

INAVA, sometimes referred to as hypothetical protein LOC55765, is a protein of unknown function that in humans is encoded by the INAVA gene.[5] Less common gene aliases include FLJ10901 and MGC125608.
Gene
Location

In humans, INAVA is located on the long arm of chromosome 1 at locus 1q32.1. It spans from 200,891,499 to 200,915,736 (24.238 kb) on the plus strand.[5]
Gene neighborhood
INAVA is flanked by G protein-coupled receptor 25 (upstream) and maestro heat-like repeat family member 3 (MROH3P), a predicted downstream pseudogene. Ribosomal protein L34 pseudogene 6 (RPL34P6) is further upstream and kinesin family member 21B is further downstream.[5]
Promoter

There are seven predicted promoters for INAVA, and experimental evidence suggests that isoform 1 and 2, the most common isoforms, are transcribed using different promoters.[6] MatInspector, a tool available through Genomatix, was used to predict transcription factor binding sites within potential promoter regions. The transcription factors that are predicted to target the anticipated promoter for isoform 1 are expressed in a range of tissues. The most common tissues of expression are the urogenital system, nervous system and bone marrow. This coincides with expression data for the INAVA protein, which is highly expressed in the kidney and bone marrow.[7] A diagram of the predicted promoter region, with highlighted transcription factor binding sites, is shown to the right. The factors that are predicted to bind to the promoter region of isoform 2 differ, and twelve of the top twenty predicted factors are expressed in blood cells and/or tissues of the cardiovascular system.
Expression
C1orf106 is expressed in a wide range of tissues. Expression data from GEO profiles is shown below. The sites of highest expression, are listed in the table. Expression is moderate in the placenta, prostate, testis, lung, salivary glands and dendritic cells. It is low in the brain, most immune cells, the adrenal gland, uterus, heart and adipocytes.[7] Expression data, from various experiments, found on GEO profiles suggests that INAVA expression is up-regulated in several cancers including: lung, ovarian, colorectal and breast.
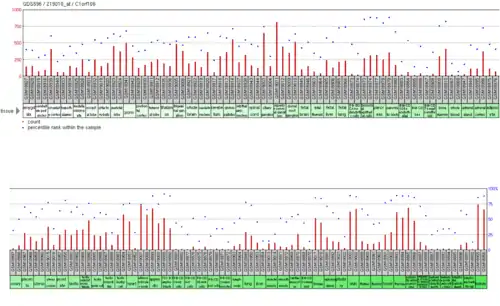
| Tissue | Percentile rank |
|---|---|
| B lymphocytes | 90 |
| Trachea | 89 |
| Skin | 88 |
| Human bronchial epithelial cells | 88 |
| Colorectal adenocarcinoma | 87 |
| Kidney | 87 |
| Tongue | 85 |
| Pancreas | 84 |
| Appendix | 82 |
| Bone marrow | 80 |
mRNA
Isoforms
Nine putative isoforms are produced from the INAVA gene, seven of which are predicted to encode proteins.[8] Isoform 1 and 2, shown below, are the most common isoforms.
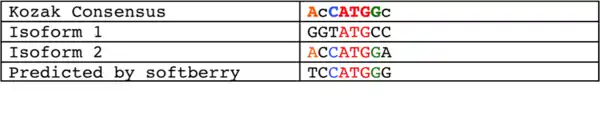
Isoform 1, which is the longest, is accepted as the canonical isoform. It contains ten exons, which encode a protein that is 677 amino acids long, depending on the source. Some sources report that the protein is only 663 amino acids due to the use of a start codon that is forty-two nucleotides downstream. According to NCBI, this isoform has only been predicted computationally.[5] This may be because the Kozak sequence surrounding the downstream start codon is more similar to the consensus Kozak sequence as shown in the table below. Softberry was used to obtain the sequence of the predicted isoform.[9] Isoform 2 is shorter due to a truncated N-terminus. Both isoforms have an alternative polyadenylation site.[8]
miRNA regulation
miRNA-24 was identified as a microRNA that could potentially target INAVA mRNA.[10] The binding site, which is located in the 5' untranslated region is shown.
Protein
General properties

Isoform 1, diagramed below, contains a DUF3338 domain, two low complexity regions and a proline rich region. The protein is arginine and proline rich, and has a lower than average amount of asparagine and hydrophobic amino acids, specifically phenylalanine and isoleucine.[11] The isoelectric point is 9.58, and the molecular weight of the unmodified protein is 72.9 kdal.[12] The protein is not predicted to have an N-terminal signal peptide, but there are predicted nuclear localization signals (NLS) and a leucine rich nuclear export signal.[13][14][15]
Modifications
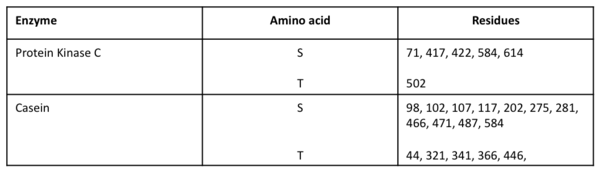
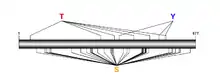
INAVA is predicted to be highly phosphorylated.[16][17] Phosphoylation sites predicted by PROSITE are shown in the table below. NETPhos predictions are illustrated in the diagram. Each line points to a predicted phosphorylation site, and connects to a letter which represents either serine (S), threonine (T) or tyrosine (Y).
Structure
Coiled-coils are predicted to span from residue 130-160 and 200–260.[18] The secondary composition was predicted to be about 60% random coils, 30% alpha helices and 10% beta sheets.[19]
Interactions
The proteins with which the INAVA protein interacts are not well characterized. Text mining evidence suggests INAVA may interact with the following proteins: DNAJC5G, SLC7A13, PIEZO2, MUC19.[20] Experimental evidence, from a yeast two hybrid screen, suggests the INAVA protein interacts with 14-3-3 protein sigma, which is an adaptor protein.[21]
Homology
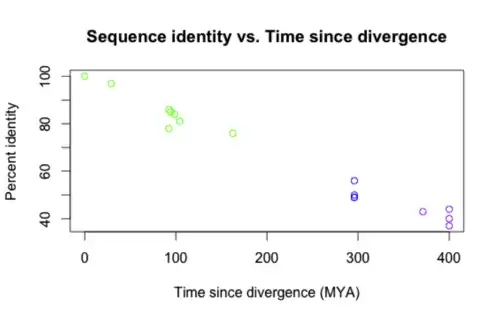
INAVA is well conserved in vertebrates as shown in the table below. Sequences were retrieved from BLAST[22] and BLAT.[23]
| Sequence | Genus and species | Common name | NCBI accession | Length(aa) | Sequence identity | Time since divergence (Mya) | |
|---|---|---|---|---|---|---|---|
| * | C1orf106 | Homo sapiens | Human | NP_060735.3 | 667 | 100% | NA |
| * | C1orf106 | Macaca fascicularis | Crab-eating macaque | XP_005540414.1 | 703 | 97% | 29.0 |
| * | LOC289399 | Rattus norvegicus | Norway rat | NP_001178750.1 | 667 | 86% | 92.3 |
| * | Predicted C1orf106 homolog | Odobenus rosmarus divergens | Walrus | XP_004392787.1 | 672 | 85% | 94.2 |
| * | C1orf106-like | Loxodonta africana | Elephant | XP_003410255.1 | 663 | 84% | 98.7 |
| * | Predicted C1orf106 homolog | Dasypus novemcinctus | Nine-banded armadillo | XP_004478752.1 | 676 | 81% | 104.2 |
| * | Predicted C1orf106 homolog | Ochotona princeps | American pika | XP_004578841.1 | 681 | 78% | 92.3 |
| * | Predicted C1orf106 homolog | Monodelphis domestica | Gray short-tailed opossum | XP_001367913.2 | 578 | 76% | 162.2 |
| * | Predicted C1orf106 homolog | Chrysemys picta bellii | Painted turtle | XP_005313167.1 | 602 | 56% | 296.0 |
| * | Predicted C1orf106 homolog | Geospiza fortis | Medium ground finch | XP_005426868.1 | 542 | 50% | 296.0 |
| * | Predicted C1orf106 homolog | Alligator mississippiensis | Alligator | XP_006278041.1 | 547 | 49% | 296.0 |
| * | Predicted C1orf106 homolog | Ficedula albicollis | Collared flycatcher | XP_005059352.1 | 542 | 49% | 296.0 |
| Predicted C1orf106 homolog | Latimeria chalumnae | West Indian Ocean coelacanth | XP_005988436.1 | 613 | 46% | 414.9 | |
| * | Predicted C1orf106 homolog | Lepisosteus oculatus | Spotted gar | XP_006628420.1 | 637 | 44% | 400.1 |
| * | FERM domain containing 4A | Xenopus (Silurana) tropicalis | Western clawed frog | XP_002935289.2 | 695 | 43% | 371.2 |
| * | Predicted C1orf106 homolog | Oreochromis niloticus | Nile tilapia | XP_005478188.1 | 576 | 40% | 400.1 |
| Predicted C1orf106 homolog | Haplochromis burtoni | Astatotilapia burtoni | XP_005914919.1 | 576 | 40% | 400.1 | |
| Predicted C1orf106 homolog | Pundamilia nyererei | Haplochromis nyererei | XP_005732720.1 | 577 | 40% | 400.1 | |
| * | LOC563192 | Danio rerio | Zebrafish | NP_001073474.1 | 612 | 37% | 400.1 |
| LOC101161145 | Oryzias latipes | Japanese rice fish | XP_004069287.1 | 612 | 33% | 400.1 | |
A graph of the sequence identity versus the time since divergence for the asterisked entries is shown below. The colors correspond to degree of relatedness (green = closely related, purple = distantly related).
Paralogs
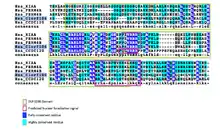
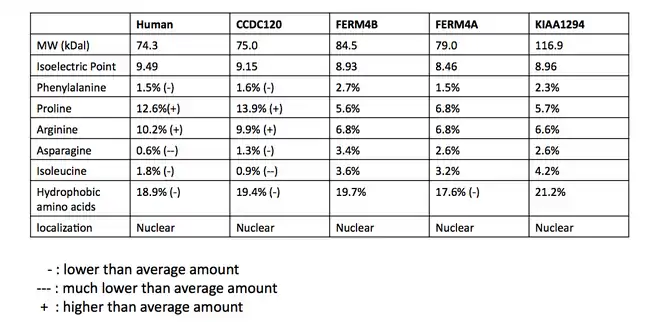
Proteins that are considered to be INAVA paralogs are not consistent between databases. A multiple sequence alignment (MSA) of potentially paralogous proteins was made to determine the likelihood of a truly paralogous relationship.[24] The sequences were retrieved from a BLAST search in humans with the C1orf106 protein. The MSA suggests the proteins share a homologous domain, DUF3338, which is found in eukaryotes. A portion of the multiple sequence alignment is shown below. Apart from the DUF domain (boxed in green), there was little conservation. The DUF3338 domain does not have any extraordinary physical properties, however, one notable finding is that each of the proteins in the MSA is predicted to have two nuclear localization signals. The proteins in the MSA are all predicted to localize to the nucleus.[13] A comparison of the physical properties of the proteins was also conducted using SAPS and is shown in the table.[11]
Clinical significance
A total of 556 single nucleotide polymorphisms (SNPs) have been identified in the gene region of INAVA, 96 of which are associated with a clinical source.[25] Rivas et al.[26] identified four SNPs, shown in the table below, that may be associated with inflammatory bowel disease and Crohn's disease. According to GeneCards, other disease associations may include multiple sclerosis and ulcerative colitis.[27]
| Residue | Change | Notes |
|---|---|---|
| 333 (rs41313912) | Tyrosine ⇒ phenylalanine | Phosphorylated, moderate conservation |
| 376 | Arginine ⇒ cysteine | Moderate conservation |
| 397 | Arginine ⇒ threonine | Not conserved |
| 554 (rs61745433) | Arginine ⇒ cysteine | Moderate conservation |
References
- 1 2 3 GRCh38: Ensembl release 89: ENSG00000163362 - Ensembl, May 2017
- 1 2 3 GRCm38: Ensembl release 89: ENSMUSG00000041605 - Ensembl, May 2017
- ↑ "Human PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- ↑ "Mouse PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- 1 2 3 4 "NCBI Gene 55765". Retrieved 10 February 2014.
- ↑ "Genomatix: MatInspector". Retrieved 6 March 2014.
- 1 2 "GEO Profiles". Retrieved 6 March 2014.
- 1 2 "Aceview". Retrieved 6 March 2014.
- ↑ "Softberry". Retrieved 20 April 2014.
- ↑ "TargetScanHuman 6.2". Retrieved 15 April 2014.
- 1 2 "Statistical Analysis of Protein Sequences". Retrieved 20 April 2014.
- ↑ "Compute pI/Mw tool". Retrieved 10 April 2014.
- 1 2 "PSORTII". Retrieved 20 April 2014.
- ↑ "cNLS Mapper". Archived from the original on 22 November 2021. Retrieved 20 April 2014.
- ↑ "NetNES". Retrieved 20 April 2014.
- ↑ "NETPhos". Retrieved 20 April 2014.
- ↑ "Swiss Institute of Bioinformatics: PROSITE".
- ↑ "ExPASy COILS". Archived from the original on 22 April 2014. Retrieved 20 April 2014.
- ↑ "SOPMA". Retrieved 27 April 2014.
- ↑ "STRING". Retrieved 15 April 2014.
- ↑ "MINT". Retrieved 15 April 2014.
- ↑ "BLAST". Retrieved 8 March 2014.
- ↑ "BLAT". Retrieved 8 March 2014.
- ↑ "SDSC Biology Workbench: ClustalW". Retrieved 12 March 2014.
- ↑ "dbSNP". Retrieved 22 April 2014.
- ↑ Rivas MA; et al. (2011). "Deep resequencing of GWAS loci identifies independent rare variants associated with inflammatory bowel disease". Nature Genetics. 43 (11): 1066–1073. doi:10.1038/ng.952. PMC 3378381. PMID 21983784.
- ↑ "GeneCards". Retrieved 1 May 2014.
External links
- Human C1orf106 genome location and C1orf106 gene details page in the UCSC Genome Browser.