翻译后修饰
翻译后修饰(英語:Post-translational modification,縮寫PTM;又稱後轉譯修飾)是指蛋白質在翻译後的化學修飾。對於大部份的蛋白質來說,這是蛋白質生物合成的較後步驟。PTM是細胞信號傳導中的重要組成部分。

胰島素的翻譯後修飾。 At the top, the ribosome translates a mRNA sequence into a protein, insulin, and passes the protein through the endoplasmic reticulum, where it is cut, folded, and held in shape by disulfide (-S-S-) bonds. Then the protein passes through the golgi apparatus, where it is packaged into a vesicle. In the vesicle, more parts are cut off, and it turns into mature insulin.
蛋白質,或是多肽,是多條或一條胺基酸的鏈。當合成蛋白質時,20種不同的胺基酸會合併成為蛋白質。胺基酸的轉译後修飾會附在蛋白質其他的生物化學官能團(如醋酸鹽、磷酸鹽、不同的脂類及碳水化合物)、改變胺基酸的化學性質,或是造成結構的改變(如建立雙硫鍵),來擴闊蛋白質的功能。
再者,酶可以從蛋白質的N末端移除胺基酸,或從中間將肽鏈剪開。舉例來說,胰島素是肽的激素,它會在建立雙硫鍵後被剪開兩次,並在鏈的中間移走多肽前體,而形成的蛋白質包含了兩條以雙硫鍵連接的多肽鏈。
其他修飾,就像磷酸化,是控制蛋白質活動機制的一部份。蛋白質活動可以是令酶活性化或鈍化。
加入官能團
翻译後修飾包括以下加入官能團的反應:
- 乙醯化——通常於蛋白質的N末端加入乙醯。
- 烷基化——加入如甲基或乙基等烷基。
- 生物素化——用生物素附加物令保存的賴氨酸醯化。
- 穀氨酸化——在穀氨酸與導管素及其他蛋白質之間建立共價鍵。
- 甘胺酸化——在一個至超過40種甘胺酸與導管素的C末端建立共價鍵。
- 糖化——將糖基加入天冬醯胺、羥離氨酸、絲氨酸或蘇氨酸,形成糖蛋白。
- 異戊二烯化——加入如法呢醇及四異戊二烯等異戊二烯。
- 硫辛酸化——附著硫辛酸的功能性。
- 磷酸泛酰巰基乙胺基化——像在脂肪酸、聚酮、非核醣體肽鏈及白氨酸的生物合成中,從乙醯輔酶A加入4'磷酸泛酰巰基乙胺基。
- 磷酸化——加入磷酸根至絲氨酸、酪氨酸、蘇氨酸或組氨酸。
- 硫酸化——將硫酸根加入至酪氨酸。
- 硒化
- C末端醯胺化
數據庫與工具
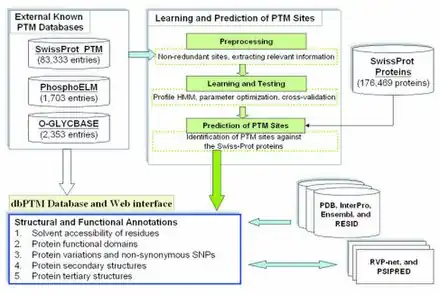
Flowchart of the process and the data sources to predict PTMs.[3]
蛋白質序列包含通過修飾酶識別的序列基序,並且可以在 PTM 數據庫中記錄或預測。 隨著發現大量不同的修改,需要在數據庫中記錄此類信息。 PTM 信息可以通過實驗手段收集,也可以從高質量、手動整理的數據中預測。 已經創建了許多數據庫,通常側重於某些分類群(例如人類蛋白質)或其他特徵。
資源列表
參考文献
- Malakhova, Oxana A.; Yan, Ming; Malakhov, Michael P.; Yuan, Youzhong; Ritchie, Kenneth J.; Kim, Keun Il; Peterson, Luke F.; Shuai, Ke; and Dong-Er Zhang. . Genes & Development. 2003, 17 (4): 455–460 [2006-11-22]. (原始内容存档于2008-07-19).
- Van G. Wilson , 编. . Horizon Bioscience. 2004. ISBN 978-0-9545232-8-2. (原始内容存档于2005-02-09).
- Lee TY, Huang HD, Hung JH, Huang HY, Yang YS, Wang TH. . Nucleic Acids Research. January 2006, 34 (Database issue): D622–7. PMC 1347446
 . PMID 16381945. doi:10.1093/nar/gkj083.
. PMID 16381945. doi:10.1093/nar/gkj083. - Hornbeck PV, Zhang B, Murray B, Kornhauser JM, Latham V, Skrzypek E. . Nucleic Acids Research. January 2015, 43 (Database issue): D512–20. PMC 4383998 . PMID 25514926. doi:10.1093/nar/gku1267.
- Goel R, Harsha HC, Pandey A, Prasad TS. . Molecular BioSystems. February 2012, 8 (2): 453–63. PMC 3804167 . PMID 22159132. doi:10.1039/c1mb05340j.
- Sigrist CJ, Cerutti L, de Castro E, Langendijk-Genevaux PS, Bulliard V, Bairoch A, Hulo N. . Nucleic Acids Research. January 2010, 38 (Database issue): D161–6. PMC 2808866 . PMID 19858104. doi:10.1093/nar/gkp885.
- Warnecke A, Sandalova T, Achour A, Harris RA. . BMC Bioinformatics. November 2014, 15 (1): 370. PMC 4256751 . PMID 25431162. doi:10.1186/s12859-014-0370-6.
- Yang Y, Peng X, Ying P, Tian J, Li J, Ke J, Zhu Y, Gong Y, Zou D, Yang N, Wang X, Mei S, Zhong R, Gong J, Chang J, Miao X. . Nucleic Acids Research. January 2019, 47 (D1): D874–D880. PMC 6324025 . PMID 30215764. doi:10.1093/nar/gky821.
- Morris JH, Huang CC, Babbitt PC, Ferrin TE. . Bioinformatics. September 2007, 23 (17): 2345–7. PMID 17623706. doi:10.1093/bioinformatics/btm329 .
- . www.proteopedia.org. [2023-04-18]. (原始内容存档于2009-08-28).
外部連接
- dbPTM - database of protein post-translational modifications (页面存档备份,存于)
- List of posttranslational modifications in ExPASy (页面存档备份,存于)
- Browse SCOP domains by PTM (页面存档备份,存于) — from the dcGO database
- Statistics of each post-translational modification from the Swiss-Prot database
- AutoMotif Server - A Computational Protocol for Identification of Post-Translational Modifications in Protein Sequences
- Functional analyses for site-specific phosphorylation of a target protein in cells
- Detection of Post-Translational Modifications after high-accuracy MSMS
- Overview and descripition of commonly used post-translational modification detection techniques (页面存档备份,存于)
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.