线性探测
线性探测是计算机程序解决散列表冲突时所采取的一种策略。散列表这种数据结构用于保存键值对,并且能通过给出的键来查找表中对应的值。线性探测这种策略是在1954年由Gene Amdahl, Elaine M. McGraw,和 亞瑟·李·塞謬爾 所发明,并且最早于1963年由Donald Knuth对其进行分析。
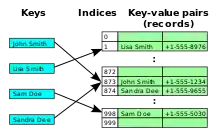
与二次探测和双散列一样,线性探测是一种开放寻址的策略。在这些策略里,散列表的每个单元都存储一对键值对。当散列函数对一个给定值产生一个键,并且这个键指向散列表中某个已经被另一个键值对所占用的单元时,线性探测用于解决此时产生的冲突:查找散列表中离冲突单元最近的空闲单元,并且把新的键插入这个空闲单元。同样的,查找也同插入如出一辙:从散列函数给出的散列值对应的单元开始查找,直到找到与键对应的值或者是找到空单元。
正如Thorup和張寅在2012年所写,…“散列表是最常用的普通数据结构,它在硬件上的标准实现中最流行的方法就是使用线性探测。线性探测又快又简单。[1]”线性探测能够提供高性能的原因是因为它的良好的引用局部性,然而它与其他解决散列冲突的策略相比对于散列函数的质量更为敏感。当使用随机散列函数, 5-independent散列函数或tabulation散列函数,其用于搜索,插入或删除的预期时间是常数。不過,藉由其他像是私語雜湊的散列函數可以在實作中達到較好的結果[2]。
操作
雜湊衝突一般發生於雜湊函數將一個鍵丟進已經含有另一個不同鍵的單元中的時候。線性探測是一個用來解決衝突的策略,其將新鍵丟進最靠近的下一個空單元中[3][4]。
搜索
为了搜索给定的键 x,散列表中由h(x)对应的单元开始的相邻单元 h(x) + 1, h(x) + 2, ..., 都将被检查,直到找到了内容为空的单元或是找到了存储给定键为x的单元。其中,h是散列函数。如果找到了存储给定键的单元,搜索将会返回单元中存储的键对应的值。否则,如果搜索遇到了空的单元,键在表中就不存在,因为键应当被存放在所有未被搜索的单元之前。此时,搜索返回表中无此键的结果。
插入
为了在表中插入一对键值对(x,v) (有可能会替换有着相同键的键值对),插入算法也会访问搜索算法访问的同一系列单元,直到找到一个空的单元,或是找到了存储给定键为x的单元。新的键值对将会存储在此单元中。
如果插入将导致表(占用单元的比例)增长高于某个预设的阈值的负载系数,整个表可以通过一个新的表(规模大于本表规模)和一个新的散列函数来代替,如使用动态数组。设置这个的阈值接近于零,并使用表大小的高增长率来带来更快速的哈希表的操作,但相比于接近一个阈值与低增长率,它会带来更高的内存使用情况。一个常见的选择是表规模扩大一倍,当负载系数将超过1/2,导致负载系数保持在1/4和1/2之间。
删除

散列表应当提供删除键值对的功能。然而,單純地清空对应的单元是不夠的。這會影響到對於儲存時間早於該單元、但儲存位置在該單元之後的其他鍵。此單元會造成搜索獲得錯誤的結果,告訴使用者這些鍵並不存在。
相较于直接清空对应单元i,更好的做法是先清空,然后把它之后所有会造成问题的单元向前移动,来避免搜索出错。重複直到出現空單元,則刪除動作安全完成。但是,如果有發現後續有鍵可以移到這個位置上的話,直接將該鍵取代欲刪除的單元可以加速後續的其他行為,當然,這樣也會造成後面多出一個新的空單元。搜索可用來取代的單元的動作會持續到搜索到原本就空白的單元為止。在這個將鍵移到前面的過程中,所有的鍵都會被算過一遍。因此,完成這整個過程所需的時間與該儲存位置的單元數量呈正比,與雜湊表的其他運算相符[3]。
有一種可行的替代方案是懶惰刪除,用指向欲刪除鍵的特殊的標誌值(flag value)取代原本的鍵值配對。不過,這些標誌值在搜索上會當作非空。因此,如果一個陣列中有過多的被刪除鍵,那麼就需要清除所有的標誌值並且重新雜湊整個表[3][4]。
註解與參考文獻
- Thorup, Mikkel; Zhang, Yin, , SIAM Journal on Computing, 2012, 41 (2): 293–331, MR 2914329, doi:10.1137/100800774.
- Richter, Stefan; Alvarez, Victor; Dittrich, Jens, , Proceedings of the VLDB Endowment, 2015, 9 (3): 293–331.
- Goodrich, Michael T.; Tamassia, Roberto, , , Wiley: 200–203, 2015.
- Morin, Pat, , 0.1Gβ: 108–116, February 22, 2014 [2016-01-15], (原始内容存档于2017-10-19).