管道 (Unix)
在类Unix操作系统(以及一些其他借用了这个设计的操作系统,如Windows)中,管道(英語:)是一系列将标准输入输出链接起来的进程,其中每一个进程的输出被直接作为下一个进程的输入。 每一个链接都由匿名管道实现。管道中的组成元素也被称作过滤程序。
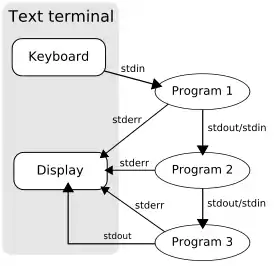
例子
简单样例
ls -l | less
在这个例子中,ls用于在Unix下列出目录内容,less是一个有搜索功能的交互式的文本分页器。这个管线使得用户可以在列出的目录内容比屏幕长时目录上下翻页。
以less結束的管道(或more,這是個相似的分頁工具)是最常被使用的。這讓使用者可以閱覽尚未顯示的大量文字(受可用緩存限制,控制台的屏幕大小、屏幕缓存大小往往有限,不足以一次先输出所有输出内容,也不能自由滚动内容),若少了這工具則這些文字將會捲過終端機而無法閱讀到。換句話說,他们将程序员从为自己的软件开发分页器的负担中解放了出来:他们只需要把他们的输出用过“管道”导入到less程序中即可,甚至也可以完全不顾分页问题,去假定他们的用户会在需要将输出分页的时候自己去这样做。
复杂样例
以下是一個管線的範例,執行由一URL標示的全球資訊網資源的一種拼寫檢查器。之後是關於這個其作用的說明。注意「\」是用來把這六行轉為一個命令列。
curl "https://en.wikipedia.org/wiki/Pipeline_(Unix)" | \
sed 's/[^a-zA-Z ]/ /g' | \
tr 'A-Z ' 'a-z\n' | \
grep '[a-z]' | \
sort -u | \
comm -23 - /usr/share/dict/words | \
less
- curl 取得該網頁的HTML內容(在有些系統上可以使用wget)。
- sed 移除非空格的字元和網頁內容的字母,並以空格取代之。
- tr 把大寫字母改成小寫字母,並把行列裡的空格換成新行(每個詞現在各占有獨立的一行)。
- grep 过滤得到那些至少有一个小写字母的行(删除空行)。
- sort 将“单词”(也就是每一个行)按照字母顺序排序,并且通过命令行的-u参数来删除重复的行。
- comm 查找两个文件中的共同行,-23过滤掉只有第二个文件拥有的行、两个文件共有的行,仅仅留下只在第一个文件中有的行。在文件名的位置上的-参数表示要求comm使用标准输入(在这个例子里,他的标准输入来自于管道上游的标准输出)作为输入,而不是以普通文件作为输入。最终得到一串没有出现在/usr/share/dict/words之中的“单词”(也就是一行)。
- less 允许用户翻页浏览结果。
这个特殊的“|”字符告诉命令行解释器(Shell)将前一个命令的输出通过“管道”导入到接下来的一行命令作为输入。也就是说,curl命令的输出被作为sed命令的输入,后面的命令也是这样。
命令行界面中的管线
所有广泛应用于UNIX和Windows中的shell程序都有特殊的语法构建管线。典型语法是使用ASCII中的垂直线“|”(正是由于这个原因,这个符号常被称为管道符)。当出现这样的语法时shell会启动各个进程,并调整各个进程的标准流之间的连接(还包括安排一些缓存)。
错误流
通常,管线中的进程的标准错误流("stderr")不会通过管道传输;它们被合并输出到控制台。然而,很多Shell提供一些扩充的语法去改变这一行为。比如在csh Shell和bash中,使用“|&”代替“|”来表示错误流也需要被合并进入标准输出,并传递给下一个进程。Bourne shell也可以合并错误流,通过 2>&1 也可以将错误流重定向到一个不同的文件。
Pipemill
在一些常用的简单管线中,shell仅仅只是用管道来连接每个子进程,然后在子进程中执行外部命令。因此shell本身没有通过管线来处理数据。
然而,shell也有可能直接处理管线数据。构建这样的语法像这样:
command | while read var1 var2 ...; do
# process each line, using variables as parsed into $var1, $var2, etc
# (note that this is a subshell: var1, var2 etc will not be available
# after the while loop terminates)
done
... 这样的语法叫 "pipemill" 。
在程序中创造管道
匿名管道
使用C语言在UNIX中使用pipe(2)系统调用时,这个函数会让系统构建一个匿名管道,这样在进程中就打开了两个新的,打开的文件描述符:一个只读端和一个只写端。管道的两端是两个普通的,匿名的文件描述符,这就让其他进程无法连接该管道。
为了避免死锁并利用进程的并行运行的好处,有一个或多个管道的UNIX进程通常会调用fork(2)产生新进程。并且每个子进程在开始读或写管道之前都会关掉不会用到的管道端。或者进程会产生一个子线程并使用管道来让线程进行数据交换。
实现代码:
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int
main(int argc, char *argv[])
{
int pipefd[2];
pid_t cpid;
char buf;
if (argc != 2) {
fprintf(stderr, "Usage: %s <string>\n", argv[0]);
exit(EXIT_FAILURE);
}
if (pipe(pipefd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0) { /* Child reads from pipe */
close(pipefd[1]); /* Close unused write end */
while (read(pipefd[0], &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
write(STDOUT_FILENO, "\n", 1);
close(pipefd[0]);
_exit(EXIT_SUCCESS);
} else { /* Parent writes argv[1] to pipe */
close(pipefd[0]); /* Close unused read end */
write(pipefd[1], argv[1], strlen(argv[1]));
close(pipefd[1]); /* Reader will see EOF */
wait(NULL); /* Wait for child */
exit(EXIT_SUCCESS);
}
}
具名管道
具名管道可以通过调用mkfifo(2)或mknod(2)来构建,当被调用时表现为输入或输出的文件。这样可以允许建立多个管道,并且将其同标准错误重定向或tee结合起来使用更为有效。
实现代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
char filename[] = "test_fifo";
if (!mkfifo(filename,S_IRUSR | S_IWUSR| S_IRGRP|S_IWGRP)){
pid_t pid = fork();
if (pid == 0){ //child
int fd = open(filename, O_WRONLY);
if (fd < 0)
perror("child open()");
else{
if (strlen(argv[1]) != write(fd, argv[1], strlen(argv[1])))
perror("child write error");
else
close(fd);
}
}
else if (pid > 0){ //father
int fd = open(filename, O_RDONLY);
if (fd < 0)
perror("father open()");
else{
char buffer[200];
int readed = read(fd, buffer, 199);
close(fd);
buffer[readed] = '\0';
printf("%s\n",buffer);
}
}
else
perror("fork()");
}
else
perror("mkfifo() error:");
}
以上代码在编译后运行时给出一个参数,子进程会将该参数内容写入管道(该管道在当前目录下,文件名为“test_fifo”),父进程从管道中读取内容并显示出来
实现
在大多数类UNIX操作系统中,管线上的所有进程同时启动,输入输出流也已经被正确地连接,并且这些进程被调度程序所管理。最为重要的一点就是,所有的UNIX管道和其他管道实现不一样的地方就是缓存的概念:输出进程可能会以每秒5000 byte的速度输出,但是接收进程也许每秒只能接收100 byte,但不会有数据丢失。原因就是管道上游的进程的所有输出都会被放入一个队列中。当下游进程开始接收数据时,操作系统就会将数据从队列传至接收进程,并将传完的数据从队列中移除。当缓存队列空间不足时,上游进程会被终止,直到接收进程读取数据为上游进程腾出空间。在Linux中,缓存队列的大小是65536 byte。
歷史
管道的概念以及垂直线的记号(|)都是由道格拉斯·麥克羅伊发明的,他是早期命令行外壳的作者。他发现他常常将一个程序的输出作为另一个程序的输入,于是便发明了“管道。它的想法在1973年被实现,Ken Thompson将管道添加到了UNIX操作系统。[1]这个点子最终被移植到了其他的操作系统,比如DOS、OS/2、Microsoft Windows和BeOS,而且常常使用相同的记号(垂直线)。
虽然管道概念是独立发展的,但是 Unix 管道相似于、也确实晚于由Ken Lochner在20世纪60年代为Dartmouth Time Sharing System开发的'communication files'。[2][3]
在苹果Automator(类似管道一样将多个重复的命令链接起来)的那个机器人拿着一根管子的图标也是对于最初Unix管道概念的纪念。
其他作業系統
其他作業系統的這個特色源自於Unix,例如 Taos 和 MS-DOS,最終成為軟體工程的管道与过滤器设计模式。
参见
引用
- http://www.linfo.org/pipe.html (页面存档备份,存于) Pipes: A Brief Introduction by The Linux Information Project (LINFO)
- . [2010-08-14]. (原始内容存档于2021-02-25).
- . [2010-08-14]. (原始内容存档于1999-02-20).
- Sal Soghoian on MacBreak Episode 3 "Enter the Automatrix"
外部链接
- History of Unix pipe notation (页面存档备份,存于)
- Doug McIlroy’s original 1964 memo (页面存档备份,存于), proposing the concept of a pipe for the first time
- : create an interprocess channel – 系统界面(System Interfaces)参考,单一UNIX®规范第7期,由國際開放標準組織发布
- Pipes: A Brief Introduction (页面存档备份,存于) by The Linux Information Project (LINFO)
- Unix Pipes – powerful and elegant programming paradigm (Softpanorama) (页面存档备份,存于)
- Ad Hoc Data Analysis From The Unix Command Line at Wikibooks (页面存档备份,存于) – Shows how to use pipelines composed of simple filters to do complex data analysis.
- Use And Abuse Of Pipes With Audio Data (页面存档备份,存于) – Gives an introduction to using and abusing pipes with netcat, nettee and fifos to play audio across a network.
- stackoverflow.com (页面存档备份,存于) – A Q&A about bash pipeline handling.