计算机集群
计算机集群(英語:)是一组松散或紧密连接在一起工作的计算机。由于这些计算机协同工作,在许多方面它们可以被视为单个系统。与网格计算机不同,计算机集群将每个节点设置为执行相同的任务,由软件控制和调度。


集群的组件通常通过快速局域网相互连接,每个节点(用作服务器的计算机)运行自己的操作系统实例。在大多数情况下,所有节点使用相同的硬件[1]和相同的操作系统,尽管在某些设置中(例如使用OSCAR),可以在每台计算机或不同的硬件上使用不同的操作系统。[2]
部署集群通常是为了提高单台计算机的性能和可用性,而集群也通常比速度或可用性相当的单台计算机的成本效益要高。[3]
计算机集群的出现是许多计算趋势汇聚的结果,这些趋势包括低成本微处理器、高速网络以及用于高性能分布式计算软件的广泛使用。集群使用和部署广泛,从小型企业集群到世界上最快超级电脑(如IBM的Sequoia)。[4] 在集群出现之前,人们采用具有模块冗余的单元容错主机;但是,集群的前期成本较低,网络结构速度提高,这助推了人们采用集群这种方式。与高可靠性的大型机集群相比,扩展成本更低,但也增加了错误处理的复杂性,因为在集群中错误模式对于运行的程序是不透明的。[5]
基本概念

为了通过组合低成本的商用现成计算机,来获得更大的计算能力和更好的可靠性,人们研究提出了各种架构和配置。
计算机集群方法通常通过快速局域网连接许多现成的计算节点(例如用作服务器的个人计算机)。[6] 计算节点的活动由“集群中间件”协调,集群中间件是一个位于节点之上的软件层,让用户可以将集群视为一个整体的内聚计算单元(例如通过单系统映像概念)。[6]
计算机集群依赖于一种集中管理方法,该方法把节点用作协调的共享服务器。它不同于其他方法(比如对等计算或网格计算),后者也使用许多节点,但具有更多的分布式特性。[6]
计算机集群可能是一个简单的两节点系统,只连接两台个人电脑,也可能是一台速度非常快的超级计算机。构建集群的基本方法是贝奥武夫机群,它可以使用少量个人计算机构建,以产生与传统高性能计算相比经济划算的替代方案。一个展示概念可行性的早期项目是133节点的Stone Soupercomputer。[7] 开发人员使用Linux、并行虚拟机工具包和訊息傳遞介面库以相对较低的成本实现高性能。[8]
尽管一个集群可能仅由几台通过简单网络连接的个人计算机组成,但集群架构也可用于实现非常高的性能水平。TOP500组织每半年公布的500台最快超级计算机的名单通常包括许多集群,例如,2011年世界上最快的机器是“京”,它有分布存储器和集群架构。[9]
历史

Greg Pfister指出,集群最初不是由特定的供应商发明的,而是由无法在一台计算机上完成所有工作或需要备份的客户发明的。 [10] 他估计计算机集群发明于20世纪60年代。 作为并行工作的一种方式,集群计算的正式工程基础可以说是由IBM的吉恩·阿姆達爾发明的,因为他在1967年出版了被认为是关于并行处理的开创性论文:阿姆达尔定律。
早期计算机集群的历史或多或少直接与早期网络的历史有关,因为网络发展的主要动机之一是连接计算资源,创建真正的计算机集群。
第一个被设计成集群的生产系统是20世纪60年代中期的Burroughs B5700,它允许多达四台计算机(每个计算机都有一个或两个处理器)紧密连接到一个公共磁盘存储系统,以平衡工作负载。与标准的多处理器系统不同,每台计算机都可以在不中断整体运行的情况下重新启动。
第一个商业松散耦合的集群产品是Datapoint公司的“附加资源计算机”(Attached Resource Computer,ARC)系统,该系统于1977年开发,使用ARCNET作为集群接口。直到迪吉多电脑公司在1984年为VAX/VMS操作系统(现在称为OpenVMS)发布了VAXcluster产品,集群才真正开始。ARC和VAX集群产品不仅支持并行计算,还支持共享文件系统和外部设备。其目的是提供并行处理的优势,同时保持数据的可靠性和唯一性。另外两个值得注意的早期商业集群是Tandem Computers(大约1994年出现的高可用性产品)和IBM S/390 Parallel Sysplex(也在大约1994年出现,主要用于商业用途)。
同时,当商业网络使用计算机集群在计算机外部的并行性时,超级计算机开始在计算机内部中使用它们。继CDC 6600在1964年取得成功之后,Cray 1也于1976年成功发布,并通过向量处理引入了内部并行性。[11] 虽然早期的超级计算机不使用集群而是使用了共享内存,但一些速度最快的超级计算机(如京)最终依赖于集群架构。
集群的属性
可以根据不同目的配置计算机集群,从一般用途的业务需求(如Web服务支持),到计算密集型的科学计算。在这两种情况下,集群都可以使用高可用性方法。请注意,下面描述的属性并不是排他的,“计算机集群”也可以使用高可用性方法等等。
“负载均衡”集群是集群节点共享计算工作负载,以提供更好的总体性能的配置。例如,Web服务器集群可以将不同的查询分配给不同的节点,因此总体响应时间将得到优化。[12] 然而,负载平衡的方法可能在不同的应用程序之间有很大的不同,例如,用于科学计算的高性能集群的平衡负载算法与Web服务器集群不同,Web服务器集群可能只是使用一种简单的循环方法,将每个新请求分配到不同节点。[12]
计算机集群用于计算密集型目的,而不是处理面向IO的操作(如Web服务或数据库)。[13] 例如,计算机集群可能支持车祸或天气的计算模拟。非常紧密耦合的计算机集群被设计用于可能接近“超级计算”的工作。
“高可用性集群”提高了集群方法的可用性。它们通过拥有冗余节点来运行,当系统组件出现故障时,这些节点将用于提供服务。高可用性集群实现试图使用集群组件的冗余来消除单点故障。许多操作系统都有高可用性集群的商业实现。Linux-HA项目是Linux操作系统常用的一个自由软件HA包。
优点
集群的设计主要考虑性能,但实际使用中还涉及许多其他因素,包括容错(能够容许系统继续使用故障节点)能力、可扩展性、高性能、不需要频繁运行维护程序、资源整合(如RAID)和集中管理。集群的优点包括在发生灾难时启用数据恢复、提供并行数据处理和高计算能力。[14][15]
在可伸缩性方面,集群提供了水平添加节点的能力。这意味着可以向集群中添加更多的计算机,以提高其性能、冗余和容错。与在集群中扩展单个节点相比,添加节点是一个既节省成本,又可以使集群获得更高的性能的解决方案。计算机集群的这一大特性允许大量性能较低的计算机执行较大的计算负载。
向集群添加新节点时,可靠性也会增加,这是因为进行维护的时候不需要停下整个集群,只需停下单个节点维护,集群的其余节点承担该节点的负载即可。
设计与配置
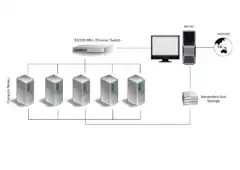
设计集群的问题之一是各个节点之间的耦合程度。例如,单个计算机作业可能需要节点之间的频繁通信:这意味着集群共享一个专用网络,位置密集,可能有同类节点。另一个极端是计算机作业使用一个或几个节点,并且需要很少或没有节点间通信,接近网格计算。
在贝奥武夫机群中,应用程序从不会看到计算节点(也叫“从属计算机”),只与“主计算机”交互,而“主计算机”是处理从属计算机的调度和管理的特定计算机。[13] 在典型的实现中,主计算机具有两个网络接口,一个用于为从属设备与专用贝奥武夫网络通信,另一个用于组织的通用网络。[13] 从属计算机通常有同一操作系统、本地内存和磁盘空间的它们自己的版本。但是,专用从属网络还可以有大型共享文件服务器,该服务器存储全局持久数据,从属设备可以根据需要访问这些数据。[13]
一个特殊用途的144节点DEGIMA集群被调整为使用多步行并行树码运行天体物理N体仿真,而不是通用的科学计算。[16]
由于每一代游戏机的计算能力不断增强,一种新的用途出现了,它们被重新用于高性能计算(HPC)集群。游戏机集群的例子有索尼PlayStation集群和微软Xbox集群。另一个消费类游戏产品的例子是Nvidia Tesla个人超级计算机工作站,它使用多个图形加速处理器芯片。除了游戏机,也可以使用高端显卡。使用显卡进行网格计算比使用CPU更经济,尽管不太精确。但是,当使用双精度值时,它们变得像CPU一样精确,并且成本更低。[2]
计算机集群历来在使用相同操作系统的独立物理计算机上运行。随着虛擬化技术的出现,集群节点可以在具有不同操作系统的独立物理计算机上运行,这些操作系统上面绘制了一个虚拟层,使之看起来相似。[17] 当进行维护时,集群还可以在各种配置上进行虚拟化。一个示例实现是Xen作为Linux-HA的虚拟化管理器。[17]
数据共享与通信
数据共享

随着计算机集群在20世纪80年代的出现,超级计算机也应运而生。早期的超级计算机依赖于共享内存,这是当时这三类计算机的区别之一。迄今为止,集群通常不使用物理共享内存,而许多超级计算机体系结构也放弃了这一点。
不过,在现代计算机集群中,集群文件系统的使用是必不可少的。例如IBM通用并行文件系统、Microsoft的集群共享卷或Oracle集群文件系统。
消息传递与通信
用于集群节点间通信的两种广泛使用的方法是MPI(訊息傳遞介面)和PVM(并行虚拟机)。[18]
早在1989年MPI出现之前,PVM就在橡树岭国家实验室问世了。PVM必须直接安装在每个集群节点上,并提供一组软件库,将节点描绘成一个“并行虚拟机”。PVM为消息传递、任务和资源管理以及故障通知提供了一个运行时环境。PVM可以由用C、C++或Fortran等语言编写的用户程序使用。[18][19]
20世纪90年代初,在40个组织的讨论中产生了MPI。最初的努力得到了ARPA和国家科学基金会的支持。MPI的设计没有重新开始,而是利用了当时商业系统中可用的各种特性。MPI规范催生了具体的实现。MPI实现通常使用TCP/IP和套接字连接。[18] MPI现在是一种广泛使用的通信模型,它使并行程序能够用C、Fortran、Python等语言编写。[19] 因此,与提供具体实现的PVM不同,MPI是已经在诸如MPICH和Open MPI的系统中实现的规范。[19][20]
集群管理

使用计算机集群服务器的挑战之一是管理它的成本,如果集群有N个节点,有时可能高达管理N个独立机器的成本。[21] 在某些情况下,这为管理成本较低的共享内存架构提供了一个优势。[21] 由于便于管理,这也使得虚拟机非常流行。[21]
任务调度
当大型多用户集群需要访问大量数据时,任务调度就成为一个挑战。在具有复杂应用环境的异构CPU-GPU集群中,每项作业的性能取决于底层集群的特性。因此,将任务映射到CPU内核和GPU设备有巨大的挑战。[22] 这是一个正在进行的研究领域;结合和扩展MapReduce和Hadoop的算法已经被提出和研究。[22]
节点故障管理
当集群中的一个节点出现故障时,可以使用诸如“fencing”(隔离)之类的策略来保持系统的其余部分可操作。[23][24] Fencing是在节点出现故障时隔离节点或保护共享资源的过程。有两类隔离方法;一类禁用节点本身,另一类禁用对资源(如共享磁盘)的访问。[23]
STONITH方法(Shoot The Other Node In The Head)是说禁用或关闭可疑的节点。例如,电源fencing使用电源控制器来关闭无法操作的节点。[23]
资源fencing方法不允许在不关闭节点电源的情况下访问资源。这可能包括通过SCSI3持久保留fencing,禁用光纤通道端口的光纤通道fencing,或禁用GNBD服务器访问的GNBD fencing。
软件开发和管理
并行编程
负载平衡集群(如Web服务器)使用集群架构来支持大量用户,通常每个用户请求都被路由到一个特定的节点,实现无需多节点协作的任务并行,因为系统的主要目标是让用户快速访问共享数据。然而,为少数用户执行复杂计算的"计算机集群"需要利用集群的并行处理能力,在多个节点之间划分"相同的计算"。[25]
程序的自动并行化仍然是一个技术挑战,但是并行编程模型可以通过在不同的处理器上同时执行程序的不同部分来实现更高程度的并行性。[25][26]
调试和监控
在集群上开发和调试并行程序需要并行语言原语以及合适的工具,例如高性能调试论坛(HPDF)所讨论的那些工具,HPD规范就是这样产生的。[19][27] 像TotalView这样的工具是为了在使用MPI或PVM进行消息传递的计算机集群上调试并行实现而开发的。
Berkeley NOW(Network of Workstations)系统收集集群数据并将其存储在数据库中,而在印度开发的PARMON系统允许对大型集群进行可视化观察和管理。[19]
当一个节点在长时间的多节点计算中失败时,可以使用应用程序检查点来恢复给定的系统状态。[28] 这在大型集群中是必不可少的,因为随着节点数量的增加,在繁重的计算负载下节点失败的可能性也会增加。检查点可以将系统恢复到稳定状态,这样处理就可以在不重新计算结果的情况下继续进行。[28]
一些实现
GNU/Linux世界提供了各种集群软件;对于应用程序集群,有distcc和MPICH。Linux Virtual Server, Linux-HA等基于导向器的集群,允许传入的服务请求分布在多个集群节点上。MOSIX、LinuxPMI、Kerrighed、OpenSSI都是集成到内核中的成熟集群,它们可在同类节点之间自动进行进程迁移。OpenSSI、openMosix和Kerrighed是单系统映像实现。
基于Windows Server平台的Microsoft Windows计算机群集Server 2003为高性能计算提供了诸如Job Scheduler、MSMPI库和管理工具。
gLite是E-sciencE网格计划(EGEE)创建的一组中间件技术。
slurm还用于调度和管理一些最大的超级计算机集群(参见top500列表)。
参见
|
基本概念 分布式计算 |
具体系统 计算工厂 |
参考资料
- . Stack Overflow. [2019-02-07]. (原始内容存档于2019-09-20).
- Bader, David; Pennington, Robert. . Georgia Tech College of Computing. May 2001 [2017-02-28]. (原始内容存档于2007-12-21).
- . The Telegraph. 2012-06-18 [2012-06-18]. (原始内容存档于2020-04-13).
- Gray, Jim; Rueter, Andreas. . Morgan Kaufmann Publishers. 1993. ISBN 1558601902.
- : 375. ISBN 3-540-74572-6.
- William W. Hargrove, Forrest M. Hoffman and Thomas Sterling. . Scientific American 265 (2). 2001-08-16: 72–79 [2011-10-18]. (原始内容存档于2019-12-10).
- Hargrove, William W.; Hoffman, Forrest M. . Linux Magazine. 1999 [2011-10-18]. (原始内容存档于2011-10-18).
- Yokokawa, Mitsuo; et al. . International Symposium on Low Power Electronics and Design (ISLPED): 371–372. 1–3 August 2011 [2019-02-07]. doi:10.1109/ISLPED.2011.5993668. (原始内容存档于2019-02-13).
- Pfister, Gregory. 2nd. Upper Saddle River, NJ: Prentice Hall PTR. 1998: 36. ISBN 0-13-899709-8.
- Hill, Mark Donald; Jouppi, Norman Paul; Sohi, Gurindar. . 1999: 41–48. ISBN 978-1-55860-539-8.
- Sloan, Joseph D. . 2004. ISBN 0-596-00570-9.
- Daydé, Michel; Dongarra, Jack. . 2005: 120–121. ISBN 3-540-25424-2.
- . IBM. [2014-09-08]. (原始内容存档于2016-04-29).
- . Microsoft. 2003-03-28 [2014-09-08]. (原始内容存档于2016-04-22).
- Hamada, Tsuyoshi; et al. . Computer Science - Research and Development. 2009, 24: 21–31. doi:10.1007/s00450-009-0089-1.
- Mauer, Ryan. . Linux Journal. 2006-01-12 [2017-06-02]. (原始内容存档于2019-05-03).
- Milicchio, Franco; Gehrke, Wolfgang Alexander. . 2007: 339–341 [2019-02-07]. ISBN 9783540366348. (原始内容存档于2019-06-05).
- Prabhu, C.S.R. . 2008: 109–112 [2019-02-07]. ISBN 8120334280. (原始内容存档于2018-11-27).
- Gropp, William; Lusk, Ewing; Skjellum, Anthony. . Parallel Computing. 1996. CiteSeerX 10.1.1.102.9485
 .
. - Patterson, David A.; Hennessy, John L. . 2011: 641–642. ISBN 0-12-374750-3.
- K. Shirahata; et al. . Cloud Computing Technology and Science (CloudCom): 733–740. 30 Nov – 3 Dec 2010 [2019-02-07]. ISBN 978-1-4244-9405-7. doi:10.1109/CloudCom.2010.55. (原始内容存档于2014-10-11).
- Robertson, Alan. (PDF). IBM Linux Research Center. 2010.
- Vargas, Enrique; Bianco, Joseph; Deeths, David. . Prentice Hall Professional. 2001: 58 [2019-02-07]. ISBN 9780130418708. (原始内容存档于2021-02-26).
- Aho, Alfred V.; Blum, Edward K. . 2011: 156–166. ISBN 1-4614-1167-X.
- Rauber, Thomas; Rünger, Gudula. . 2010: 94–95. ISBN 3-642-04817-X.
- Francioni, Joan M.; Pancake, Cherri M. . Scientific Programming (Amsterdam, Netherlands: IOS Press). April 2000, 8 (2): 95–108 [2019-02-07]. ISSN 1058-9244. doi:10.1155/2000/971291. (原始内容存档于2018-12-02).
- Sloot, Peter (编). : 291–292. 2003. ISBN 3-540-40195-4.
延伸阅读
- Baker, Mark; et al. . 11 Jan 2001. arXiv:cs/0004014 .
- Marcus, Evan; Stern, Hal. . John Wiley & Sons. 2000. ISBN 0-471-35601-8.
- Pfister, Greg. . Prentice Hall. 1998. ISBN 0-13-899709-8.
- Buyya, Rajkumar (编). 1. NJ, USA: Prentice Hall. 1999. ISBN 0-13-013784-7.
- Buyya, Rajkumar (编). 2. NJ, USA: Prentice Hall. 1999. ISBN 0-13-013785-5.
外部链接
| 维基共享资源中相关的多媒体资源:计算机集群 |
- IEEE Technical Committee on Scalable Computing (TCSC)
- Reliable Scalable Cluster Technology, IBM
- Tivoli System Automation Wiki(页面存档备份,存于)
- Large-scale cluster management at Google with Borg(页面存档备份,存于), April 2015, by Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune and John Wilkes