隐含狄利克雷分布
隐含狄利克雷分布(英語:,简称LDA),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
LDA首先由 David M. Blei、吴恩达和迈克尔·I·乔丹于2003年提出[1],目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
数学模型
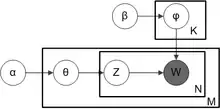
LDA贝斯网络结构
LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。它以概率分佈的形式揭示每個文檔集的主題,以便在分析一些文檔以提取其主題分佈後,可以根據主題分佈進行主題聚類或使用文本分類。每個主題都用一個詞分佈表示[2]。
另外,正如Beta分布是二项式分布的共轭先验概率分布,狄利克雷分布作为多项式分布的共轭先验概率分布。因此正如LDA贝斯网络结构中所描述的,在LDA模型中一篇文档生成的方式如下:
- 从狄利克雷分布中取样生成文档的主题分布
- 从主题的多项式分布中取样生成文档中第个主题
- 从狄利克雷分布中取样生成主题的词语分布
- 从词语的多项式分布中采样最终生成词语








因此整个模型中所有可见变量以及隐藏变量的联合分布是

最终一篇文档的单词分布的最大似然估计可以通过将上式的以及进行积分和对进行求和得到



根据的最大似然估计,最终可以通过吉布斯采样等方法估计出模型中的参数。

使用吉布斯采样估计LDA参数
在LDA最初提出的时候,人们使用EM算法进行求解,后来人们普遍开始使用较为简单的Gibbs Sampling,具体过程如下:
- 首先对所有文档中的所有词遍历一遍,为其都随机分配一个主题,即,其中m表示第m篇文档,n表示文档中的第n个词,k表示主题,K表示主题的总数,之后将对应的,,,,他们分别表示在m文档中k主题出现的次数,m文档中主题数量的和,k主题对应的t词的次数,k主题对应的总词数。
- 之后对下述操作进行重复迭代。
- 对所有文档中的所有词进行遍历,假如当前文档m的词t对应主题为k,则,,,,即先拿出当前词,之后根据LDA中topic sample的概率分布sample出新的主题,在对应的,,,上分别+1。













- ∝


- 迭代完成后输出主题-词参数矩阵φ和文档-主题矩阵θ


参见
参考文献
- Blei, David M.; Ng, Andrew Y.; Jordan, Michael I. Lafferty, John , 编. . Journal of Machine Learning Research. January 2003, 3 (4–5): pp. 993–1022 [2013-07-08]. doi:10.1162/jmlr.2003.3.4-5.993. (原始内容存档于2012-05-01).
- Public Opinion Mining on Construction Health and Safety: Latent Dirichlet Allocation Approach, Buildings 2023, 13(4), 927; https://doi.org/10.3390/buildings13040927
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.