In numerical linear algebra, the Arnoldi iteration is an eigenvalue algorithm and an important example of an iterative method. Arnoldi finds an approximation to the eigenvalues and eigenvectors of general (possibly non-Hermitian) matrices by constructing an orthonormal basis of the Krylov subspace, which makes it particularly useful when dealing with large sparse matrices.
The Arnoldi method belongs to a class of linear algebra algorithms that give a partial result after a small number of iterations, in contrast to so-called direct methods which must complete to give any useful results (see for example, Householder transformation). The partial result in this case being the first few vectors of the basis the algorithm is building.
When applied to Hermitian matrices it reduces to the Lanczos algorithm. The Arnoldi iteration was invented by W. E. Arnoldi in 1951.[1]
Krylov subspaces and the power iteration
An intuitive method for finding the largest (in absolute value) eigenvalue of a given m × m matrix is the power iteration: starting with an arbitrary initial vector b, calculate Ab, A2b, A3b, ... normalizing the result after every application of the matrix A.

This sequence converges to the eigenvector corresponding to the eigenvalue with the largest absolute value, . However, much potentially useful computation is wasted by using only the final result, . This suggests that instead, we form the so-called Krylov matrix:



The columns of this matrix are not in general orthogonal, but we can extract an orthogonal basis, via a method such as Gram–Schmidt orthogonalization. The resulting set of vectors is thus an orthogonal basis of the Krylov subspace, . We may expect the vectors of this basis to span good approximations of the eigenvectors corresponding to the largest eigenvalues, for the same reason that approximates the dominant eigenvector.


The Arnoldi iteration
The Arnoldi iteration uses the modified Gram–Schmidt process to produce a sequence of orthonormal vectors, q1, q2, q3, ..., called the Arnoldi vectors, such that for every n, the vectors q1, ..., qn span the Krylov subspace . Explicitly, the algorithm is as follows:
Start with an arbitrary vector q1 with norm 1.
Repeat for k = 2, 3, ...
qk := A qk−1
for j from 1 to k − 1
hj,k−1 := qj* qk
qk := qk − hj,k−1 qj
hk,k−1 := ‖qk‖
qk := qk / hk,k−1
The j-loop projects out the component of in the directions of . This ensures the orthogonality of all the generated vectors.


The algorithm breaks down when qk is the zero vector. This happens when the minimal polynomial of A is of degree k. In most applications of the Arnoldi iteration, including the eigenvalue algorithm below and GMRES, the algorithm has converged at this point.
Every step of the k-loop takes one matrix-vector product and approximately 4mk floating point operations.
In the programming language Python with support of the NumPy library:
import numpy as np
def arnoldi_iteration(A, b, n: int):
"""Compute a basis of the (n + 1)-Krylov subspace of the matrix A.
This is the space spanned by the vectors {b, Ab, ..., A^n b}.
Parameters
----------
A : array_like
An m × m array.
b : array_like
Initial vector (length m).
n : int
One less than the dimension of the Krylov subspace, or equivalently the *degree* of the Krylov space. Must be >= 1.
Returns
-------
Q : numpy.array
An m x (n + 1) array, where the columns are an orthonormal basis of the Krylov subspace.
h : numpy.array
An (n + 1) x n array. A on basis Q. It is upper Hessenberg.
"""
eps = 1e-12
h = np.zeros((n + 1, n))
Q = np.zeros((A.shape[0], n + 1))
# Normalize the input vector
Q[:, 0] = b / np.linalg.norm(b, 2) # Use it as the first Krylov vector
for k in range(1, n + 1):
v = np.dot(A, Q[:, k - 1]) # Generate a new candidate vector
for j in range(k): # Subtract the projections on previous vectors
h[j, k - 1] = np.dot(Q[:, j].conj(), v)
v = v - h[j, k - 1] * Q[:, j]
h[k, k - 1] = np.linalg.norm(v, 2)
if h[k, k - 1] > eps: # Add the produced vector to the list, unless
Q[:, k] = v / h[k, k - 1]
else: # If that happens, stop iterating.
return Q, h
return Q, h
Properties of the Arnoldi iteration
Let Qn denote the m-by-n matrix formed by the first n Arnoldi vectors q1, q2, ..., qn, and let Hn be the (upper Hessenberg) matrix formed by the numbers hj,k computed by the algorithm:

The orthogonalization method has to be specifically chosen such that the lower Arnoldi/Krylov components are removed from higher Krylov vectors. As can be expressed in terms of q1, ..., qi+1 by construction, they are orthogonal to qi+2, ..., qn,

We then have

The matrix Hn can be viewed as A in the subspace with the Arnoldi vectors as an orthogonal basis; A is orthogonally projected onto . The matrix Hn can be characterized by the following optimality condition. The characteristic polynomial of Hn minimizes ||p(A)q1||2 among all monic polynomials of degree n. This optimality problem has a unique solution if and only if the Arnoldi iteration does not break down.
The relation between the Q matrices in subsequent iterations is given by

where

is an (n+1)-by-n matrix formed by adding an extra row to Hn.
Finding eigenvalues with the Arnoldi iteration
The idea of the Arnoldi iteration as an eigenvalue algorithm is to compute the eigenvalues in the Krylov subspace. The eigenvalues of Hn are called the Ritz eigenvalues. Since Hn is a Hessenberg matrix of modest size, its eigenvalues can be computed efficiently, for instance with the QR algorithm, or somewhat related, Francis' algorithm. Also Francis' algorithm itself can be considered to be related to power iterations, operating on nested Krylov subspace. In fact, the most basic form of Francis' algorithm appears to be to choose b to be equal to Ae1, and extending n to the full dimension of A. Improved versions include one or more shifts, and higher powers of A may be applied in a single steps.[2]
This is an example of the Rayleigh-Ritz method.
It is often observed in practice that some of the Ritz eigenvalues converge to eigenvalues of A. Since Hn is n-by-n, it has at most n eigenvalues, and not all eigenvalues of A can be approximated. Typically, the Ritz eigenvalues converge to the largest eigenvalues of A. To get the smallest eigenvalues of A, the inverse (operation) of A should be used instead. This can be related to the characterization of Hn as the matrix whose characteristic polynomial minimizes ||p(A)q1|| in the following way. A good way to get p(A) small is to choose the polynomial p such that p(x) is small whenever x is an eigenvalue of A. Hence, the zeros of p (and thus the Ritz eigenvalues) will be close to the eigenvalues of A.
However, the details are not fully understood yet. This is in contrast to the case where A is Hermitian. In that situation, the Arnoldi iteration becomes the Lanczos iteration, for which the theory is more complete.
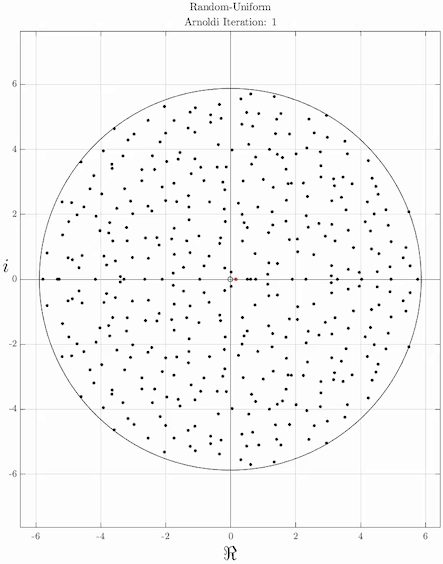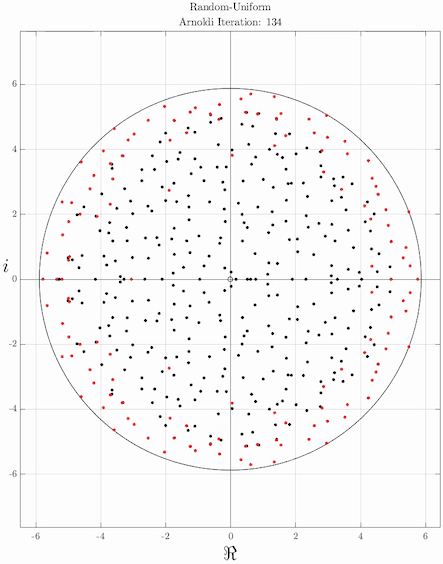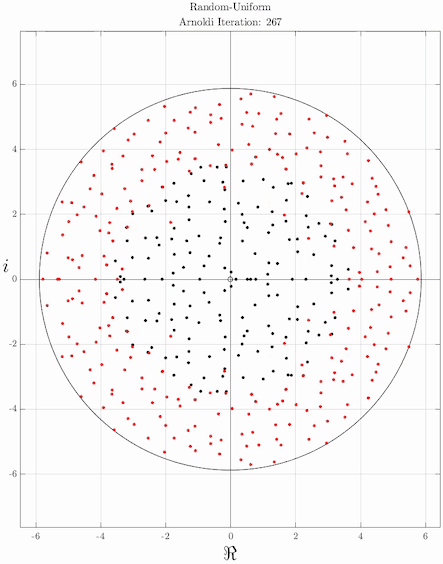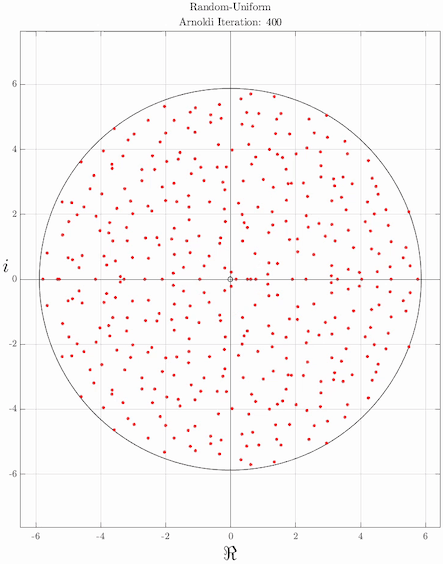
]
Implicitly restarted Arnoldi method (IRAM)
Due to practical storage consideration, common implementations of Arnoldi methods typically restart after some number of iterations. One major innovation in restarting was due to Lehoucq and Sorensen who proposed the Implicitly Restarted Arnoldi Method.[3] They also implemented the algorithm in a freely available software package called ARPACK.[4] This has spurred a number of other variations including Implicitly Restarted Lanczos method.[5][6][7] It also influenced how other restarted methods are analyzed.[8] Theoretical results have shown that convergence improves with an increase in the Krylov subspace dimension n. However, an a-priori value of n which would lead to optimal convergence is not known. Recently a dynamic switching strategy[9] has been proposed which fluctuates the dimension n before each restart and thus leads to acceleration in the rate of convergence.
See also
The generalized minimal residual method (GMRES) is a method for solving Ax = b based on Arnoldi iteration.
References
- ↑ Arnoldi, W. E. (1951). "The principle of minimized iterations in the solution of the matrix eigenvalue problem". Quarterly of Applied Mathematics. 9 (1): 17–29. doi:10.1090/qam/42792. ISSN 0033-569X.
- ↑ David S. Watkins. Francis' Algorithm Washington State University. Retrieved 14 December 2022
- ↑ R. B. Lehoucq & D. C. Sorensen (1996). "Deflation Techniques for an Implicitly Restarted Arnoldi Iteration". SIAM Journal on Matrix Analysis and Applications. 17 (4): 789–821. doi:10.1137/S0895479895281484. hdl:1911/101832.
- ↑ R. B. Lehoucq; D. C. Sorensen & C. Yang (1998). "ARPACK Users Guide: Solution of Large-Scale Eigenvalue Problems with Implicitly Restarted Arnoldi Methods". SIAM. Archived from the original on 2007-06-26. Retrieved 2007-06-30.
- ↑ D. Calvetti; L. Reichel & D.C. Sorensen (1994). "An Implicitly Restarted Lanczos Method for Large Symmetric Eigenvalue Problems". ETNA.
- ↑ E. Kokiopoulou; C. Bekas & E. Gallopoulos (2003). "An Implicitly Restarted Lanczos Bidiagonalization Method for Computing Smallest Singular Triplets" (PDF). SIAM.
- ↑ Zhongxiao Jia (2002). "The refined harmonic Arnoldi method and an implicitly restarted refined algorithm for computing interior eigenpairs of large matrices". Appl. Numer. Math. 42 (4): 489–512. doi:10.1016/S0168-9274(01)00132-5. S2CID 17172589.
- ↑ Andreas Stathopoulos and Yousef Saad and Kesheng Wu (1998). "Dynamic Thick Restarting of the Davidson, and the Implicitly Restarted Arnoldi Methods". SIAM Journal on Scientific Computing. 19: 227–245. doi:10.1137/S1064827596304162.
- ↑ K.Dookhitram, R. Boojhawon & M. Bhuruth (2009). "A New Method For Accelerating Arnoldi Algorithms For Large Scale Eigenproblems". Math. Comput. Simulat. 80 (2): 387–401. doi:10.1016/j.matcom.2009.07.009.
- W. E. Arnoldi, "The principle of minimized iterations in the solution of the matrix eigenvalue problem," Quarterly of Applied Mathematics, volume 9, pages 17–29, 1951.
- Yousef Saad, Numerical Methods for Large Eigenvalue Problems, Manchester University Press, 1992. ISBN 0-7190-3386-1.
- Lloyd N. Trefethen and David Bau, III, Numerical Linear Algebra, Society for Industrial and Applied Mathematics, 1997. ISBN 0-89871-361-7.
- Jaschke, Leonhard: Preconditioned Arnoldi Methods for Systems of Nonlinear Equations. (2004). ISBN 2-84976-001-3
- Implementation: Matlab comes with ARPACK built-in. Both stored and implicit matrices can be analyzed through the eigs() function.