-dimensional hypercube is a network topology for parallel computers with processing elements. The topology allows for an efficient implementation of some basic communication primitives such as Broadcast, All-Reduce, and Prefix sum.[1] The processing elements are numbered through . Each processing element is adjacent to processing elements whose numbers differ in one and only one bit. The algorithms described in this page utilize this structure efficiently.




Algorithm outline
Most of the communication primitives presented in this article share a common template.[2] Initially, each processing element possesses one message that must reach every other processing element during the course of the algorithm. The following pseudo code sketches the communication steps necessary. Hereby, Initialization, Operation, and Output are placeholders that depend on the given communication primitive (see next section).
Input: message . Output: depends on Initialization, Operation and Output. Initialization for do Send to Receive from Operation endfor Output







Each processing element iterates over its neighbors (the expression negates the -th bit in 's binary representation, therefore obtaining the numbers of its neighbors). In each iteration, each processing element exchanges a message with the neighbor and processes the received message afterwards. The processing operation depends on the communication primitive.




Communication primitives
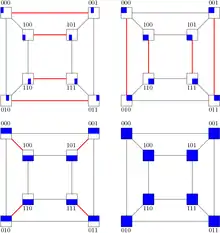
Prefix sum
In the beginning of a prefix sum operation, each processing element owns a message . The goal is to compute , where is an associative operation. The following pseudo code describes the algorithm.



Input: message of processor . Output: prefix sum of processor . for do Send to Receive from if bit in is set then endfor






The algorithm works as follows. Observe that hypercubes of dimension can be split into two hypercubes of dimension . Refer to the sub cube containing nodes with a leading 0 as the 0-sub cube and the sub cube consisting of nodes with a leading 1 as 1-sub cube. Once both sub cubes have calculated the prefix sum, the sum over all elements in the 0-sub cube has to be added to the every element in the 1-sub cube, since every processing element in the 0-sub cube has a lower rank than the processing elements in the 1-sub cube. The pseudo code stores the prefix sum in variable and the sum over all nodes in a sub cube in variable . This makes it possible for all nodes in 1-sub cube to receive the sum over the 0-sub cube in every step.


This results in a factor of for and a factor of for : .





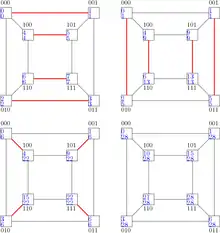
All-gather / all-reduce
All-gather operations start with each processing element having a message . The goal of the operation is for each processing element to know the messages of all other processing elements, i.e. where is concatenation. The operation can be implemented following the algorithm template.


Input: message at processing unit . Output: all messages . for do Send to Receive from endfor



With each iteration, the transferred message doubles in length. This leads to a runtime of .

The same principle can be applied to the All-Reduce operations, but instead of concatenating the messages, it performs a reduction operation on the two messages. So it is a Reduce operation, where all processing units know the result. Compared to a normal reduce operation followed by a broadcast, All-Reduce in hypercubes reduces the number of communication steps.
All-to-all
Here every processing element has a unique message for all other processing elements.
Input: message at processing element to processing element . for do Receive from processing element : all messages for my -dimensional sub cube Send to processing element : all messages for its -dimensional sub cube endfor



With each iteration a messages comes closer to its destination by one dimension, if it hasn't arrived yet. Hence, all messages have reached their target after at most steps. In every step, messages are sent: in the first iteration, half of the messages aren't meant for the own sub cube. In every following step, the sub cube is only half the size as before, but in the previous step exactly the same number of messages arrived from another processing element.


This results in a run-time of .

ESBT-broadcast
The ESBT-broadcast (Edge-disjoint Spanning Binomial Tree) algorithm[3] is a pipelined broadcast algorithm with optimal runtime for clusters with hypercube network topology. The algorithm embeds edge-disjoint binomial trees in the hypercube, such that each neighbor of processing element is the root of a spanning binomial tree on nodes. To broadcast a message, the source node splits its message into chunks of equal size and cyclically sends them to the roots of the binomial trees. Upon receiving a chunk, the binomial trees broadcast it.
Runtime
In each step, the source node sends one of its chunks to a binomial tree. Broadcasting the chunk within the binomial tree takes steps. Thus, it takes steps to distribute all chunks and additionally steps until the last binomial tree broadcast has finished, resulting in steps overall. Therefore, the runtime for a message of length is . With the optimal chunk size , the optimal runtime of the algorithm is .





Construction of the binomial trees
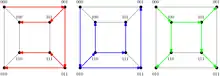
This section describes how to construct the binomial trees systematically. First, construct a single binomial spanning tree von nodes as follows. Number the nodes from to and consider their binary representation. Then the children of each nodes are obtained by negating single leading zeroes. This results in a single binomial spanning tree. To obtain edge-disjoint copies of the tree, translate and rotate the nodes: for the -th copy of the tree, apply a XOR operation with to each node. Subsequently, right-rotate all nodes by digits. The resulting binomial trees are edge-disjoint and therefore fulfill the requirements for the ESBT-broadcasting algorithm.

References
- ↑ Grama, A.(2003). Introduction to Parallel Computing. Addison Wesley; Auflage: 2 ed. ISBN 978-0201648652.
- ↑ Foster, I.(1995). Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering. Addison Wesley; ISBN 0201575949.
- ↑ Johnsson, S.L.; Ho, C.-T. (1989). "Optimum broadcasting and personalized communication in hypercubes". IEEE Transactions on Computers. 38 (9): 1249–1268. doi:10.1109/12.29465. ISSN 0018-9340.