Multi-level caches can be designed in various ways depending on whether the content of one cache is present in other levels of caches. If all blocks in the higher level cache are also present in the lower level cache, then the lower level cache is said to be inclusive of the higher level cache. If the lower level cache contains only blocks that are not present in the higher level cache, then the lower level cache is said to be exclusive of the higher level cache. If the contents of the lower level cache are neither strictly inclusive nor exclusive of the higher level cache, then it is called non-inclusive non-exclusive (NINE) cache.[1][2]
Inclusive Policy
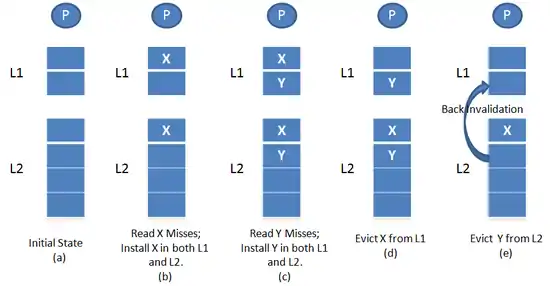
Consider an example of a two level cache hierarchy where L2 can be inclusive, exclusive or NINE of L1. Consider the case when L2 is inclusive of L1. Suppose there is a processor read request for block X. If the block is found in L1 cache, then the data is read from L1 cache and returned to the processor. If the block is not found in the L1 cache, but present in the L2 cache, then the cache block is fetched from the L2 cache and placed in L1. If this causes a block to be evicted from L1, there is no involvement of L2. If the block is not found in either L1 or L2, then it is fetched from the main memory and placed in both L1 and L2. Now, if there is an eviction from L2, the L2 cache sends a back invalidation to the L1 cache, so that inclusion is not violated.
As illustrated in Figure 1, initially consider both L1 and L2 caches to be empty (a). Assume that the processor sends a read X request. It will be a miss in both L1 and L2 and hence the block is brought into both L1 and L2 from the main memory as shown in (b). Now, assume the processor issues a read Y request which is a miss in both L1 and L2. So, block Y is placed in both L1 and L2 as shown in (c). If block X has to be evicted from L1, then it is removed from L1 only as shown in (d). If block Y has to be evicted from L2, it sends a back invalidation request to L1 and hence block Y is evicted from L1 as shown in (e).
In order for inclusion to hold, certain conditions need to be satisfied. L2 associativity must be greater than or equal to L1 associativity irrespective of the number of sets. The number of L2 sets must be greater than or equal to the number of L1 sets irrespective of L2 associativity. All reference information from L1 is passed to L2 so that it can update its replacement bits.
One example of inclusive cache is Intel quad core processor with 4x256KB L2 caches and 8MB (inclusive) L3 cache.[3]
Exclusive Policy
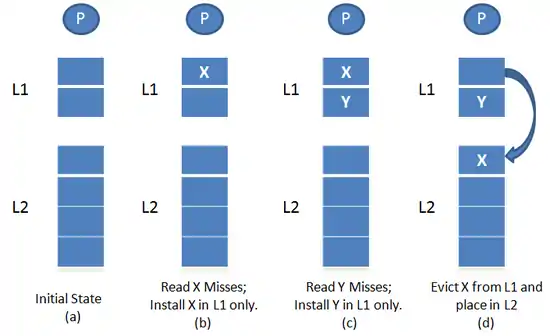
Consider the case when L2 is exclusive of L1. Suppose there is a processor read request for block X. If the block is found in L1 cache, then the data is read from L1 cache and returned to the processor. If the block is not found in the L1 cache, but present in the L2 cache, then the cache block is moved from the L2 cache to the L1 cache. If this causes a block to be evicted from L1, the evicted block is then placed into L2. This is the only way L2 gets populated. Here, L2 behaves like a victim cache. If the block is not found in either L1 or L2, then it is fetched from main memory and placed just in L1 and not in L2.
As illustrated in Figure 2, initially consider both L1 and L2 caches to be empty (a). Assume that the processor sends a read X request. It will be a miss in both L1 and L2 and hence the block is brought into L1 from the main memory as shown in (b). Now, again the processor issues a read Y request which is a miss in both L1 and L2. So, block Y is placed in L1 as shown in (c). If block X has to be evicted from L1, then it is removed from L1 and placed in L2 as shown in (d).
An example of exclusive cache is AMD Opteron with 512 KB (per core) L2 cache, exclusive of L1.[3]
NINE Policy
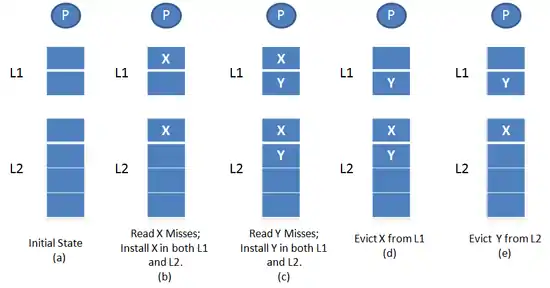
Consider the case when L2 is non-inclusive non-exclusive of L1. Suppose there is a processor read request for block X. If the block is found in L1 cache, then the data is read from L1 cache and returned to the processor. If the block is not found in the L1 cache, but present in the L2 cache, then the cache block is fetched from the L2 cache and placed in L1. If this causes a block to be evicted from L1, there is no involvement of L2, which is the same as in the case of inclusive policy. If the block is not found in both L1 and L2, then it is fetched from main memory and placed in both L1 and L2. Now, if there is an eviction from L2, unlike inclusive policy, there is no back invalidation.
As illustrated in Figure 3, initially consider both L1 and L2 caches to be empty (a). Assume that the processor sends a read X request. It will be a miss in both L1 and L2 and hence the block is brought into both L1 and L2 from the main memory as shown in (b). Now, again the processor issues a read Y request which is a miss in both L1 and L2. So, block Y is placed in both L1 and L2 as shown in (c). If block X has to be evicted from L1, then it is removed from L1 only as shown in (d). If block Y has to be evicted from L2, it is evicted from L2 only as shown in (e).
An example of non-inclusive non-exclusive cache is AMD Opteron with non-inclusive L3 cache of 6 MB (shared).[3]
Comparison
The merit of inclusive policy is that, in parallel systems with per-processor private cache if there is a cache miss other peer caches are checked for the block. If the lower level cache is inclusive of the higher level cache and it is a miss in the lower level cache, then the higher level cache need not be searched. This implies a shorter miss latency for an inclusive cache compared to exclusive and NINE.[1]
A drawback of an inclusive policy is that the unique memory capacity of the cache is determined by the lower level cache. Unlike the case of exclusive cache, where the unique memory capacity is the combined capacity of all caches in the hierarchy.[4] If the size of lower level cache is small and comparable with the size of higher level cache, there is more wasted cache capacity in inclusive caches. Although the exclusive cache has more unique memory capacity, it uses more bandwidth since it suffers from a higher rate of filling of new blocks (equal to the rate of higher level cache's misses) as compared to NINE cache which is filled with a new block only when it suffers a miss. Therefore, assessment of cost relative to benefit needs to be done while exploiting the choice between Inclusive, Exclusive and NINE caches.
Value Inclusion: It is not necessary for a block to have same data values when it is cached in both higher and lower level caches even though inclusion is maintained. But, if the data values are the same, value inclusion is maintained.[1] This depends on the write policy in use, as write back policy does not notify the lower level cache of the changes made to the block in higher level cache. However, in case of write-through cache there is no such concern.
References
- 1 2 3 Solihin, Yan (2016). Fundamentals of Parallel Multicore Architecture. Chapman and Hall/CRC. pp. 146–150. ISBN 9781482211184.
- ↑ Culler, David; Gupta, Anoop; Singh, Jaswinder Pal (1999). Parallel Computer Architecture: A Hardware/Software Approach. San Francisco: Morgan Kaufmann Publishers. pp. 369–372. ISBN 1558603433.
- 1 2 3 "Comparing Cache Architectures and Coherency Protocols on x86-64 Multicore SMP Systems". Proceedings of the 42nd International Symposium on Microarchitecture. MICRO’09.
- ↑ Ying Zheng; Davis, B.T.; Jordan, M. (2004). "Performance evaluation of exclusive cache hierarchies". IEEE International Symposium on - ISPASS Performance Analysis of Systems and Software, 2004. pp. 89–96. doi:10.1109/ISPASS.2004.1291359. ISBN 0-7803-8385-0. S2CID 10784219.