In mathematical statistics, the Kullback–Leibler (KL) divergence (also called relative entropy and I-divergence[1]), denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q.[2][3] A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions (in contrast to variation of information), and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence,[4] a generalization of squared distance, and for certain classes of distributions (notably an exponential family), it satisfies a generalized Pythagorean theorem (which applies to squared distances).[5]

In the simple case, a relative entropy of 0 indicates that the two distributions in question have identical quantities of information. Relative entropy is a nonnegative function of two distributions or measures. It has diverse applications, both theoretical, such as characterizing the relative (Shannon) entropy in information systems, randomness in continuous time-series, and information gain when comparing statistical models of inference; and practical, such as applied statistics, fluid mechanics, neuroscience and bioinformatics.
Introduction and context
Consider two probability distributions P and Q. Usually, P represents the data, the observations, or a measured probability distribution. Distribution Q represents instead a theory, a model, a description or an approximation of P. The Kullback–Leibler divergence is then interpreted as the average difference of the number of bits required for encoding samples of P using a code optimized for Q rather than one optimized for P. Note that the roles of P and Q can be reversed in some situations where that is easier to compute, such as with the expectation–maximization algorithm (EM) and evidence lower bound (ELBO) computations.
Etymology
The relative entropy was introduced by Solomon Kullback and Richard Leibler in Kullback & Leibler (1951) as "the mean information for discrimination between and per observation from ",[6] where one is comparing two probability measures , and are the hypotheses that one is selecting from measure (respectively). They denoted this by , and defined the "'divergence' between and " as the symmetrized quantity , which had already been defined and used by Harold Jeffreys in 1948.[7] In Kullback (1959), the symmetrized form is again referred to as the "divergence", and the relative entropies in each direction are referred to as a "directed divergences" between two distributions;[8] Kullback preferred the term discrimination information.[9] The term "divergence" is in contrast to a distance (metric), since the symmetrized divergence does not satisfy the triangle inequality.[10] Numerous references to earlier uses of the symmetrized divergence and to other statistical distances are given in Kullback (1959, pp. 6–7, §1.3 Divergence). The asymmetric "directed divergence" has come to be known as the Kullback–Leibler divergence, while the symmetrized "divergence" is now referred to as the Jeffreys divergence.








Definition
For discrete probability distributions P and Q defined on the same sample space, the relative entropy from Q to P is defined[11] to be


which is equivalent to

In other words, it is the expectation of the logarithmic difference between the probabilities P and Q, where the expectation is taken using the probabilities P.
Relative entropy is only defined in this way if, for all x, implies (absolute continuity). Otherwise, it is often defined as ,[1] but the value is possible even if everywhere,[12][13] provided that is infinite in extent. Analogous comments apply to the continuous and general measure cases defined below.






Whenever is zero the contribution of the corresponding term is interpreted as zero because


For distributions P and Q of a continuous random variable, relative entropy is defined to be the integral[14]

where p and q denote the probability densities of P and Q.
More generally, if P and Q are probability measures on a measurable space and P is absolutely continuous with respect to Q, then the relative entropy from Q to P is defined as

where is the Radon–Nikodym derivative of P with respect to Q, i.e. the unique Q almost everywhere defined function r on such that which exists because P is absolutely continuous with respect to Q. Also we assume the expression on the right-hand side exists. Equivalently (by the chain rule), this can be written as



which is the entropy of P relative to Q. Continuing in this case, if is any measure on for which densities p and q with and exist (meaning that P and Q are both absolutely continuous with respect to ), then the relative entropy from Q to P is given as






Note that such a measure for which densities can be defined always exists, since one can take although in practice it will usually be one that in the context like counting measure for discrete distributions, or Lebesgue measure or a convenient variant thereof like Gaussian measure or the uniform measure on the sphere, Haar measure on a Lie group etc. for continuous distributions. The logarithms in these formulae are usually taken to base 2 if information is measured in units of bits, or to base e if information is measured in nats. Most formulas involving relative entropy hold regardless of the base of the logarithm.

Various conventions exist for referring to in words. Often it is referred to as the divergence between P and Q, but this fails to convey the fundamental asymmetry in the relation. Sometimes, as in this article, it may be described as the divergence of P from Q or as the divergence from Q to P. This reflects the asymmetry in Bayesian inference, which starts from a prior Q and updates to the posterior P. Another common way to refer to is as the relative entropy of P with respect to Q or the information gain from P over Q.

Basic example
Kullback[3] gives the following example (Table 2.1, Example 2.1). Let P and Q be the distributions shown in the table and figure. P is the distribution on the left side of the figure, a binomial distribution with and . Q is the distribution on the right side of the figure, a discrete uniform distribution with the three possible outcomes 0, 1, 2 (i.e. ), each with probability .






| x | 0 | 1 | 2 |
|---|---|---|---|
| Distribution | |||
| Distribution |






Relative entropies and are calculated as follows. This example uses the natural log with base e, designated ln to get results in nats (see units of information):



Interpretations
Statistics
In the field of statistics, the Neyman–Pearson lemma states that the most powerful way to distinguish between the two distributions P and Q based on an observation Y (drawn from one of them) is through the log of the ratio of their likelihoods: . The KL divergence is the expected value of this statistic if Y is actually drawn from P. Kullback motivated the statistic as an expected log likelihood ratio.[15]

Coding
In the context of coding theory, can be constructed by measuring the expected number of extra bits required to code samples from P using a code optimized for Q rather than the code optimized for P.
Inference
In the context of machine learning, is often called the information gain achieved if P would be used instead of Q which is currently used. By analogy with information theory, it is called the relative entropy of P with respect to Q.
Expressed in the language of Bayesian inference, is a measure of the information gained by revising one's beliefs from the prior probability distribution Q to the posterior probability distribution P. In other words, it is the amount of information lost when Q is used to approximate P.[16]
Information geometry
In applications, P typically represents the "true" distribution of data, observations, or a precisely calculated theoretical distribution, while Q typically represents a theory, model, description, or approximation of P. In order to find a distribution Q that is closest to P, we can minimize the KL divergence and compute an information projection.
While it is a statistical distance, it is not a metric, the most familiar type of distance, but instead it is a divergence.[4] While metrics are symmetric and generalize linear distance, satisfying the triangle inequality, divergences are asymmetric and generalize squared distance, in some cases satisfying a generalized Pythagorean theorem. In general does not equal , and the asymmetry is an important part of the geometry.[4] The infinitesimal form of relative entropy, specifically its Hessian, gives a metric tensor that equals the Fisher information metric; see § Fisher information metric. Relative entropy satisfies a generalized Pythagorean theorem for exponential families (geometrically interpreted as dually flat manifolds), and this allows one to minimize relative entropy by geometric means, for example by information projection and in maximum likelihood estimation.[5]
The relative entropy is the Bregman divergence generated by the negative entropy, but it is also of the form of an f-divergence. For probabilities over a finite alphabet, it is unique in being a member of both of these classes of statistical divergences.
Finance (game theory)
Consider a growth-optimizing investor in a fair game with mutually exclusive outcomes (e.g. a “horse race” in which the official odds add up to one). The rate of return expected by such an investor is equal to the relative entropy between the investor's believed probabilities and the official odds.[17] This is a special case of a much more general connection between financial returns and divergence measures.[18]
Financial risks are connected to via information geometry.[19] Investors' views, the prevailing market view, and risky scenarios form triangles on the relevant manifold of probability distributions. The shape of the triangles determines key financial risks (both qualitatively and quantitatively). For instance, obtuse triangles in which investors' views and risk scenarios appear on “opposite sides” relative to the market describe negative risks, acute triangles describe positive exposure, and the right-angled situation in the middle corresponds to zero risk.

Motivation
In information theory, the Kraft–McMillan theorem establishes that any directly decodable coding scheme for coding a message to identify one value out of a set of possibilities X can be seen as representing an implicit probability distribution over X, where is the length of the code for in bits. Therefore, relative entropy can be interpreted as the expected extra message-length per datum that must be communicated if a code that is optimal for a given (wrong) distribution Q is used, compared to using a code based on the true distribution P: it is the excess entropy.



![{\displaystyle {\begin{aligned}D_{\text{KL}}(P\parallel Q)&=\sum _{x\in {\mathcal {X}}}p(x)\log {\frac {1}{q(x)}}-\sum _{x\in {\mathcal {X}}}p(x)\log {\frac {1}{p(x)}}\\[5pt]&=\mathrm {H} (P,Q)-\mathrm {H} (P)\end{aligned}}}](../I/6430656832db5787365726108ee133d4962d37d2.svg)
where is the cross entropy of P and Q, and is the entropy of P (which is the same as the cross-entropy of P with itself).


The relative entropy can be thought of geometrically as a statistical distance, a measure of how far the distribution Q is from the distribution P. Geometrically it is a divergence: an asymmetric, generalized form of squared distance. The cross-entropy is itself such a measurement (formally a loss function), but it cannot be thought of as a distance, since is not zero. This can be fixed by subtracting to make agree more closely with our notion of distance, as the excess loss. The resulting function is asymmetric, and while this can be symmetrized (see § Symmetrised divergence), the asymmetric form is more useful. See § Interpretations for more on the geometric interpretation.



Relative entropy relates to "rate function" in the theory of large deviations.[20][21]
Arthur Hobson proved that relative entropy is the only measure of difference between probability distributions that satisfies some desired properties, which are the canonical extension to those appearing in a commonly used characterization of entropy.[22] Consequently, mutual information is the only measure of mutual dependence that obeys certain related conditions, since it can be defined in terms of Kullback–Leibler divergence.
Properties
- Relative entropy is always non-negative, a result known as Gibbs' inequality, with equals zero if and only if as measures.


In particular, if and , then -almost everywhere. The entropy thus sets a minimum value for the cross-entropy , the expected number of bits required when using a code based on Q rather than P; and the Kullback–Leibler divergence therefore represents the expected number of extra bits that must be transmitted to identify a value x drawn from X, if a code is used corresponding to the probability distribution Q, rather than the "true" distribution P.



- No upper-bound exists for the general case. However, it is shown that if P and Q are two discrete probability distributions built by distributing the same discrete quantity, then the maximum value of can be calculated.[23]
- Relative entropy remains well-defined for continuous distributions, and furthermore is invariant under parameter transformations. For example, if a transformation is made from variable x to variable , then, since and where is the absolute value of the derivative or more generally of the Jacobian, the relative entropy may be rewritten: where and . Although it was assumed that the transformation was continuous, this need not be the case. This also shows that the relative entropy produces a dimensionally consistent quantity, since if x is a dimensioned variable, and are also dimensioned, since e.g. is dimensionless. The argument of the logarithmic term is and remains dimensionless, as it must. It can therefore be seen as in some ways a more fundamental quantity than some other properties in information theory[24] (such as self-information or Shannon entropy), which can become undefined or negative for non-discrete probabilities.
- Relative entropy is additive for independent distributions in much the same way as Shannon entropy. If are independent distributions, and , and likewise for independent distributions then
- Relative entropy is convex in the pair of probability measures , i.e. if and are two pairs of probability measures then
- The Taylor expansion is .




![{\displaystyle {\begin{aligned}D_{\text{KL}}(P\parallel Q)&=\int _{x_{a}}^{x_{b}}p(x)\log \left({\frac {p(x)}{q(x)}}\right)\,dx\\[6pt]&=\int _{x_{a}}^{x_{b}}{\tilde {p}}(y(x))|{\frac {dy}{dx}}(x)|\log \left({\frac {{\tilde {p}}(y(x))\,|{\frac {dy}{dx}}(x)|}{{\tilde {q}}(y(x))\,|{\frac {dy}{dx}}(x)|}}\right)\,dx\\&=\int _{y_{a}}^{y_{b}}{\tilde {p}}(y)\log \left({\frac {{\tilde {p}}(y)}{{\tilde {q}}(y)}}\right)\,dy\end{aligned}}}](../I/425f522771f4421e24bb896aa3a58e9783e7a6fc.svg)















Duality formula for variational inference
The following result, due to Donsker and Varadhan,[25] is known as Donsker and Varadhan's variational formula.
Theorem [Duality Formula for Variational Inference] — Let be a set endowed with an appropriate -field , and two probability measures P and Q, which formulate two probability spaces and , with . ( indicates that Q is absolutely continuous with respect to P.) Let h be a real-valued integrable random variable on . Then the following equality holds






![{\displaystyle \log E_{P}[\exp h]={\text{sup}}_{Q\ll P}\{E_{Q}[h]-D_{\text{KL}}(Q\parallel P)\}.}](../I/6b77d97ef624d72b613687f5ba1dae28f355ea34.svg)
Further, the supremum on the right-hand side is attained if and only if it holds
![{\displaystyle {\frac {Q(d\theta )}{P(d\theta )}}={\frac {\exp h(\theta )}{E_{P}[\exp h]}},}](../I/75ab3ea6b8da500026a1943181c0c453d8097d5a.svg)
almost surely with respect to probability measure P, where denotes the Radon-Nikodym derivative of Q with respect to P .

For a short proof assuming integrability of with respect to P, let have P-density , i.e. Then


![{\displaystyle {\frac {\exp h(\theta )}{E_{P}[\exp h]}}}](../I/68129a5fd99a843dbd790087e726081a2ccb50a9.svg)
![{\displaystyle Q^{*}(d\theta )={\frac {\exp h(\theta )}{E_{P}[\exp h]}}P(d\theta )}](../I/c054e9af822f3b516e93eb4cc96d96441a617985.svg)
![{\displaystyle D_{\text{KL}}(Q\parallel Q^{*})-D_{\text{KL}}(Q\parallel P)=-E_{Q}[h]+\log E_{P}[\exp h].}](../I/bce269b2e23ca1cf1d596a6d07f9f3920a91f0fd.svg)
Therefore,
![{\displaystyle E_{Q}[h]-D_{\text{KL}}(Q\parallel P)=\log E_{P}[\exp h]-D_{\text{KL}}(Q\parallel Q^{*})\leq \log E_{P}[\exp h],}](../I/882410fdb628f3443226b53611a61133364c9ca0.svg)
where the last inequality follows from , for which equality occurs if and only if . The conclusion follows.


For alternative proof using measure theory, see.[26]
Examples
Multivariate normal distributions
Suppose that we have two multivariate normal distributions, with means and with (non-singular) covariance matrices If the two distributions have the same dimension, k, then the relative entropy between the distributions is as follows:[27]



The logarithm in the last term must be taken to base e since all terms apart from the last are base-e logarithms of expressions that are either factors of the density function or otherwise arise naturally. The equation therefore gives a result measured in nats. Dividing the entire expression above by yields the divergence in bits.

In a numerical implementation, it is helpful to express the result in terms of the Cholesky decompositions such that and . Then with M and y solutions to the triangular linear systems , and ,






A special case, and a common quantity in variational inference, is the relative entropy between a diagonal multivariate normal, and a standard normal distribution (with zero mean and unit variance):

For two univariate normal distributions p and q the above simplifies to[28]

In the case of co-centered normal distributions with , this simplifies[29] to:


Uniform distributions
Consider two uniform distributions, with the support of enclosed within (). Then the information gain is:
![{\displaystyle p=[A,B]}](../I/1f9e91badbd6947c80f1308adadc16071891a440.svg)
![{\displaystyle q=[C,D]}](../I/030d2e5d1d0489e6cb5c4c808edc82344635b0e7.svg)


Intuitively,[29] the information gain to a k times narrower uniform distribution contains bits. This connects with the use of bits in computing, where bits would be needed to identify one element of a k long stream.

Relation to metrics
While relative entropy is a statistical distance, it is not a metric on the space of probability distributions, but instead it is a divergence.[4] While metrics are symmetric and generalize linear distance, satisfying the triangle inequality, divergences are asymmetric in general and generalize squared distance, in some cases satisfying a generalized Pythagorean theorem. In general does not equal , and while this can be symmetrized (see § Symmetrised divergence), the asymmetry is an important part of the geometry.[4]
It generates a topology on the space of probability distributions. More concretely, if is a sequence of distributions such that

- ,

then it is said that
- .

Pinsker's inequality entails that
- ,

where the latter stands for the usual convergence in total variation.
Fisher information metric
Relative entropy is directly related to the Fisher information metric. This can be made explicit as follows. Assume that the probability distributions P and Q are both parameterized by some (possibly multi-dimensional) parameter . Consider then two close by values of and so that the parameter differs by only a small amount from the parameter value . Specifically, up to first order one has (using the Einstein summation convention)





with a small change of in the j direction, and the corresponding rate of change in the probability distribution. Since relative entropy has an absolute minimum 0 for , i.e. , it changes only to second order in the small parameters . More formally, as for any minimum, the first derivatives of the divergence vanish





and by the Taylor expansion one has up to second order

where the Hessian matrix of the divergence

must be positive semidefinite. Letting vary (and dropping the subindex 0) the Hessian defines a (possibly degenerate) Riemannian metric on the θ parameter space, called the Fisher information metric.

Fisher information metric theorem
When satisfies the following regularity conditions:

- exist,


where ξ is independent of ρ

then:

Variation of information
Another information-theoretic metric is variation of information, which is roughly a symmetrization of conditional entropy. It is a metric on the set of partitions of a discrete probability space.
Relation to other quantities of information theory
Many of the other quantities of information theory can be interpreted as applications of relative entropy to specific cases.
Self-information
The self-information, also known as the information content of a signal, random variable, or event is defined as the negative logarithm of the probability of the given outcome occurring.
When applied to a discrete random variable, the self-information can be represented as

is the relative entropy of the probability distribution from a Kronecker delta representing certainty that — i.e. the number of extra bits that must be transmitted to identify i if only the probability distribution is available to the receiver, not the fact that .


Mutual information
The mutual information,
![{\displaystyle {\begin{aligned}\operatorname {I} (X;Y)&=D_{\text{KL}}(P(X,Y)\parallel P(X)P(Y))\\[5pt]&=\operatorname {E} _{X}\{D_{\text{KL}}(P(Y\mid X)\parallel P(Y))\}\\[5pt]&=\operatorname {E} _{Y}\{D_{\text{KL}}(P(X\mid Y)\parallel P(X))\}\end{aligned}}}](../I/1a61aa630dcc13ec929365b0a5de81e999e06f4e.svg)
is the relative entropy of the joint probability distribution from the product of the two marginal probability distributions — i.e. the expected number of extra bits that must be transmitted to identify X and Y if they are coded using only their marginal distributions instead of the joint distribution. Equivalently, if the joint probability is known, it is the expected number of extra bits that must on average be sent to identify Y if the value of X is not already known to the receiver.


Shannon entropy
The Shannon entropy,
![{\displaystyle {\begin{aligned}\mathrm {H} (X)&=\operatorname {E} \left[\operatorname {I} _{X}(x)\right]\\&=\log(N)-D_{\text{KL}}\left(p_{X}(x)\parallel P_{U}(X)\right)\end{aligned}}}](../I/b18246a5c4feccf443e9ff48bcd8bf298e394843.svg)
is the number of bits which would have to be transmitted to identify X from N equally likely possibilities, less the relative entropy of the uniform distribution on the random variates of X, , from the true distribution — i.e. less the expected number of bits saved, which would have had to be sent if the value of X were coded according to the uniform distribution rather than the true distribution . This definition of Shannon entropy forms the basis of E.T. Jaynes's alternative generalization to continuous distributions, the limiting density of discrete points (as opposed to the usual differential entropy), which defines the continuous entropy as



which is equivalent to:

Conditional entropy
![{\displaystyle {\begin{aligned}\mathrm {H} (X\mid Y)&=\log(N)-D_{\text{KL}}(P(X,Y)\parallel P_{U}(X)P(Y))\\[5pt]&=\log(N)-D_{\text{KL}}(P(X,Y)\parallel P(X)P(Y))-D_{\text{KL}}(P(X)\parallel P_{U}(X))\\[5pt]&=\mathrm {H} (X)-\operatorname {I} (X;Y)\\[5pt]&=\log(N)-\operatorname {E} _{Y}\left[D_{\text{KL}}\left(P\left(X\mid Y\right)\parallel P_{U}(X)\right)\right]\end{aligned}}}](../I/edde8fb0ebe5da09ffa735847180fd6f5dd48dda.svg)
is the number of bits which would have to be transmitted to identify X from N equally likely possibilities, less the relative entropy of the product distribution from the true joint distribution — i.e. less the expected number of bits saved which would have had to be sent if the value of X were coded according to the uniform distribution rather than the conditional distribution of X given Y.


Cross entropy
When we have a set of possible events, coming from the distribution p, we can encode them (with a lossless data compression) using entropy encoding. This compresses the data by replacing each fixed-length input symbol with a corresponding unique, variable-length, prefix-free code (e.g.: the events (A, B, C) with probabilities p = (1/2, 1/4, 1/4) can be encoded as the bits (0, 10, 11)). If we know the distribution p in advance, we can devise an encoding that would be optimal (e.g.: using Huffman coding). Meaning the messages we encode will have the shortest length on average (assuming the encoded events are sampled from p), which will be equal to Shannon's Entropy of p (denoted as ). However, if we use a different probability distribution (q) when creating the entropy encoding scheme, then a larger number of bits will be used (on average) to identify an event from a set of possibilities. This new (larger) number is measured by the cross entropy between p and q.

The cross entropy between two probability distributions (p and q) measures the average number of bits needed to identify an event from a set of possibilities, if a coding scheme is used based on a given probability distribution q, rather than the "true" distribution p. The cross entropy for two distributions p and q over the same probability space is thus defined as follows.
![{\displaystyle \mathrm {H} (p,q)=\operatorname {E} _{p}[-\log(q)]=\mathrm {H} (p)+D_{\text{KL}}(p\parallel q).}](../I/4b47b9e20fa1349b4de4f9329ed7e187ea688bb4.svg)
For explicit derivation of this, see the Motivation section above.
Under this scenario, relative entropies (kl-divergence) can be interpreted as the extra number of bits, on average, that are needed (beyond ) for encoding the events because of using q for constructing the encoding scheme instead of p.
Bayesian updating
In Bayesian statistics, relative entropy can be used as a measure of the information gain in moving from a prior distribution to a posterior distribution: . If some new fact is discovered, it can be used to update the posterior distribution for X from to a new posterior distribution using Bayes' theorem:





This distribution has a new entropy:

which may be less than or greater than the original entropy . However, from the standpoint of the new probability distribution one can estimate that to have used the original code based on instead of a new code based on would have added an expected number of bits:


to the message length. This therefore represents the amount of useful information, or information gain, about X, that has been learned by discovering .
If a further piece of data, , subsequently comes in, the probability distribution for x can be updated further, to give a new best guess . If one reinvestigates the information gain for using rather than , it turns out that it may be either greater or less than previously estimated:



- may be ≤ or > than


and so the combined information gain does not obey the triangle inequality:
- may be <, = or > than


All one can say is that on average, averaging using , the two sides will average out.

Bayesian experimental design
A common goal in Bayesian experimental design is to maximise the expected relative entropy between the prior and the posterior.[31] When posteriors are approximated to be Gaussian distributions, a design maximising the expected relative entropy is called Bayes d-optimal.
Discrimination information
Relative entropy can also be interpreted as the expected discrimination information for over : the mean information per sample for discriminating in favor of a hypothesis against a hypothesis , when hypothesis is true.[32] Another name for this quantity, given to it by I. J. Good, is the expected weight of evidence for over to be expected from each sample.


The expected weight of evidence for over is not the same as the information gain expected per sample about the probability distribution of the hypotheses,


Either of the two quantities can be used as a utility function in Bayesian experimental design, to choose an optimal next question to investigate: but they will in general lead to rather different experimental strategies.
On the entropy scale of information gain there is very little difference between near certainty and absolute certainty—coding according to a near certainty requires hardly any more bits than coding according to an absolute certainty. On the other hand, on the logit scale implied by weight of evidence, the difference between the two is enormous – infinite perhaps; this might reflect the difference between being almost sure (on a probabilistic level) that, say, the Riemann hypothesis is correct, compared to being certain that it is correct because one has a mathematical proof. These two different scales of loss function for uncertainty are both useful, according to how well each reflects the particular circumstances of the problem in question.
Principle of minimum discrimination information
The idea of relative entropy as discrimination information led Kullback to propose the Principle of Minimum Discrimination Information (MDI): given new facts, a new distribution f should be chosen which is as hard to discriminate from the original distribution as possible; so that the new data produces as small an information gain as possible.


For example, if one had a prior distribution over x and a, and subsequently learnt the true distribution of a was , then the relative entropy between the new joint distribution for x and a, , and the earlier prior distribution would be:




i.e. the sum of the relative entropy of the prior distribution for a from the updated distribution , plus the expected value (using the probability distribution ) of the relative entropy of the prior conditional distribution from the new conditional distribution . (Note that often the later expected value is called the conditional relative entropy (or conditional Kullback–Leibler divergence) and denoted by [3][30]) This is minimized if over the whole support of ; and we note that this result incorporates Bayes' theorem, if the new distribution is in fact a δ function representing certainty that a has one particular value.





MDI can be seen as an extension of Laplace's Principle of Insufficient Reason, and the Principle of Maximum Entropy of E.T. Jaynes. In particular, it is the natural extension of the principle of maximum entropy from discrete to continuous distributions, for which Shannon entropy ceases to be so useful (see differential entropy), but the relative entropy continues to be just as relevant.
In the engineering literature, MDI is sometimes called the Principle of Minimum Cross-Entropy (MCE) or Minxent for short. Minimising relative entropy from m to p with respect to m is equivalent to minimizing the cross-entropy of p and m, since

which is appropriate if one is trying to choose an adequate approximation to p. However, this is just as often not the task one is trying to achieve. Instead, just as often it is m that is some fixed prior reference measure, and p that one is attempting to optimise by minimising subject to some constraint. This has led to some ambiguity in the literature, with some authors attempting to resolve the inconsistency by redefining cross-entropy to be , rather than .


Relationship to available work

Surprisals[33] add where probabilities multiply. The surprisal for an event of probability p is defined as . If k is then surprisal is in nats, bits, or so that, for instance, there are N bits of surprisal for landing all "heads" on a toss of N coins.




Best-guess states (e.g. for atoms in a gas) are inferred by maximizing the average surprisal S (entropy) for a given set of control parameters (like pressure P or volume V). This constrained entropy maximization, both classically[34] and quantum mechanically,[35] minimizes Gibbs availability in entropy units[36] where Z is a constrained multiplicity or partition function.

When temperature T is fixed, free energy () is also minimized. Thus if and number of molecules N are constant, the Helmholtz free energy (where U is energy and S is entropy) is minimized as a system "equilibrates." If T and P are held constant (say during processes in your body), the Gibbs free energy is minimized instead. The change in free energy under these conditions is a measure of available work that might be done in the process. Thus available work for an ideal gas at constant temperature and pressure is where and (see also Gibbs inequality).








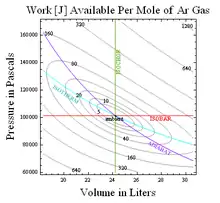
More generally[37] the work available relative to some ambient is obtained by multiplying ambient temperature by relative entropy or net surprisal defined as the average value of where is the probability of a given state under ambient conditions. For instance, the work available in equilibrating a monatomic ideal gas to ambient values of and is thus , where relative entropy





![{\displaystyle \Delta I=Nk\left[\Theta \left({\frac {V}{V_{o}}}\right)+{\frac {3}{2}}\Theta \left({\frac {T}{T_{o}}}\right)\right].}](../I/fc11012ca45e6887919149842a8c033f1763b4ed.svg)
The resulting contours of constant relative entropy, shown at right for a mole of Argon at standard temperature and pressure, for example put limits on the conversion of hot to cold as in flame-powered air-conditioning or in the unpowered device to convert boiling-water to ice-water discussed here.[38] Thus relative entropy measures thermodynamic availability in bits.
Quantum information theory
For density matrices P and Q on a Hilbert space, the quantum relative entropy from Q to P is defined to be

In quantum information science the minimum of over all separable states Q can also be used as a measure of entanglement in the state P.
Relationship between models and reality
Just as relative entropy of "actual from ambient" measures thermodynamic availability, relative entropy of "reality from a model" is also useful even if the only clues we have about reality are some experimental measurements. In the former case relative entropy describes distance to equilibrium or (when multiplied by ambient temperature) the amount of available work, while in the latter case it tells you about surprises that reality has up its sleeve or, in other words, how much the model has yet to learn.
Although this tool for evaluating models against systems that are accessible experimentally may be applied in any field, its application to selecting a statistical model via Akaike information criterion are particularly well described in papers[39] and a book[40] by Burnham and Anderson. In a nutshell the relative entropy of reality from a model may be estimated, to within a constant additive term, by a function of the deviations observed between data and the model's predictions (like the mean squared deviation) . Estimates of such divergence for models that share the same additive term can in turn be used to select among models.
When trying to fit parametrized models to data there are various estimators which attempt to minimize relative entropy, such as maximum likelihood and maximum spacing estimators.
Symmetrised divergence
Kullback & Leibler (1951) also considered the symmetrized function:[6]

which they referred to as the "divergence", though today the "KL divergence" refers to the asymmetric function (see § Etymology for the evolution of the term). This function is symmetric and nonnegative, and had already been defined and used by Harold Jeffreys in 1948;[7] it is accordingly called the Jeffreys divergence.
This quantity has sometimes been used for feature selection in classification problems, where P and Q are the conditional pdfs of a feature under two different classes. In the Banking and Finance industries, this quantity is referred to as Population Stability Index (PSI), and is used to assess distributional shifts in model features through time.
An alternative is given via the -divergence,


which can be interpreted as the expected information gain about X from discovering which probability distribution X is drawn from, P or Q, if they currently have probabilities and respectively.

The value gives the Jensen–Shannon divergence, defined by


where M is the average of the two distributions,

We can also interpret as the capacity of a noisy information channel with two inputs giving the output distributions P and Q. The Jensen–Shannon divergence, like all f-divergences, is locally proportional to the Fisher information metric. It is similar to the Hellinger metric (in the sense that it induces the same affine connection on a statistical manifold).

Furthermore, the Jensen–Shannon divergence can be generalized using abstract statistical M-mixtures relying on an abstract mean M.[41][42]
Relationship to other probability-distance measures
There are many other important measures of probability distance. Some of these are particularly connected with relative entropy. For example:
- The total-variation distance, . This is connected to the divergence through Pinsker's inequality: Pinsker's inequality is vacuous for any distributions where , since the total variation distance is at most 1. For such distributions, an alternative bound can be used, due to Bretagnolle and Huber[43] (see, also, Tsybakov[44]):
- The family of Rényi divergences generalize relative entropy. Depending on the value of a certain parameter, , various inequalities may be deduced.





Other notable measures of distance include the Hellinger distance, histogram intersection, Chi-squared statistic, quadratic form distance, match distance, Kolmogorov–Smirnov distance, and earth mover's distance.[45]
Data differencing
Just as absolute entropy serves as theoretical background for data compression, relative entropy serves as theoretical background for data differencing – the absolute entropy of a set of data in this sense being the data required to reconstruct it (minimum compressed size), while the relative entropy of a target set of data, given a source set of data, is the data required to reconstruct the target given the source (minimum size of a patch).
See also
- Akaike information criterion
- Bayesian information criterion
- Bregman divergence
- Cross-entropy
- Deviance information criterion
- Entropic value at risk
- Entropy power inequality
- Hellinger distance
- Information gain in decision trees
- Information gain ratio
- Information theory and measure theory
- Jensen–Shannon divergence
- Quantum relative entropy
- Solomon Kullback and Richard Leibler
References
- 1 2 Csiszar, I (February 1975). "I-Divergence Geometry of Probability Distributions and Minimization Problems". Ann. Probab. 3 (1): 146–158. doi:10.1214/aop/1176996454.
- ↑ Kullback, S.; Leibler, R.A. (1951). "On information and sufficiency". Annals of Mathematical Statistics. 22 (1): 79–86. doi:10.1214/aoms/1177729694. JSTOR 2236703. MR 0039968.
- 1 2 3 Kullback 1959.
- 1 2 3 4 5 Amari 2016, p. 11.
- 1 2 Amari 2016, p. 28.
- 1 2 Kullback & Leibler 1951, p. 80.
- 1 2 Jeffreys 1948, p. 158.
- ↑ Kullback 1959, p. 7.
- ↑ Kullback, S. (1987). "Letter to the Editor: The Kullback–Leibler distance". The American Statistician. 41 (4): 340–341. doi:10.1080/00031305.1987.10475510. JSTOR 2684769.
- ↑ Kullback 1959, p. 6.
- ↑ MacKay, David J.C. (2003). Information Theory, Inference, and Learning Algorithms (1st ed.). Cambridge University Press. p. 34. ISBN 9780521642989 – via Google Books.
- ↑ "What's the maximum value of Kullback-Leibler (KL) divergence?". Machine learning. Statistics Stack Exchange (stats.stackexchange.com). Cross validated.
- ↑ "In what situations is the integral equal to infinity?". Integration. Mathematics Stack Exchange (math.stackexchange.com).
- ↑ Bishop, Christopher M. Pattern recognition and machine learning. p. 55. OCLC 1334664824.
- ↑ Kullback 1959, p. 5.
- ↑ Burnham, K. P.; Anderson, D. R. (2002). Model Selection and Multi-Model Inference (2nd ed.). Springer. p. 51. ISBN 9780387953649.
- ↑ Kelly, J. L. Jr. (1956). "A New Interpretation of Information Rate". Bell Syst. Tech. J. 2 (4): 917–926. doi:10.1002/j.1538-7305.1956.tb03809.x.
- ↑ Soklakov, A. N. (2020). "Economics of Disagreement—Financial Intuition for the Rényi Divergence". Entropy. 22 (8): 860. arXiv:1811.08308. Bibcode:2020Entrp..22..860S. doi:10.3390/e22080860. PMC 7517462. PMID 33286632.
- ↑ Soklakov, A. N. (2023). "Information Geometry of Risks and Returns". Risk. June. SSRN 4134885.
- ↑ Sanov, I.N. (1957). "On the probability of large deviations of random magnitudes". Mat. Sbornik. 42 (84): 11–44.
- ↑ Novak S.Y. (2011), Extreme Value Methods with Applications to Finance ch. 14.5 (Chapman & Hall). ISBN 978-1-4398-3574-6.
- ↑ Hobson, Arthur (1971). Concepts in statistical mechanics. New York: Gordon and Breach. ISBN 978-0677032405.
- ↑ Bonnici, V. (2020). "Kullback-Leibler divergence between quantum distributions, and its upper-bound". arXiv:2008.05932 [cs.LG].
- ↑ See the section "differential entropy – 4" in Relative Entropy video lecture by Sergio Verdú NIPS 2009
- ↑ Donsker, Monroe D.; Varadhan, SR Srinivasa (1983). "Asymptotic evaluation of certain Markov process expectations for large time. IV". Communications on Pure and Applied Mathematics. 36 (2): 183–212. doi:10.1002/cpa.3160360204.
- ↑ Lee, Se Yoon (2021). "Gibbs sampler and coordinate ascent variational inference: A set-theoretical review". Communications in Statistics - Theory and Methods. 51 (6): 1549–1568. arXiv:2008.01006. doi:10.1080/03610926.2021.1921214. S2CID 220935477.
- ↑ Duchi J. "Derivations for Linear Algebra and Optimization" (PDF). p. 13.
- ↑ Belov, Dmitry I.; Armstrong, Ronald D. (2011-04-15). "Distributions of the Kullback-Leibler divergence with applications". British Journal of Mathematical and Statistical Psychology. 64 (2): 291–309. doi:10.1348/000711010x522227. ISSN 0007-1102. PMID 21492134.
- 1 2 Buchner, Johannes (2022-04-29). An intuition for physicists: information gain from experiments. OCLC 1363563215.
- 1 2 Cover, Thomas M.; Thomas, Joy A. (1991), Elements of Information Theory, John Wiley & Sons, p. 22
- ↑ Chaloner, K.; Verdinelli, I. (1995). "Bayesian experimental design: a review". Statistical Science. 10 (3): 273–304. doi:10.1214/ss/1177009939. hdl:11299/199630.
- ↑ Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. (2007). "Section 14.7.2. Kullback–Leibler Distance". Numerical Recipes: The Art of Scientific Computing (3rd ed.). Cambridge University Press. ISBN 978-0-521-88068-8.
- ↑ Tribus, Myron (1959). Thermostatics and Thermodynamics: An Introduction to Energy, Information and States of Matter, with Engineering Applications. Van Nostrand.
- ↑ Jaynes, E. T. (1957). "Information theory and statistical mechanics" (PDF). Physical Review. 106 (4): 620–630. Bibcode:1957PhRv..106..620J. doi:10.1103/physrev.106.620. S2CID 17870175.
- ↑ Jaynes, E. T. (1957). "Information theory and statistical mechanics II" (PDF). Physical Review. 108 (2): 171–190. Bibcode:1957PhRv..108..171J. doi:10.1103/physrev.108.171.
- ↑ Gibbs, Josiah Willard (1871). A Method of Geometrical Representation of the Thermodynamic Properties of Substances by Means of Surfaces. The Academy. footnote page 52.
- ↑ Tribus, M.; McIrvine, E. C. (1971). "Energy and information". Scientific American. 224 (3): 179–186. Bibcode:1971SciAm.225c.179T. doi:10.1038/scientificamerican0971-179.
- ↑ Fraundorf, P. (2007). "Thermal roots of correlation-based complexity". Complexity. 13 (3): 18–26. arXiv:1103.2481. Bibcode:2008Cmplx..13c..18F. doi:10.1002/cplx.20195. S2CID 20794688. Archived from the original on 2011-08-13.
- ↑ Burnham, K.P.; Anderson, D.R. (2001). "Kullback–Leibler information as a basis for strong inference in ecological studies". Wildlife Research. 28 (2): 111–119. doi:10.1071/WR99107.
- ↑ Burnham, Kenneth P. (December 2010). Model selection and multimodel inference : a practical information-theoretic approach. Springer. ISBN 978-1-4419-2973-0. OCLC 878132909.
- ↑ Nielsen, Frank (2019). "On the Jensen–Shannon Symmetrization of Distances Relying on Abstract Means". Entropy. 21 (5): 485. arXiv:1904.04017. Bibcode:2019Entrp..21..485N. doi:10.3390/e21050485. PMC 7514974. PMID 33267199.
- ↑ Nielsen, Frank (2020). "On a Generalization of the Jensen–Shannon Divergence and the Jensen–Shannon Centroid". Entropy. 22 (2): 221. arXiv:1912.00610. Bibcode:2020Entrp..22..221N. doi:10.3390/e22020221. PMC 7516653. PMID 33285995.
- ↑ Bretagnolle, J.; Huber, C. (1978), Estimation des densités : Risque minimax, Lecture Notes in Mathematics (in French), Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 342–363, doi:10.1007/bfb0064610, ISBN 978-3-540-08761-8, S2CID 122597694, retrieved 2023-02-14 Lemma 2.1
- ↑ B.), Tsybakov, A. B. (Alexandre (2010). Introduction to nonparametric estimation. Springer. ISBN 978-1-4419-2709-5. OCLC 757859245.
{{cite book}}: CS1 maint: multiple names: authors list (link) Equation 2.25. - ↑ Rubner, Y.; Tomasi, C.; Guibas, L. J. (2000). "The earth mover's distance as a metric for image retrieval". International Journal of Computer Vision. 40 (2): 99–121. doi:10.1023/A:1026543900054. S2CID 14106275.
- Amari, Shun-ichi (2016). Information Geometry and Its Applications. Applied Mathematical Sciences. Vol. 194. Springer Japan. pp. XIII, 374. doi:10.1007/978-4-431-55978-8. ISBN 978-4-431-55977-1.
- Kullback, Solomon (1959), Information Theory and Statistics, John Wiley & Sons. Republished by Dover Publications in 1968; reprinted in 1978: ISBN 0-8446-5625-9.
- Jeffreys, Harold (1948). Theory of Probability (Second ed.). Oxford University Press.
External links
- Information Theoretical Estimators Toolbox
- Ruby gem for calculating Kullback–Leibler divergence
- Jon Shlens' tutorial on Kullback–Leibler divergence and likelihood theory
- Matlab code for calculating Kullback–Leibler divergence for discrete distributions
- Sergio Verdú, Relative Entropy, NIPS 2009. One-hour video lecture.
- A modern summary of info-theoretic divergence measures