K-d树
在计算机科学里,k-d树(k-维树的缩写)是在k维欧几里德空间组织点的数据结构。k-d树可以使用在多种应用场合,如多维键值搜索(例:范围搜寻及最邻近搜索)。k-d树是空间二分树的一种特殊情况。
| k-d 树 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 类型 | 多维 二叉搜索树 | ||||||||||||||||||||
| 发明时间 | 1975年 | ||||||||||||||||||||
| 发明者 | 喬恩·本特利 | ||||||||||||||||||||
| 用大O符号表示的时间复杂度 | |||||||||||||||||||||
| |||||||||||||||||||||


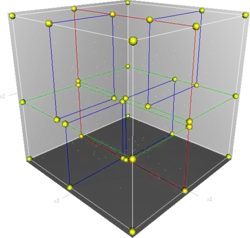
一个三维k-d树。第一次划分(红色)把根节点(白色)划分成两个节点,然后它们分别再次被划分(绿色)为两个子节点。最后这四个子节点的每一个都被划分(蓝色)为两个子节点。因为没有更进一步的划分,最后得到的八个节点称为叶子节点。
简介
k-d树是每个叶子节点都为k维点的二叉树。所有非叶子节点可以视作用一个超平面把空间分割成两个半空间。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。选择超平面的方法如下:每个节点都与k维中垂直于超平面的那一维有关。因此,如果选择按照x轴划分,所有x值小于指定值的节点都会出现在左子树,所有x值大于指定值的节点都会出现在右子树。这样,超平面可以用该x值来确定,其法線为x轴的单位向量。
k-d树的运算
建立k-d树
有很多种方法可以选择轴垂直分割面(axis-aligned splitting planes),所以有很多种建立k-d树的方法。 最典型的方法如下:
- 随着树的深度轮流选择轴当作分割面。(例如:在三维空间中根节点是 x 轴垂直分割面,其子节点皆为 y 轴垂直分割面,其孙节点皆为 z 轴垂直分割面,其曾孙节点则皆为 x 轴垂直分割面,依此类推。)
- 点由垂直分割面之軸座標的中位数区分并放入子树
這個方法產生一個平衡的k-d樹。每個葉節點的高度都十分接近。然而,平衡的樹不一定對每個應用都是最佳的。
function kdtree (list of points pointList, int depth)
{
// Select axis based on depth so that axis cycles through all valid values
var int axis := depth mod k;
// Sort point list and choose median as pivot element
select median by axis from pointList;
// Create node and construct subtrees
var tree_node node;
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}
平衡
在动态插入删除点且不允许预处理插入操作的情况下,一种平衡的方法是使用类似替罪羊树的方法重构整棵树。
最鄰近搜索
最鄰近搜索用來找出在樹中與輸入點最接近的點。
k-d樹最鄰近搜索的過程如下:
- 從根節點開始,遞迴的往下移。往左還是往右的決定方法與插入元素的方法一樣(如果输入点在分区面的左邊則進入左子節點,在右邊則進入右子節點)。
- 一旦移動到葉節點,將該節點當作"目前最佳點"。
- 解開遞迴,並對每個經過的節點執行下列步驟:
- 如果目前所在點比目前最佳點更靠近輸入點,則將其變為目前最佳點。
- 檢查另一邊子樹有沒有更近的點,如果有則從該節點往下找
- 當根節點搜尋完畢後完成最鄰近搜尋
处理高维数据
维数灾难让大部分的搜索算法在高维情况下都显得花俏且不实用。 同样的,在高维空间中,k-d树也不能做很高效的最邻近搜索。一般的准则是:在k维情况下,数据点数目N应当远远大于时,k-d树的最邻近搜索才可以很好的发挥其作用。不然的话,大部分的点都会被查询,最终算法效率也不会比全体查询一遍要好到哪里去。另外,如果只是需要一个足够快,且不必最优的结果,那么可以考虑使用近似邻近查询的方法。

外部链接
- libkdtree++, an open-source STL-like implementation of k-d trees in C++.
- A tutorial on KD Trees
- A C++ implementation of k-d trees for 3D point clouds, part of the Mobile Robot Programming Toolkit (MRPT)
- kdtree (页面存档备份,存于) A simple C library for working with KD-Trees
- K-D Tree Demo, Java applet (页面存档备份,存于)
- libANN (页面存档备份,存于) Approximate Nearest Neighbour Library includes a k-d tree implementation
- Caltech Large Scale Image Search Toolbox: a Matlab toolbox implementing randomized k-d tree for fast approximate nearest neighbour search, in addition to LSH, Hierarchical K-Means, and Inverted File search algorithms.
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.