In statistics, multicollinearity (also collinearity) is a phenomenon in which one predictor variable in a multiple regression model can be to a large degree predicted from the others. In this situation, the coefficient estimates of the multiple regression may change erratically in response to small changes in the data or the procedure used to fit the model.
Contrary to popular belief, including collinear variables does not reduce the predictive power or reliability of the model as a whole. In fact, high collinearity indicates that it is exceptionally important to include all variables, as excluding any variable will cause strong confounding.[1]
However, while including collinear variables in a regression does not bias coefficients outright, multicollinearity inflates biases from other sources,[2][3] often resulting in polarized coefficients[4] and excess type 1 errors.[5] See "Consequences" section below for details.
Note that in textbook statements of the assumptions underlying regression analyses such as ordinary least squares, the requirement of "no multicollinearity" usually refers to the absence of perfect multicollinearity, which is an exact (non-stochastic) linear relation among the predictors. In such a case, the design matrix has less than full rank, and therefore the moment matrix cannot be inverted. Under these circumstances, for a general linear model , the ordinary least squares estimator does not exist.




Definition
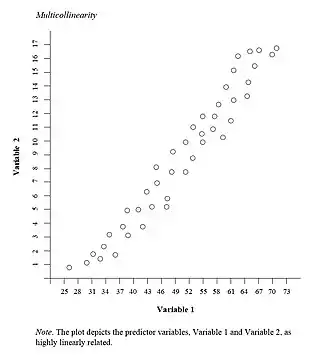
Multicollinearity refers to a situation in which two or more explanatory variables in a multiple regression model are highly linearly related. Mathematically, a set of variables is perfectly multicollinear if there exist one or more exact linear relationships among some of the variables. That is, for all observations ,

-
(1)

where are constants and is the observation on the explanatory variable.




To explore one issue caused by multicollinearity, consider the process of attempting to obtain estimates for the parameters of the multiple regression equation
- .

The ordinary least squares estimates involve inverting the matrix , where

is an matrix, where is the number of observations, is the number of explanatory variables, and . If there is an exact linear relationship (perfect multicollinearity) among the independent variables, then at least one of the columns of is a linear combination of the others, and so the rank of (and therefore of ) is less than , and the matrix will not be invertible.





Perfect collinearity is common when working with raw datasets, which frequently contain redundant information. Once redundancies are identified and removed, however, nearly collinear variables often remain due to correlations inherent in the system being studied. In such a case, Equation (1) may be modified to include an error term :

- .

In this case, there is no exact linear relationship among the variables, but the variables are nearly collinear if the variance of is small. In this case, the matrix has an inverse, but it is ill-conditioned. A computer algorithm may or may not be able to compute an approximate inverse; even if it can, the resulting inverse may have large rounding errors.

Measures
The following are measures of multicollinearity:
- Variance inflation factor (VIF):
where measures how well the th variable can be estimated using all other regressors. It is a popular misconception that factors greater than 5, 10, 20, or 40 indicate "severe" multicollinearity, but this is incorrect. A large VIF can be present regardless of how accurately a regression is estimated.[6] Relatedly, low VIF scores are no guarantee that the bias inflation caused by multicollinearity is not causing excess type 1 errors.[7] - Condition number: The standard measure of ill-conditioning in a matrix is the condition index. This determines if the inversion of the matrix is numerically unstable with finite-precision numbers (standard computer floats and doubles), indicating the potential sensitivity of the computed inverse to small changes in the original matrix. The condition number is computed by finding the maximum singular value divided by the minimum singular value of the design matrix. If the condition number is above 30, the regression may have severe multicollinearity; multicollinearity exists if, in addition, two or more of the variables related to the high condition number have high proportions of variance explained. One advantage of this method is that it also shows which variables are causing the problem.[8]
- Correlation matrices: calculating the correlation between every pair of explanatory variables yields indications as to the likelihood that any given couplet of right-hand-side variables are creating multicollinearity problems. Correlation values (off-diagonal elements) as low as 0.3 may amplify biases such that excess type 1 errors result.[9]



Consequences




Inaccurate Matrix Inverses One consequence of approximate multicollinearity is that, even if the matrix is invertible, a computer algorithm may be unsuccessful in obtaining an approximate inverse. Even if it does obtain one, the inverse may be numerically inaccurate.
When there is a strong correlation among predictor variables in the population, it is difficult to identify which of several variables should be included. However, this is not an artifact of poor modeling. Estimated standard errors are large because there is partial confounding of different variables, which makes it difficult to identify which regressor is truly causing the outcome variable. This confounding remains even when the researcher attempts to ignore it (by excluding variables from the regression). As a result, excluding multicollinear variables from regressions will often invalidate causal inference by removing important confounders.
Bias Inflation and Type 1 Error A second major consequence of multicollinearity within the context of ordinary least squares regression and extensions is its role in bias inflation and excess type 1 error generation. While multicollinearity does not create bias outright it does inflate existing biases,[10][11] such as those caused by data generating processes that are not compliant with the Gauss-Markov assumptions, as stated in econometrics,[12] and/or omitted variables.[13] Further, multicollinearity not only inflates coefficient biases but also t-statistics in many cases, which leads to excess type 1 errors.
The bias inflation among regressor variables that exhibit multicollinearity takes on a very specific pattern when a regression omits a relevant variable correlated with them.[14] Beta polarization occurs with positive correlations; estimated β coefficients of positively correlated variable pairs will be large in absolute magnitude and opposite in sign. One of the coefficients often exhibits a counter-intuitive sign. As the correlation between the variables approaches one, the coefficients will polarize and approach +/- infinity, regardless of their true signs and magnitudes. When the correlation is negative, beta homogenization occurs; estimated β coefficients will be large in absolute magnitude and of the same sign, regardless of the true effect sizes.
Remedies to numerical problems
- Make sure the data are not redundant. Datasets often include redundant variables. For example, a dataset may include variables for income, expenses, and savings. However, because income is equal to expenses plus savings (by definition), it is incorrect to include all 3 variables simultaneously. Similarly, including a dummy variable for every category (e.g., summer, autumn, winter, and spring) as well as a constant term creates perfect multicollinearity.
- Standardize predictor variables. Generating polynomial terms (i.e., for , , , etc.) or interaction terms (i.e., , etc.) can cause multicollinearity if the variable in question has a limited range. Mean-centering will eliminate this special kind of multicollinearity.[15]
- Use an orthogonal representation of the data.[16] Poorly-written statistical software will sometimes fail to converge to a correct representation when variables are strongly correlated. However, it is still possible to rewrite the regression to use only uncorrelated variables by performing a change of basis.
- The model should be left as is. Multicollinearity does not affect the accuracy of the model or its predictions. It is a numerical problem, not a statistical one. Excluding collinear variables leads to artificially small estimates for standard errors, but does not reduce the true (not estimated) standard errors for regression coefficients.[17] Excluding variables with a high variance inflation factor invalidates all calculated standard errors and p-values, by turning the results of the regression into a post hoc analysis.[18]




Remedies to bias inflation problems
None of the remedies listed above regarding "Numerical Problems" are valid in terms of mitigating the bias-inflating effects of multicollinearity. In addition, researchers should not dismiss the possibility of multicollinearity problems merely because of low VIF scores.[19] Here are some suggested alternatives based on substantive analytic modeling.[20][21]
- If possible make use of an exogenous instrument. Because multicollinearity inflates biases that result from endogeneity, such as omitted-variable bias, instrumenting one of the correlated variables that is of theoretical interest will remove the correlation and thus remove the bias inflation.
- Look for consistency across multiple specifications with and without one collinear variable. If a variable of theoretical interest retains its sign and statistical significance level regardless of whether a correlated co-variate is included or excluded in a regression, the consistency suggests that the bias inflation that only occurs when both variables are included is not a source of a problem.
- Make sure that all collinear co-variates are of the expected sign. If a variable of theoretical interest is statistically significant in the predicted direction, make sure that correlated co-variates do not show signs that are the opposite of their expected effects. Bias inflation might be polarizing effects by pushing them in opposite directions, generating an inflated effect of the variable of theoretical interest in one direction and the effects of the co-variate(s) in the other.
- Make sure your results pass the common sense test. If a variable of theoretical interest is statistically significant but in a counter-intuitive direction, and there are correlated co-variates with strong effects, seriously consider the possibility that polarizing bias inflation is causing the counter-intuitive effect. Re-visit Remedies 2 and 3.
See also
References
- ↑ Giles, Dave (15 September 2011). "Econometrics Beat: Dave Giles' Blog: Micronumerosity". Econometrics Beat. Retrieved 3 September 2023.
- ↑ Middleton, Joel; Scott, Marc; Diakow, Ronli; Hill, Jennifer (2016). "Bias amplification and bias unmasking". Political Analysis. 24 (3): 307–323. doi:10.1093/pan/mpw015.
- ↑ Winship, Chris; Western, Bruce (2016). "Multicollinearity and model misspecification". Sociological Science. 3: 627–649. doi:10.15195/v3.a27.
- ↑ Kalnins, Arturs (2018). "Multicollinearity: How common factors cause Type 1 errors in multivariate regression". Strategic Management Journal. 39 (8): 2362–2385. doi:10.1002/smj.2783.
- ↑ Kalnins, 2018
- ↑ O’Brien, R. M. (2007). "A Caution Regarding Rules of Thumb for Variance Inflation Factors". Quality & Quantity. 41 (5): 673–690. doi:10.1007/s11135-006-9018-6. S2CID 28778523.
- ↑ Kalnins, Arturs; Praitis Hill, Kendall (2023). "The VIF Score. What is it Good For? Absolutely Nothing". Organizational Research Methods: 1–18. doi:10.1177/10944281231216381.
- ↑ Belsley, David (1991). Conditioning Diagnostics: Collinearity and Weak Data in Regression. New York: Wiley. ISBN 978-0-471-52889-0.
- ↑ Kalnins, 2018
- ↑ Middleton et al., 2016
- ↑ Winship & Western, 2016
- ↑ Kalnins, 2018
- ↑ Kalnins & Praitis Hill 2023.
- ↑ Kalnins & Praitis Hill 2023.
- ↑ "12.6 - Reducing Structural Multicollinearity | STAT 501". newonlinecourses.science.psu.edu. Retrieved 16 March 2019.
- ↑ "Computational Tricks with Turing (Non-Centered Parametrization and QR Decomposition)". storopoli.io. Retrieved 3 September 2023.
- ↑ Gujarati, Damodar (2009). "Multicollinearity: what happens if the regressors are correlated?". Basic Econometrics (4th ed.). McGraw−Hill. pp. 363. ISBN 9780073375779.
- ↑ Gelman, Andrew; Loken, Eric (14 November 2013). "The garden of forking paths" (PDF). Unpublished – via Columbia.
- ↑ Kalnins & Praitis Hill, 2023.
- ↑ Kalnins, 2018.
- ↑ Kalnins & Praitis Hill, 2023.
Further reading
- Belsley, David A.; Kuh, Edwin; Welsch, Roy E. (1980). Regression Diagnostics: Identifying Influential Data and Sources of Collinearity. New York: Wiley. ISBN 978-0-471-05856-4.
- Goldberger, Arthur S. (1991). "Multicollinearity". A Course in Econometrics. Cambridge: Harvard University Press. pp. 245–53. ISBN 9780674175440.
- Hill, R. Carter; Adkins, Lee C. (2001). "Collinearity". In Baltagi, Badi H. (ed.). A Companion to Theoretical Econometrics. Blackwell. pp. 256–278. doi:10.1002/9780470996249.ch13. ISBN 978-0-631-21254-6.
- Johnston, John (1972). Econometric Methods (Second ed.). New York: McGraw-Hill. pp. 159–168. ISBN 9780070326798.
- Kalnins, Arturs (2022). "When does multicollinearity bias coefficients and cause type 1 errors? A reconciliation of Lindner, Puck, and Verbeke (2020) with Kalnins (2018)". Journal of International Business Studies. 53 (7): 1536–1548. doi:10.1057/s41267-022-00531-9. S2CID 249323519.
- Kmenta, Jan (1986). Elements of Econometrics (Second ed.). New York: Macmillan. pp. 430–442. ISBN 978-0-02-365070-3.
- Maddala, G. S.; Lahiri, Kajal (2009). Introduction to Econometrics (Fourth ed.). Chichester: Wiley. pp. 279–312. ISBN 978-0-470-01512-4.
- Tomaschek, Fabian; Hendrix, Peter; Baayen, R. Harald (2018). "Strategies for addressing collinearity in multivariate linguistic data". Journal of Phonetics. 71: 249–267. doi:10.1016/j.wocn.2018.09.004.
External links
- Thoma, Mark (2 March 2011). "Econometrics Lecture (topic: multicollinearity)". University of Oregon. Archived from the original on 12 December 2021 – via YouTube.
- Earliest Uses: The entry on Multicollinearity has some historical information.