Causal inference is the process of determining the independent, actual effect of a particular phenomenon that is a component of a larger system. The main difference between causal inference and inference of association is that causal inference analyzes the response of an effect variable when a cause of the effect variable is changed.[1][2] The study of why things occur is called etiology, and can be described using the language of scientific causal notation. Causal inference is said to provide the evidence of causality theorized by causal reasoning.
Causal inference is widely studied across all sciences. Several innovations in the development and implementation of methodology designed to determine causality have proliferated in recent decades. Causal inference remains especially difficult where experimentation is difficult or impossible, which is common throughout most sciences.
The approaches to causal inference are broadly applicable across all types of scientific disciplines, and many methods of causal inference that were designed for certain disciplines have found use in other disciplines. This article outlines the basic process behind causal inference and details some of the more conventional tests used across different disciplines; however, this should not be mistaken as a suggestion that these methods apply only to those disciplines, merely that they are the most commonly used in that discipline.
Causal inference is difficult to perform and there is significant debate amongst scientists about the proper way to determine causality. Despite other innovations, there remain concerns of misattribution by scientists of correlative results as causal, of the usage of incorrect methodologies by scientists, and of deliberate manipulation by scientists of analytical results in order to obtain statistically significant estimates. Particular concern is raised in the use of regression models, especially linear regression models.
Definition
Inferring the cause of something has been described as:
- "...reason[ing] to the conclusion that something is, or is likely to be, the cause of something else".[3]
- "Identification of the cause or causes of a phenomenon, by establishing covariation of cause and effect, a time-order relationship with the cause preceding the effect, and the elimination of plausible alternative causes."[4]
Methodology
General
Causal inference is conducted via the study of systems where the measure of one variable is suspected to affect the measure of another. Causal inference is conducted with regard to the scientific method. The first step of causal inference is to formulate a falsifiable null hypothesis, which is subsequently tested with statistical methods. Frequentist statistical inference is the use of statistical methods to determine the probability that the data occur under the null hypothesis by chance; Bayesian inference is used to determine the effect of an independent variable.[5] Statistical inference is generally used to determine the difference between variations in the original data that are random variation or the effect of a well-specified causal mechanism. Notably, correlation does not imply causation, so the study of causality is as concerned with the study of potential causal mechanisms as it is with variation amongst the data. A frequently sought after standard of causal inference is an experiment wherein treatment is randomly assigned but all other confounding factors are held constant. Most of the efforts in causal inference are in the attempt to replicate experimental conditions.
Epidemiological studies employ different epidemiological methods of collecting and measuring evidence of risk factors and effect and different ways of measuring association between the two. Results of a 2020 review of methods for causal inference found that using existing literature for clinical training programs can be challenging. This is because published articles often assume an advanced technical background, they may be written from multiple statistical, epidemiological, computer science, or philosophical perspectives, methodological approaches continue to expand rapidly, and many aspects of causal inference receive limited coverage.[6]
Common frameworks for causal inference include the causal pie model (component-cause), Pearl's structural causal model (causal diagram + do-calculus), structural equation modeling, and Rubin causal model (potential-outcome), which are often used in areas such as social sciences and epidemiology.[7]
Experimental
Experimental verification of causal mechanisms is possible using experimental methods. The main motivation behind an experiment is to hold other experimental variables constant while purposefully manipulating the variable of interest. If the experiment produces statistically significant effects as a result of only the treatment variable being manipulated, there is grounds to believe that a causal effect can be assigned to the treatment variable, assuming that other standards for experimental design have been met.
Quasi-experimental
Quasi-experimental verification of causal mechanisms is conducted when traditional experimental methods are unavailable. This may be the result of prohibitive costs of conducting an experiment, or the inherent infeasibility of conducting an experiment, especially experiments that are concerned with large systems such as economies of electoral systems, or for treatments that are considered to present a danger to the well-being of test subjects. Quasi-experiments may also occur where information is withheld for legal reasons.
Approaches in epidemiology
Epidemiology studies patterns of health and disease in defined populations of living beings in order to infer causes and effects. An association between an exposure to a putative risk factor and a disease may be suggestive of, but is not equivalent to causality because correlation does not imply causation. Historically, Koch's postulates have been used since the 19th century to decide if a microorganism was the cause of a disease. In the 20th century the Bradford Hill criteria, described in 1965[8] have been used to assess causality of variables outside microbiology, although even these criteria are not exclusive ways to determine causality.
In molecular epidemiology the phenomena studied are on a molecular biology level, including genetics, where biomarkers are evidence of cause or effects.
A recent trend is to identify evidence for influence of the exposure on molecular pathology within diseased tissue or cells, in the emerging interdisciplinary field of molecular pathological epidemiology (MPE). Linking the exposure to molecular pathologic signatures of the disease can help to assess causality. Considering the inherent nature of heterogeneity of a given disease, the unique disease principle, disease phenotyping and subtyping are trends in biomedical and public health sciences, exemplified as personalized medicine and precision medicine.
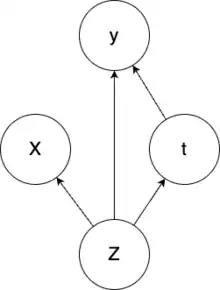
Causal Inference has also been used for treatment effect estimation. Assuming a set of observable patient symptoms(X) caused by a set of hidden causes(Z) we can choose to give or not a treatment t. The result of the giving or not giving the treatment is the effect estimation y. If the treatment is not guaranteed to have a positive effect then the decision whether the treatment should be applied or not depends firstly on expert knowledge that encompasses the causal connections. For novel diseases, this expert knowledge may not be available. As a result, we rely solely on past treatment outcomes to make decisions. A modified variational autoencoder can be used to model the causal graph described above.[9] While the above scenario could be modelled without the use of the hidden confounder(Z) we would lose the insight that the symptoms a patient together with other factors impacts both the treatment assignment and the outcome.
Approaches in computer science
Determination of cause and effect from joint observational data for two time-independent variables, say X and Y, has been tackled using asymmetry between evidence for some model in the directions, X → Y and Y → X. The primary approaches are based on Algorithmic information theory models and noise models.
Noise models
Incorporate an independent noise term in the model to compare the evidences of the two directions.
Here are some of the noise models for the hypothesis Y → X with the noise E:
- Additive noise:[10]
- Linear noise:[11]
- Post-nonlinear:[12]
- Heteroskedastic noise:
- Functional noise:[13]





The common assumption in these models are:
- There are no other causes of Y.
- X and E have no common causes.
- Distribution of cause is independent from causal mechanisms.
On an intuitive level, the idea is that the factorization of the joint distribution P(Cause, Effect) into P(Cause)*P(Effect | Cause) typically yields models of lower total complexity than the factorization into P(Effect)*P(Cause | Effect). Although the notion of "complexity" is intuitively appealing, it is not obvious how it should be precisely defined.[13] A different family of methods attempt to discover causal "footprints" from large amounts of labeled data, and allow the prediction of more flexible causal relations.[14]
Approaches in social sciences
Social science
The social sciences in general have moved increasingly toward including quantitative frameworks for assessing causality. Much of this has been described as a means of providing greater rigor to social science methodology. Political science was significantly influenced by the publication of Designing Social Inquiry, by Gary King, Robert Keohane, and Sidney Verba, in 1994. King, Keohane, and Verba recommend that researchers apply both quantitative and qualitative methods and adopt the language of statistical inference to be clearer about their subjects of interest and units of analysis.[15][16] Proponents of quantitative methods have also increasingly adopted the potential outcomes framework, developed by Donald Rubin, as a standard for inferring causality.
While much of the emphasis remains on statistical inference in the potential outcomes framework, social science methodologists have developed new tools to conduct causal inference with both qualitative and quantitative methods, sometimes called a "mixed methods" approach.[17][18] Advocates of diverse methodological approaches argue that different methodologies are better suited to different subjects of study. Sociologist Herbert Smith and Political Scientists James Mahoney and Gary Goertz have cited the observation of Paul Holland, a statistician and author of the 1986 article "Statistics and Causal Inference", that statistical inference is most appropriate for assessing the "effects of causes" rather than the "causes of effects".[19][20] Qualitative methodologists have argued that formalized models of causation, including process tracing and fuzzy set theory, provide opportunities to infer causation through the identification of critical factors within case studies or through a process of comparison among several case studies.[16] These methodologies are also valuable for subjects in which a limited number of potential observations or the presence of confounding variables would limit the applicability of statistical inference.
Economics and political science
In the economic sciences and political sciences causal inference is often difficult, owing to the real world complexity of economic and political realities and the inability to recreate many large-scale phenomena within controlled experiments. Causal inference in the economic and political sciences continues to see improvement in methodology and rigor, due to the increased level of technology available to social scientists, the increase in the number of social scientists and research, and improvements to causal inference methodologies throughout social sciences.[21]
Despite the difficulties inherent in determining causality in economic systems, several widely employed methods exist throughout those fields.
Theoretical methods
Economists and political scientists can use theory (often studied in theory-driven econometrics) to estimate the magnitude of supposedly causal relationships in cases where they believe a causal relationship exists.[22] Theorists can presuppose a mechanism believed to be causal and describe the effects using data analysis to justify their proposed theory. For example, theorists can use logic to construct a model, such as theorizing that rain causes fluctuations in economic productivity but that the converse is not true.[23] However, using purely theoretical claims that do not offer any predictive insights has been called "pre-scientific" because there is no ability to predict the impact of the supposed causal properties.[5] It is worth reiterating that regression analysis in the social science does not inherently imply causality, as many phenomena may correlate in the short run or in particular datasets but demonstrate no correlation in other time periods or other datasets. Thus, the attribution of causality to correlative properties is premature absent a well defined and reasoned causal mechanism.
Instrumental variables
The instrumental variables (IV) technique is a method of determining causality that involves the elimination of a correlation between one of a model's explanatory variables and the model's error term. This method presumes that if a model's error term moves similarly with the variation of another variable, then the model's error term is probably an effect of variation in that explanatory variable. The elimination of this correlation through the introduction of a new instrumental variable thus reduces the error present in the model as a whole.[24]
Model specification
Model specification is the act of selecting a model to be used in data analysis. Social scientists (and, indeed, all scientists) must determine the correct model to use because different models are good at estimating different relationships.[25]
Model specification can be useful in determining causality that is slow to emerge, where the effects of an action in one period are only felt in a later period. It is worth remembering that correlations only measure whether two variables have similar variance, not whether they affect one another in a particular direction; thus, one cannot determine the direction of a causal relation based on correlations only. Because causal acts are believed to precede causal effects, social scientists can use a model that looks specifically for the effect of one variable on another over a period of time. This leads to using the variables representing phenomena happening earlier as treatment effects, where econometric tests are used to look for later changes in data that are attributed to the effect of such treatment effects, where a meaningful difference in results following a meaningful difference in treatment effects may indicate causality between the treatment effects and the measured effects (e.g., Granger-causality tests). Such studies are examples of time-series analysis.[26]
Sensitivity analysis
Other variables, or regressors in regression analysis, are either included or not included across various implementations of the same model to ensure that different sources of variation can be studied more separately from one another. This is a form of sensitivity analysis: it is the study of how sensitive an implementation of a model is to the addition of one or more new variables.[27]
A chief motivating concern in the use of sensitivity analysis is the pursuit of discovering confounding variables. Confounding variables are variables that have a large impact on the results of a statistical test but are not the variable that causal inference is trying to study. Confounding variables may cause a regressor to appear to be significant in one implementation, but not in another.
Multicollinearity
Another reason for the use of sensitivity analysis is to detect multicollinearity. Multicollinearity is the phenomenon where the correlation between two variables is very high. A high level of correlation between two variables can dramatically affect the outcome of a statistical analysis, where small variations in highly correlated data can flip the effect of a variable from a positive direction to a negative direction, or vice versa. This is an inherent property of variance testing. Determining multicollinearity is useful in sensitivity analysis because the elimination of highly correlated variables in different model implementations can prevent the dramatic changes in results that result from the inclusion of such variables.[28]
However, there are limits to sensitivity analysis' ability to prevent the deleterious effects of multicollinearity, especially in the social sciences, where systems are complex. Because it is theoretically impossible to include or even measure all of the confounding factors in a sufficiently complex system, econometric models are susceptible to the common-cause fallacy, where causal effects are incorrectly attributed to the wrong variable because the correct variable was not captured in the original data. This is an example of the failure to account for a lurking variable.[29]
Design-based econometrics
Recently, improved methodology in design-based econometrics has popularized the use of both natural experiments and quasi-experimental research designs to study the causal mechanisms that such experiments are believed to identify.[30]
Malpractice in causal inference
Despite the advancements in the development of methodologies used to determine causality, significant weaknesses in determining causality remain. These weaknesses can be attributed both to the inherent difficulty of determining causal relations in complex systems but also to cases of scientific malpractice.
Separate from the difficulties of causal inference, the perception that large numbers of scholars in the social sciences engage in non-scientific methodology exists among some large groups of social scientists. Criticism of economists and social scientists as passing off descriptive studies as causal studies are rife within those fields.[5]
Scientific malpractice and flawed methodology
In the sciences, especially in the social sciences, there is concern among scholars that scientific malpractice is widespread. As scientific study is a broad topic, there are theoretically limitless ways to have a causal inference undermined through no fault of a researcher. Nonetheless, there remain concerns among scientists that large numbers of researchers do not perform basic duties or practice sufficiently diverse methods in causal inference.[31][21][32][33]
One prominent example of common non-causal methodology is the erroneous assumption of correlative properties as causal properties. There is no inherent causality in phenomena that correlate. Regression models are designed to measure variance within data relative to a theoretical model: there is nothing to suggest that data that presents high levels of covariance have any meaningful relationship (absent a proposed causal mechanism with predictive properties or a random assignment of treatment). The use of flawed methodology has been claimed to be widespread, with common examples of such malpractice being the overuse of correlative models, especially the overuse of regression models and particularly linear regression models.[5] The presupposition that two correlated phenomena are inherently related is a logical fallacy known as spurious correlation. Some social scientists claim that widespread use of methodology that attributes causality to spurious correlations have been detrimental to the integrity of the social sciences, although improvements stemming from better methodologies have been noted.[30]
A potential effect of scientific studies that erroneously conflate correlation with causality is an increase in the number of scientific findings whose results are not reproducible by third parties. Such non-reproducibility is a logical consequence of findings that correlation only temporarily being overgeneralized into mechanisms that have no inherent relationship, where new data does not contain the previous, idiosyncratic correlations of the original data. Debates over the effect of malpractice versus the effect of the inherent difficulties of searching for causality are ongoing.[34] Critics of widely practiced methodologies argue that researchers have engaged statistical manipulation in order to publish articles that supposedly demonstrate evidence of causality but are actually examples of spurious correlation being touted as evidence of causality: such endeavors may be referred to as P hacking.[35] To prevent this, some have advocated that researchers preregister their research designs prior to conducting to their studies so that they do not inadvertently overemphasize a nonreproducible finding that was not the initial subject of inquiry but was found to be statistically significant during data analysis.[36]
See also
References
- ↑ Pearl, Judea (1 January 2009). "Causal inference in statistics: An overview" (PDF). Statistics Surveys. 3: 96–146. doi:10.1214/09-SS057. Archived (PDF) from the original on 6 August 2010. Retrieved 24 September 2012.
- ↑ Morgan, Stephen; Winship, Chris (2007). Counterfactuals and Causal inference. Cambridge University Press. ISBN 978-0-521-67193-4.
- ↑ "causal inference". Encyclopædia Britannica, Inc. Archived from the original on 3 May 2015. Retrieved 24 August 2014.
- ↑ John Shaughnessy; Eugene Zechmeister; Jeanne Zechmeister (2000). Research Methods in Psychology. McGraw-Hill Humanities/Social Sciences/Languages. pp. Chapter 1 : Introduction. ISBN 978-0077825362. Archived from the original on 15 October 2014. Retrieved 24 August 2014.
- 1 2 3 4 Schrodt, Philip A (1 March 2014). "Seven deadly sins of contemporary quantitative political analysis". Journal of Peace Research. 51 (2): 287–300. doi:10.1177/0022343313499597. ISSN 0022-3433. S2CID 197658213. Archived from the original on 15 August 2021. Retrieved 16 February 2021.
- ↑ Landsittel, Douglas; Srivastava, Avantika; Kropf, Kristin (2020). "A Narrative Review of Methods for Causal Inference and Associated Educational Resources". Quality Management in Health Care. 29 (4): 260–269. doi:10.1097/QMH.0000000000000276. ISSN 1063-8628. PMID 32991545. S2CID 222146291. Archived from the original on 15 August 2021. Retrieved 26 February 2021.
- ↑ Greenland, Sander; Brumback, Babette (October 2002). "An overview of relations among causal modelling methods". International Journal of Epidemiology. 31 (5): 1030–1037. doi:10.1093/ije/31.5.1030. ISSN 1464-3685. PMID 12435780.
- ↑ Hill, Austin Bradford (1965). "The Environment and Disease: Association or Causation?". Proceedings of the Royal Society of Medicine. 58 (5): 295–300. doi:10.1177/003591576505800503. PMC 1898525. PMID 14283879. Archived from the original on 19 February 2021. Retrieved 25 February 2014.
- ↑ Louizos, Christos; Shalit, Uri; Mooij, Joris; Sontag, David; Zemel, Richard; Welling, Max (2017). "Causal Effect Inference with Deep Latent-Variable Models". arXiv:1705.08821 [stat.ML].
- ↑ Hoyer, Patrik O., et al. "Nonlinear causal discovery with additive noise models Archived 2 November 2020 at the Wayback Machine." NIPS. Vol. 21. 2008.
- ↑ Shimizu, Shohei; et al. (2011). "DirectLiNGAM: A direct method for learning a linear non-Gaussian structural equation model" (PDF). The Journal of Machine Learning Research. 12: 1225–1248. arXiv:1101.2489. Archived (PDF) from the original on 23 July 2021. Retrieved 27 July 2019.
- ↑ Zhang, Kun, and Aapo Hyvärinen. "On the identifiability of the post-nonlinear causal model Archived 19 October 2021 at the Wayback Machine." Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence. AUAI Press, 2009.
- 1 2 Mooij, Joris M., et al. "Probabilistic latent variable models for distinguishing between cause and effect Archived 22 July 2020 at the Wayback Machine." NIPS. 2010.
- ↑ Lopez-Paz, David, et al. "Towards a learning theory of cause-effect inference Archived 13 March 2017 at the Wayback Machine" ICML. 2015
- ↑ King, Gary (2012). Designing social inquiry : scientific inference in qualitative research. Princeton Univ. Press. ISBN 978-0691034713. OCLC 754613241.
- 1 2 Mahoney, James (January 2010). "After KKV". World Politics. 62 (1): 120–147. doi:10.1017/S0043887109990220. JSTOR 40646193. S2CID 43923978.
- ↑ Creswell, John W.; Clark, Vicki L. Plano (2011). Designing and Conducting Mixed Methods Research. SAGE Publications. ISBN 9781412975179. Archived from the original on 21 July 2021. Retrieved 23 February 2021.
- ↑ Seawright, Jason (September 2016). Multi-Method Social Science by Jason Seawright. Cambridge Core. doi:10.1017/CBO9781316160831. ISBN 9781316160831. Archived from the original on 21 July 2021. Retrieved 18 April 2019.
- ↑ Smith, Herbert L. (10 February 2014). "Effects of Causes and Causes of Effects: Some Remarks from the Sociological Side". Sociological Methods and Research. 43 (3): 406–415. doi:10.1177/0049124114521149. PMC 4251584. PMID 25477697.
- ↑ Goertz, Gary; Mahoney, James (2006). "A Tale of Two Cultures: Contrasting Quantitative and Qualitative Research". Political Analysis. 14 (3): 227–249. doi:10.1093/pan/mpj017. ISSN 1047-1987.
- 1 2 Angrist, Joshua D.; Pischke, Jörn-Steffen (June 2010). "The Credibility Revolution in Empirical Economics: How Better Research Design Is Taking the Con out of Econometrics". Journal of Economic Perspectives. 24 (2): 3–30. doi:10.1257/jep.24.2.3. hdl:1721.1/54195. ISSN 0895-3309.
- ↑ University, Carnegie Mellon. "Theory of Causation - Department of Philosophy - Dietrich College of Humanities and Social Sciences - Carnegie Mellon University". www.cmu.edu. Archived from the original on 11 July 2021. Retrieved 16 February 2021.
- ↑ Simon, Herbert (1977). Models of Discovery. Dordrecht: Springer. p. 52.
- ↑ Angrist, Joshua D.; Krueger, Alan B. (2001). "Instrumental Variables and the Search for Identification: From Supply and Demand to Natural Experiments". Journal of Economic Perspectives. 15 (4): 69–85. doi:10.1257/jep.15.4.69. hdl:1721.1/63775. Archived from the original on 6 May 2021. Retrieved 16 February 2021.
- ↑ Allen, Michael Patrick, ed. (1997), "Model specification in regression analysis", Understanding Regression Analysis, Boston, MA: Springer US, pp. 166–170, doi:10.1007/978-0-585-25657-3_35, ISBN 978-0-585-25657-3, archived from the original on 15 August 2021, retrieved 16 February 2021
- ↑ Maziarz, Mariusz (2020). The Philosophy of Causality in Economics: Causal Inferences and Policy Proposals. New York: Routledge.
- ↑ Salciccioli, Justin D.; Crutain, Yves; Komorowski, Matthieu; Marshall, Dominic C. (2016), MIT Critical Data (ed.), "Sensitivity Analysis and Model Validation", Secondary Analysis of Electronic Health Records, Cham: Springer International Publishing, pp. 263–271, doi:10.1007/978-3-319-43742-2_17, ISBN 978-3-319-43742-2, PMID 31314264
- ↑ Illowsky, Barbara (2013). "Introductory Statistics". openstax.org. Archived from the original on 6 February 2017. Retrieved 16 February 2021.
- ↑ Henschen, Tobias (2018). "The in-principle inconclusiveness of causal evidence in macroeconomics". European Journal for Philosophy of Science. 8 (3): 709–733. doi:10.1007/s13194-018-0207-7. S2CID 158264284.
- 1 2 Angrist Joshua & Pischke Jörn-Steffen (2008). Mostly Harmless Econometrics: An Empiricist's Companion. Princeton: Princeton University Press.
- ↑ Achen, Christopher H. (June 2002). "Toward a new political methodology: Microfoundations and ART". Annual Review of Political Science. 5 (1): 423–450. doi:10.1146/annurev.polisci.5.112801.080943. ISSN 1094-2939.
- ↑ Dawes, Robyn M. (1979). "The robust beauty of improper linear models in decision making". American Psychologist. 34 (7): 571–582. doi:10.1037/0003-066X.34.7.571. Archived from the original on 21 July 2021. Retrieved 16 February 2021.
- ↑ Vandenbroucke, Jan P; Broadbent, Alex; Pearce, Neil (December 2016). "Causality and causal inference in epidemiology: the need for a pluralistic approach". International Journal of Epidemiology. 45 (6): 1776–1786. doi:10.1093/ije/dyv341. ISSN 0300-5771. PMC 5841832. PMID 26800751.
- ↑ Greenland, Sander (January 2017). "For and Against Methodologies: Some Perspectives on Recent Causal and Statistical Inference Debates". European Journal of Epidemiology. 32 (1): 3–20. doi:10.1007/s10654-017-0230-6. ISSN 1573-7284. PMID 28220361. S2CID 4574751. Archived from the original on 21 July 2021. Retrieved 16 February 2021.
- ↑ Dominus, Susan (18 October 2017). "When the Revolution Came for Amy Cuddy". The New York Times. ISSN 0362-4331. Archived from the original on 3 January 2020. Retrieved 2 March 2019.
- ↑ "The Statistical Crisis in Science". American Scientist. 6 February 2017. Archived from the original on 13 August 2021. Retrieved 18 April 2019.
Bibliography
- Hernán, MA; Robins, JM (21 January 2020). Causal Inference: What If. Barnsley: Boca Raton: Chapman & Hall/CRC.