算术编码
算术编码是一种无损数据压缩方法,也是一种熵编码的方法。和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0 ≤ n < 1.0)的小数n。
算术编码工作原理
在给定符号集和符号概率的情况下,算术编码可以给出接近最优的编码结果。使用算术编码的压缩算法通常先要对输入符号的概率进行估计,然后再编码。这个估计越准,编码结果就越接近最优的结果。
例: 对一个简单的信号源进行观察,得到的统计模型如下:
- 60%的机会出现符号 中性
- 20%的机会出现符号 阳性
- 10%的机会出现符号 阴性
- 10%的机会出现符号 数据结束符. (出现这个符号的意思是该信号源'内部中止',在进行数据压缩时这样的情况是很常见的。当第一次也是唯一的一次看到这个符号时,解码器就知道整个信号流都被解码完成了)。
算术编码可以处理的例子不止是这种只有四种符号的情况,更复杂的情况也可以处理,包括高阶的情况。所谓高阶的情况是指当前符号出现的概率受之前出现符号的影响,这时候之前出现的符号,也被称为上下文。比如在英文文档编码的时候,例如,在字母Q或者q出现之后,字母u出现的概率就大大提高了。这种模型还可以进行自适应的变化,即在某种上下文下出现的概率分布的估计随着每次这种上下文出现时的符号而自适应更新,从而更加符合实际的概率分布。不管编码器使用怎样的模型,解码器也必须使用同样的模型。
一個簡單的例子 以下用一個符號序列怎樣被編碼來作一個例子: 假如有一個以A、B、C三個出現機會均等的符號組成的序列。若以簡單的分組編碼會十分浪費地用2 bits來表示一個符號: 其中一個符號是可以不用傳的(下面可以見到符號B正是如此)。為此, 這個序列可以三進制的0和2之間的有理數表示, 而且每位數表示一個符號。例如,“ABBCAB”這個序列可以變成0.011201(base3,即0為A, 1為B, 2為C)。用一個定點二進制數字去對這個數編碼使之在恢復符號表示時有足夠的精度,譬如0.001011001(base2) –只用了9個bit,比起簡單的分組編碼少(1 – 9/12)x100% = 25%。這對於長序列是可行的因為有高效的、適當的算法去精確地轉換任意進制的數字。
编码过程的每一步,除了最后一步,都是相同的。编码器通常需要考虑下面三种数据:
- 下一个要编码的符号
- 当前的区间(在编第一个符号之前,这个区间是[0,1),但是之后每次编码区间都会变化)
- 模型中在这一步可能出现的各个符号的概率分布(像前面提到的一样,高阶或者自适应的模型中,每一步的概率并不必须一样)
编码器将当前的区间分成若干子区间,每个子区间的长度与当前上下文下可能出现的对应符号的概率成正比。当前要编码的符号对应的子区间成为在下一步编码中的初始区间。
例:对于前面提出的4符号模型:
- 中性对应的区间是[0, 0.6)
- 阳性对应的区间是[0.6, 0.8)
- 阴性对应的区间是[0.8, 0.9)
- 数据结束符对应的区间是[0.9, 1)
当所有的符号都编码完毕,最终得到的结果区间即唯一的确定了已编码的符号序列。任何人使用该区间和使用的模型参数即可以解码重建得到该符号序列。
实际上我们并不需要传输最后的结果区间,实际上,我们只需要传输该区间中的一个小数即可。在实用中,只要传输足够的该小数足够的位数(不论几进制),以保证以这些位数开头的所有小数都位于结果区间就可以了。
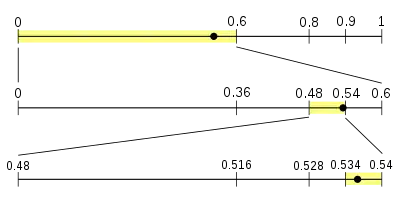
例:下面对使用前面提到的4符号模型进行编码的一段信息进行解码。编码的结果是0.538(为了容易理解,这里使用十进制而不是二进制;我们也假设我们得到的结果的位数恰好够我们解码。下面会讨论这两个问题)。
像编码器所作的那样我们从区间[0,1)开始,使用相同的模型,我们将它分成编码器所必需的四个子区间。分数0.538落在NEUTRAL坐在的子区间[0,0.6);这向我们提示编码器所读的第一个符号必然是NEUTRAL,这样我们就可以将它作为消息的第一个符号记下来。
然后我们将区间[0,0.6)分成子区间:
- 中性 的区间是[0, 0.36) -- [0, 0.6)的60%
- 阳性 的区间是[0.36, 0.48) -- [0, 0.6)的20%
- 阴性 的区间是[0.48, 0.54) -- [0, 0.6)的10%
- 数据结束符 的区间是[0.54, 0.6). -- [0, 0.6)的10%
我们的分数.538在[0.48, 0.54)区间;所以消息的第二个符号一定是NEGATIVE。
我们再一次将当前区间划分成子区间:
- 中性 的区间是[0.48, 0.516)
- 阳性 的区间是[0.516, 0.528)
- 阴性 的区间是[0.528, 0.534)
- 数据结束符 的区间是[0.534, 0.540).
我们的分数.538落在符号END-OF-DATA的区间;所以,这一定是下一个符号。由于它也是内部的结束符号,这也就意味着编码已经结束。(如果数据流没有内部结束,我们需要从其它的途径知道数据流在何处结束——否则我们将永远将解码进行下去,错误地将不属于实际编码生成的数据读进来。)
效率低下的來源
前一個例子中的消息0.538可能已經由同樣短的分數 0.534, 0.535, 0.536, 0.537, 0.539 編碼。這表明使用十進製而不是二進制引入了一些低效率。這是對的;三位十進制的信息內容是 個位元;相同的消息可以在二進制分數 0.10001010 (相當於 0.5390625 十進制)中編碼,僅花費 8 個位元。 (最後的零必須在二進制小數中指定,否則消息將是不明確的,沒有外部信息,如壓縮流大小。)

該 8 位元輸出大於信息內容或消息的熵,也就是:

但是在二進制編碼中必須使用整數位,因此該消息的編碼器將使用至少8位,從而產生比熵內容大 8.4% 的消息。隨著消息大小的增加,這種至多 1 位的低效率導致相對較少的開銷。
此外,要求保護的符號概率為 [0.6, 0.2, 0.1, 0.1) ,但本例中的實際頻率為 [0.33, 0, 0.33, 0.33) 。如果為這些頻率重新調整間隔,則消息的熵將是 4.755 位元,並且相同的中性負數據結束消息可以被編碼為間隔 [0, 1/3) ; [1/9, 2/9) ; [5/27, 6/27) ; 和二進制間隔 [0.00101111011, 0.00111000111) 。這也是算術編碼等統計編碼方法如何產生大於輸入消息的輸出消息的示例,尤其是在概率模型關閉的情況下。
編碼
- 若dataX有M個可能的值,使用k進位的編碼,且
![{\displaystyle (X[i]=1,2,...orM)}](../I/c6be5d7a7598690572438b5aa0d75cd536386a9d.svg)
:the probability of x = n(from prediction)
現在要對dataX做編碼,假設length(X) = N


- 算術編碼的運算方式
initiation: lower = upper =
for i=2:N
lower =
upper = )
end
![{\displaystyle S_{X[1]-1}}](../I/b41af39fad5355c7b866c4c2de9e12229789e526.svg)
![{\displaystyle S_{X[1]}}](../I/dd51fe245d25b6a63da34cd69c4acae9ab75f5d9.svg)
![{\displaystyle S_{X[i]-1}\times (upper-lower)}](../I/212e85dea5bb5b08b8c46fa2a6dc58df6e3182ad.svg)
![{\displaystyle S_{X[i]}\times (upper-lower}](../I/5f4a1ff3d4b978ca771bb69d0b2d2cf626188164.svg)
假設 lower
且C和b為整數(b越小越理想),則dataX可以被編碼成
且
為k進為何b bits來表示C
ex = 01110
ans = b=5,C=14


- 範例
1.假設要對X來做二進位(k=2)的編碼且經由事先的估計,X[i] = a 的機率為0.8,X[i] = b 的機率為0.2
若實際上輸入的資料為X = a a a b a a
initial (X[1] = a): lower = 0, upper = 0.8
When i=2, (X[2] = a): lower = 0, upper = 0.64
When i=3, (X[3] = a): lower = 0, upper = 0.512
When i=4, (X[4] = b): lower = 0.4096, upper = 0.512
When i=5, (X[5] = a): lower = 0.4096, upper = 0.49152
When i=6, (X[6] = a): lower = 0.4096, upper = 0.475136
由於 lower = 0.4096, upper = 0.475136
lower upper
所以編碼結果為
,2進位,5bits



解碼
假設編碼的結果為Y,length(Y) = b,其他的假設和編碼相同(k進位)
- 算術解碼的運算方式
initiation: lower = 0, upper = 1, lower1 = 1, upper1 = 1
for i=1:N
check = 1; while check =1 if there exists an n such that and
are both satisfied,
then check = 0; else
j = j+1 end X(i) = n;
end


![{\displaystyle upper1=lower1+(Y[j]+1)k^{-j}}](../I/08dea8b3c3977e5e5674f381b9c10a9fcbc6122d.svg)
![{\displaystyle lower1=lower1+(Y[j])k^{-j}}](../I/f824b629f6d9aa18734ca02277715f37436f2cbd.svg)


資料長度
假設是預測的X[i] = n的機率,是實際上的X[i] = n的機率
也就是說,若length(X) = N,當中會有N個elements等於n
則
另一方面,由於編碼的假設
在機率的預測完全準確的情況下,
Totoal coding length b 的範圍是
算術編碼的總資料長度的上限比霍夫曼編碼更低








自適應算術編碼
與其他類似的數據壓縮方法相比,算術編碼的一個優點是適應的便利性。適應是在處理數據時改變頻率(或概率)表。只要解碼中的頻率表以與編碼相同的方式和相同的步驟被替換,解碼的數據就匹配原始數據。通常,同步基於在編碼和解碼過程期間出現的符號的組合。
精度和再正規化
上面对算术编码的解释进行了一些简化。尤其是,这种写法看起来好像算术编码首先使用无限精度精度的数值计算总体上表示最后节点的分数,然后在编码结束的时候将这个分数转换成最终的形式。许多算术编码器使用有限精度的数值计算,而不是尽量去模拟无限精度,因为它们知道解码器能够匹配、并且将所计算的分数在那个精度四舍五入到对应值。一个例子能够说明一个模型要将间隔[0,1]分成三份并且使用8位的精度来实现。注意既然精度已经知道,我们能用的二进制数值的范围也已经知道。
| 符号 | 概率(使用分数表示) | 减到8位精度的间隔(用分数表示) | 减到8位精度的间隔(用二进制表示) | 二进制范围 |
|---|---|---|---|---|
| A | 1/3 | [0, 85/256) | [0.00000000, 0.01010101) | 00000000 – 01010100 |
| B | 1/3 | [85/256, 171/256) | [0.01010101, 0.10101011) | 01010101 – 10101010 |
| C | 1/3 | [171/256, 1) | [0.10101011, 1.00000000) | 10101011 – 11111111 |
一个称为再归一化的过程使有限精度不再是能够编码的字符数目的限制。当范围减小到范围内的所有数值共享特定的数字时,那些数字就送到输出数据中。尽管计算机能够处理许多位数的精度,编码所用位数少于它们的精度,这样现存的数据进行左移,在右面添加新的数据位以尽量扩展能用的数据范围。注意这样的结果出现在前面三个例子中的两个里面。
| 符号 | 概率 | 范围 | 能够输出的数据位 | 再归一化后的范围 |
|---|---|---|---|---|
| A | 1/3 | 00000000 – 01010100 | 0 | 00000000 – 10101001 |
| B | 1/3 | 01010101 – 10101010 | None | 01010101 – 10101010 |
| C | 1/3 | 10101011 – 11111111 | 1 | 01010110 – 11111111 |
算术编码和其他压缩方法的關係
霍夫曼编碼
算术编码和哈夫曼编码的相似程度很高——事實上,哈夫曼编码只是算术编码的一个特例。但是,算术编码将整个消息翻译成一个表示为基数 b,而不是将消息中的每个符号翻译成一系列的以 b 为基数的数字,因此通常比哈夫曼编码更能达到最优熵编码。
因為算術編碼不能一次壓縮一個數據,所以在壓縮iid字符串時它可以任意接近熵。相反,使用霍夫曼編碼(到字符串)的擴展不會達到熵,除非字母符號的所有概率都是 2 的冪,在這種情況下,霍夫曼和算術編碼都實現熵。
當霍夫曼編碼二進製字符串時,即使熵低(例如({0, 1})具有概率{0.95, 0.05}),也不可能進行壓縮。霍夫曼編碼為每個值分配 1 位元,產生與輸入長度相同的代碼。相比之下,算術編碼可以更加地壓縮位元,接近最佳壓縮比
![{\displaystyle 1-[-0.95\log _{2}(0.95)+-0.05\log _{2}(0.05)]\approx 71.4\%.}](../I/6d67ecf0a07f6d1d6a34dc7730f5cfe74bc75e98.svg)
解決霍夫曼編碼次優性的一種簡單方法是連接符號(阻塞)以形成新的字母表,其中每個新符號表示來自原始字母表的原始符號序列(在這種情況下是位元)。在上面的例子中,在編碼之前對三個符號的序列進行分組將產生具有以下頻率的新「超符號」:
- 000: 85.7%
- 001, 010, 100: 4.5% each
- 011, 101, 110: 0.24% each
- 111: 0.0125%
通過這種分組,霍夫曼編碼每三個符號平均為 1.3 位元,或每符號 0.433 位元,而原始編碼中每符號一位元,即 壓縮。允許任意大的序列隨意接近熵(就像算術編碼一樣),但需要大量代碼才能這樣做,因此不如算術編碼那麼實用。

另一種方法是通過基於霍夫曼的 Golomb-Rice 編碼編碼遊程長度。這種方法允許比算術編碼或甚至霍夫曼編碼更簡單和更快的編碼/解碼,因為後者需要表查找。在 {0.95, 0.05} 示例中,具有四位餘數的 Golomb-Rice 代碼實現了壓縮率 ,遠遠低於使用三位塊的壓縮率。 Golomb-Rice 代碼僅適用於伯努利輸入,例如本例中的輸入,因此它不能代替所有情況下的阻塞。

區间编碼
算术编码与区间编码有很深的相似渊源,以至于人們通常认为兩者的性能是相同的,如果确实有什么不同的话也只是区间编码仅仅落后几个位的值而已。区间编码与算术编码不同,通常认为它不被任何公司的专利所約束。
区间编码的原理是这样的,它没有像算术编码那样从 [0,1] 开始并根据每个字符出现的概率把它分成相应的不同的小区间,它从如 000,000,000,000 到 999,999,999,999 这样一个很大的非负整数区间开始,并且根据每个字符的概率划分成小的子区间。当子区间小到一定程度最后结果的开头数字出现的时候,那些数字就能够“左移”出整个运算,并且用“右边”的数字替换——每次出现移位时,就大体相当于最初区间的一个回归放大(retroactive multiplication)。
关于算术编码的美国专利
许多算术编码所用的不同方法受美国专利的保护。其中一些专利对于实现一些国际标准中定义的算术编码算法是很关键的。在这种情况下,这些专利通常按照一种合理和非歧视(RAND)授权协议使用(至少是作为标准委员会的一种策略)。在一些著名的案例中(包括一些涉及IBM的专利)这些授权是免费的,而在另外一些案例中,则收取一定的授权费用。RAND条款的授权协议不一定能够满足所有打算使用这项技术的用户,因为对于一个打算生产拥有所有权软件的公司来说这项费用是“合理的”,而对于自由软件和开源软件项目来说它是不合理的。
在算术编码领域做了很多开创性工作并拥有很多专利的一个著名公司是IBM。一些分析人士感到那种认为没有一种实用并且有效的算术编码能够在不触犯IBM和其它公司拥有的专利条件下实现只是数据压缩界中的一种持续的都会传奇(尤其是当看到有效的算术编码已经使用了很长时间最初的专利开始到期)。然而,由于专利法没有提供“明确界线”测试所以一种威慑心理总让人担忧法庭将会找到触犯专利的特殊应用,并且随着对于专利范围的详细审查将会发现一个不好的裁决将带来很大的损失,这些技术的专利保护然而对它们的应用产生了一种阻止的效果。至少一种重要的压缩软件bzip2,出于对于专利状况的担心,故意停止了算术编码的使用而转向Huffman编码。
关于算术编码的美国专利列在下面。
- Patent 4,122,440—(IBM)提交日期March 4, 1977,批准日期Oct 24, 1978(现在已经到期)
- Patent 4,286,256—(IBM)批准日期Aug 25, 1981(大概已经到期)
- Patent 4,467,317—(IBM)批准日期Aug 21, 1984(大概已经到期)
- Patent 4,652,856—(IBM)批准日期Feb 4, 1986(大概已经到期)
- Patent 4,891,643—(IBM)提交时间1986/09/15,批准日期1990/01/02
- Patent 4,905,297—(IBM)批准日期Feb 27, 1990
- Patent 4,933,883—(IBM)批准日期Jun 12, 1990
- Patent 4,935,882—(IBM)批准日期Jun 19, 1990
- Patent 4,989,000—(???)提交时间1989/06/19,批准日期1991/01/29
- Patent 5,099,440
- Patent 5,272,478—(Ricoh)
注意:这个列表没有囊括所有的专利。关于更多的专利信息请参见后面的链接。 (页面存档备份,存于)
算术编码的专利可能在其它国家司法领域存在,参见软件专利中关于软件在世界各地专利性的讨论。
外部链接
- The on-line textbook: Information Theory, Inference, and Learning Algorithms (页面存档备份,存于), by David J.C. MacKay, explains arithmetic coding in Chapter 6.
 本条目引用的公有领域材料。材料来自NIST的文档:Black, Paul E. . 演算法與資料結構辭典.
本条目引用的公有领域材料。材料来自NIST的文档:Black, Paul E. . 演算法與資料結構辭典.- "Arithmetic Coding" site on Compression-links.info (free open version of DataCompression.info) (页面存档备份,存于) - collection of links pertaining to arithmetic coding
- Newsgroup posting (页面存档备份,存于) with a short worked example of arithmetic encoding (integer-only).
- AIC-Context Adaptive Binary Arithmetic Coding (页面存档备份,存于) very clear concept and demonstration for fresher.