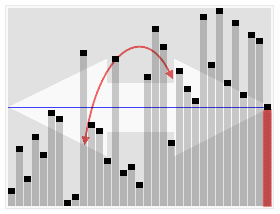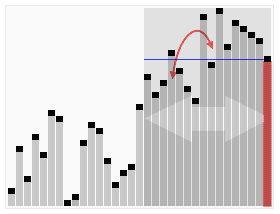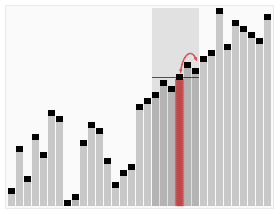 快速选择算法的动画演示:选择第22小的元素。(注意:这和条目中的算法不完全相同) | |
| 概况 | |
| 類別 | 选择算法 |
| 資料結構 | 数组 |
| 复杂度 | |
| 平均時間複雜度 | O(n) |
| 最坏时间复杂度 | О(n2) |
| 最优时间复杂度 | О(n) |
| 空間複雜度 | O(1) |
| 相关变量的定义 | |
快速选择的总体思路与快速排序一致,选择一个元素作为基准来对元素进行分区,将小于和大于基准的元素分在基准左边和右边的两个区域。不同的是,快速选择并不递归访问双边,而是只递归进入一边的元素中继续寻找。这降低了平均时间复杂度,从O(n log n)至O(n),不过最坏情况仍然是O(n2)。
与快速排序一样,快速选择一般是以原地算法的方式实现,除了选出第k小的元素,数据也得到了部分地排序。
算法
快速排序中,有一个子过程称为分区,可以在线性时间里将一个列表分为两部分(left和right),分别是小于基准和大于等于基准的元素。下面是以list[pivotIndex]进行分区的伪代码:
function partition(list, left, right, pivotIndex)
pivotValue := list[pivotIndex]
swap list[pivotIndex] and list[right] // Move pivot to end
storeIndex := left
for i from left to right-1
if list[i] < pivotValue
swap list[storeIndex] and list[i]
increment storeIndex
swap list[right] and list[storeIndex] // Move pivot to its final place
return storeIndex
在快速排序中,我们递归地对两个分支进行排序,导致最佳时间复杂度为O(n log n)。然而,在快速选择中,虽然大部分元素仍是乱序的,但是基准元素已经在最终排序好的位置上,所以我们知道想找的元素在哪个分区中。 因此,一个递归循环分支就能帮助我们定位想找的元素,从而得到快速选择的算法:
// Returns the k-th smallest element of list within left..right inclusive
// (i.e. left <= k <= right).
// The search space within the array is changing for each round - but the list
// is still the same size. Thus, k does not need to be updated with each round.
function select(list, left, right, k)
if left = right // If the list contains only one element,
return list[left] // return that element
pivotIndex := ... // select a pivotIndex between left and right,
// e.g., left + floor(rand() % (right - left + 1))
pivotIndex := partition(list, left, right, pivotIndex)
// The pivot is in its final sorted position
if k = pivotIndex
return list[k]
else if k < pivotIndex
return select(list, left, pivotIndex - 1, k)
else
return select(list, pivotIndex + 1, right, k)
注意到与快速排序的相似之处:就像基于寻找最小值的选择算法是部分选择排序,这可以认为是部分快速排序,只进行O(n log n)而不是O(n)次分区。这个简单的过程具有预期的线性时间复杂度,并且如快速排序一样有相当良好的实际表现。 这也是一个原地算法,只需要栈内常数级的内存,或者可以用循环来去掉尾递归:
function select(list, left, right, k)
loop
if left = right
return list[left]
pivotIndex := ... // select pivotIndex between left and right
pivotIndex := partition(list, left, right, pivotIndex)
if k = pivotIndex
return list[k]
else if k < pivotIndex
right := pivotIndex - 1
else
left := pivotIndex + 1
时间复杂度
与快速排序类似,快速选择算法在平均状况下有着不错的表现,但是对于基准值的选择十分敏感。如果基准值选择上佳,搜索范围每次能够指数级减少,这样一来所耗时间是线性的(即O(n))。但如果基准值选择非常不好,使得每次只能将搜索范围减少一个元素,则最糟的总体时间复杂度是平方级的(O(n2)):例如对一个升序排列的数组搜索其最大值,而每次都选择第一个元素作为基准值。
算法变体
最简单的快速排序变化是每次随机选择基准值,这样可以达到近乎线性的复杂度。更为确定的做法是采用“取三者中位数”[2]的基准值选择策略,这样对已部分排序的数据依然能够达到线性复杂度。但是,特定人为设置的数组在此方法下仍然会导致最差时间复杂度,如大卫·穆塞尔所描述的“取三者中位数杀手”数列,这成为他发表反省式选择算法的动机。
利用中位数的中位数算法,可以在最坏情形下依然保证线性时间复杂度。但是这一方法中的基准值计算十分复杂,实际应用中并不常见。改进方法是在快速选择算法的基础上,使用“中位数的中位数”算法处理极端特例,这样可以保证平均状态与最差情形下的时间复杂度都是线性的,这也是反省式选择算法的做法。
精确计算下,随机选择基准值策略最差会导致复杂度。采用Floyd–Rivest算法可以使这一常数进一步减少,在最坏情形下达到 。


参考文献
- Hoare, C. A. R. . Comm. ACM. 1961, 4 (7): 321–322. doi:10.1145/366622.366647.
- . [2017-03-07]. (原始内容存档于2021-01-24).