| Part of a series on |
| Regression analysis |
|---|
| Models |
| Estimation |
| Background |
Linear least squares (LLS) is the least squares approximation of linear functions to data. It is a set of formulations for solving statistical problems involved in linear regression, including variants for ordinary (unweighted), weighted, and generalized (correlated) residuals. Numerical methods for linear least squares include inverting the matrix of the normal equations and orthogonal decomposition methods.
Basic formulation
Consider the linear equation
-
(1)

where and are given and is variable to be computed. When it is generally the case that (1) has no solution. For example, there is no value of that satisfies






because the first two rows require that but then the third row is not satisfied. Thus, for the goal of solving (1) exactly is typically replaced by finding the value of that minimizes some error. There are many ways that the error can be defined, but one of the most common is to define it as This produces a minimization problem, called a least squares problem


-
(2)

The solution to the least squares problem (1) is computed by solving the normal equation[1]
-
(3)

where denotes the transpose of .


Continuing the example, above, with

we find

and

Solving the normal equation gives

Formulations for Linear Regression
The three main linear least squares formulations are:
- Ordinary least squares (OLS) is the most common estimator. OLS estimates are commonly used to analyze both experimental and observational data. The OLS method minimizes the sum of squared residuals, and leads to a closed-form expression for the estimated value of the unknown parameter vector β: where is a vector whose ith element is the ith observation of the dependent variable, and is a matrix whose ij element is the ith observation of the jth independent variable. The estimator is unbiased and consistent if the errors have finite variance and are uncorrelated with the regressors:[2]where is the transpose of row i of the matrix It is also efficient under the assumption that the errors have finite variance and are homoscedastic, meaning that E[εi2|xi] does not depend on i. The condition that the errors are uncorrelated with the regressors will generally be satisfied in an experiment, but in the case of observational data, it is difficult to exclude the possibility of an omitted covariate z that is related to both the observed covariates and the response variable. The existence of such a covariate will generally lead to a correlation between the regressors and the response variable, and hence to an inconsistent estimator of β. The condition of homoscedasticity can fail with either experimental or observational data. If the goal is either inference or predictive modeling, the performance of OLS estimates can be poor if multicollinearity is present, unless the sample size is large.
- Weighted least squares (WLS) are used when heteroscedasticity is present in the error terms of the model.
- Generalized least squares (GLS) is an extension of the OLS method, that allows efficient estimation of β when either heteroscedasticity, or correlations, or both are present among the error terms of the model, as long as the form of heteroscedasticity and correlation is known independently of the data. To handle heteroscedasticity when the error terms are uncorrelated with each other, GLS minimizes a weighted analogue to the sum of squared residuals from OLS regression, where the weight for the ith case is inversely proportional to var(εi). This special case of GLS is called "weighted least squares". The GLS solution to an estimation problem is where Ω is the covariance matrix of the errors. GLS can be viewed as applying a linear transformation to the data so that the assumptions of OLS are met for the transformed data. For GLS to be applied, the covariance structure of the errors must be known up to a multiplicative constant.



![{\displaystyle \operatorname {E} [\,\mathbf {x} _{i}\varepsilon _{i}\,]=0,}](../I/f6d7585c35934207b50eba9a513a1873c624d49c.svg)



Alternative formulations
Other formulations include:
- Iteratively reweighted least squares (IRLS) is used when heteroscedasticity, or correlations, or both are present among the error terms of the model, but where little is known about the covariance structure of the errors independently of the data.[3] In the first iteration, OLS, or GLS with a provisional covariance structure is carried out, and the residuals are obtained from the fit. Based on the residuals, an improved estimate of the covariance structure of the errors can usually be obtained. A subsequent GLS iteration is then performed using this estimate of the error structure to define the weights. The process can be iterated to convergence, but in many cases, only one iteration is sufficient to achieve an efficient estimate of β.[4][5]
- Instrumental variables regression (IV) can be performed when the regressors are correlated with the errors. In this case, we need the existence of some auxiliary instrumental variables zi such that E[ziεi] = 0. If Z is the matrix of instruments, then the estimator can be given in closed form as Optimal instruments regression is an extension of classical IV regression to the situation where E[εi | zi] = 0.
- Total least squares (TLS)[6] is an approach to least squares estimation of the linear regression model that treats the covariates and response variable in a more geometrically symmetric manner than OLS. It is one approach to handling the "errors in variables" problem, and is also sometimes used even when the covariates are assumed to be error-free.

- Linear Template Fit (LTF)[7] combines a linear regression with (generalized) least squares in order to determine the best estimator. The Linear Template Fit addresses the frequent issue, when the residuals cannot be expressed analytically or are too time consuming to be evaluate repeatedly, as it is often the case in iterative minimization algorithms. In the Linear Template Fit, the residuals are estimated from the random variables and from a linear approximation of the underlying true model, while the true model needs to be provided for at least (were is the number of estimators) distinct reference values β. The true distribution is then approximated by a linear regression, and the best estimators are obtained in closed form as where denotes the template matrix with the values of the known or previously determined model for any of the reference values β, are the random variables (e.g. a measurement), and the matrix and the vector are calculated from the values of β. The LTF can also be expressed for Log-normal distribution distributed random variables. A generalization of the LTF is the Quadratic Template Fit, which assumes a second order regression of the model, requires predictions for at least distinct values β, and it finds the best estimator using Newton's method.







- Percentage least squares focuses on reducing percentage errors, which is useful in the field of forecasting or time series analysis. It is also useful in situations where the dependent variable has a wide range without constant variance, as here the larger residuals at the upper end of the range would dominate if OLS were used. When the percentage or relative error is normally distributed, least squares percentage regression provides maximum likelihood estimates. Percentage regression is linked to a multiplicative error model, whereas OLS is linked to models containing an additive error term.[8]
- Constrained least squares, indicates a linear least squares problem with additional constraints on the solution.
Objective function
In OLS (i.e., assuming unweighted observations), the optimal value of the objective function is found by substituting the optimal expression for the coefficient vector:

where , the latter equality holding since is symmetric and idempotent. It can be shown from this[9] that under an appropriate assignment of weights the expected value of S is . If instead unit weights are assumed, the expected value of S is , where is the variance of each observation.





If it is assumed that the residuals belong to a normal distribution, the objective function, being a sum of weighted squared residuals, will belong to a chi-squared () distribution with m − n degrees of freedom. Some illustrative percentile values of are given in the following table.[10]

| 10 | 9.34 | 18.3 | 23.2 |
| 25 | 24.3 | 37.7 | 44.3 |
| 100 | 99.3 | 124 | 136 |




These values can be used for a statistical criterion as to the goodness of fit. When unit weights are used, the numbers should be divided by the variance of an observation.
For WLS, the ordinary objective function above is replaced for a weighted average of residuals.
Discussion
In statistics and mathematics, linear least squares is an approach to fitting a mathematical or statistical model to data in cases where the idealized value provided by the model for any data point is expressed linearly in terms of the unknown parameters of the model. The resulting fitted model can be used to summarize the data, to predict unobserved values from the same system, and to understand the mechanisms that may underlie the system.
Mathematically, linear least squares is the problem of approximately solving an overdetermined system of linear equations A x = b, where b is not an element of the column space of the matrix A. The approximate solution is realized as an exact solution to A x = b', where b' is the projection of b onto the column space of A. The best approximation is then that which minimizes the sum of squared differences between the data values and their corresponding modeled values. The approach is called linear least squares since the assumed function is linear in the parameters to be estimated. Linear least squares problems are convex and have a closed-form solution that is unique, provided that the number of data points used for fitting equals or exceeds the number of unknown parameters, except in special degenerate situations. In contrast, non-linear least squares problems generally must be solved by an iterative procedure, and the problems can be non-convex with multiple optima for the objective function. If prior distributions are available, then even an underdetermined system can be solved using the Bayesian MMSE estimator.
In statistics, linear least squares problems correspond to a particularly important type of statistical model called linear regression which arises as a particular form of regression analysis. One basic form of such a model is an ordinary least squares model. The present article concentrates on the mathematical aspects of linear least squares problems, with discussion of the formulation and interpretation of statistical regression models and statistical inferences related to these being dealt with in the articles just mentioned. See outline of regression analysis for an outline of the topic.
Properties
If the experimental errors, , are uncorrelated, have a mean of zero and a constant variance, , the Gauss–Markov theorem states that the least-squares estimator, , has the minimum variance of all estimators that are linear combinations of the observations. In this sense it is the best, or optimal, estimator of the parameters. Note particularly that this property is independent of the statistical distribution function of the errors. In other words, the distribution function of the errors need not be a normal distribution. However, for some probability distributions, there is no guarantee that the least-squares solution is even possible given the observations; still, in such cases it is the best estimator that is both linear and unbiased.



For example, it is easy to show that the arithmetic mean of a set of measurements of a quantity is the least-squares estimator of the value of that quantity. If the conditions of the Gauss–Markov theorem apply, the arithmetic mean is optimal, whatever the distribution of errors of the measurements might be.
However, in the case that the experimental errors do belong to a normal distribution, the least-squares estimator is also a maximum likelihood estimator.[11]
These properties underpin the use of the method of least squares for all types of data fitting, even when the assumptions are not strictly valid.
Limitations
An assumption underlying the treatment given above is that the independent variable, x, is free of error. In practice, the errors on the measurements of the independent variable are usually much smaller than the errors on the dependent variable and can therefore be ignored. When this is not the case, total least squares or more generally errors-in-variables models, or rigorous least squares, should be used. This can be done by adjusting the weighting scheme to take into account errors on both the dependent and independent variables and then following the standard procedure.[12][13]
In some cases the (weighted) normal equations matrix XTX is ill-conditioned. When fitting polynomials the normal equations matrix is a Vandermonde matrix. Vandermonde matrices become increasingly ill-conditioned as the order of the matrix increases. In these cases, the least squares estimate amplifies the measurement noise and may be grossly inaccurate. Various regularization techniques can be applied in such cases, the most common of which is called ridge regression. If further information about the parameters is known, for example, a range of possible values of , then various techniques can be used to increase the stability of the solution. For example, see constrained least squares.

Another drawback of the least squares estimator is the fact that the norm of the residuals, is minimized, whereas in some cases one is truly interested in obtaining small error in the parameter , e.g., a small value of . However, since the true parameter is necessarily unknown, this quantity cannot be directly minimized. If a prior probability on is known, then a Bayes estimator can be used to minimize the mean squared error, . The least squares method is often applied when no prior is known. When several parameters are being estimated jointly, better estimators can be constructed, an effect known as Stein's phenomenon. For example, if the measurement error is Gaussian, several estimators are known which dominate, or outperform, the least squares technique; the best known of these is the James–Stein estimator. This is an example of more general shrinkage estimators that have been applied to regression problems.




Applications

- Polynomial fitting: models are polynomials in an independent variable, x:
- Straight line: .[14]
- Quadratic: .
- Cubic, quartic and higher polynomials. For regression with high-order polynomials, the use of orthogonal polynomials is recommended.[15]
- Numerical smoothing and differentiation — this is an application of polynomial fitting.
- Multinomials in more than one independent variable, including surface fitting
- Curve fitting with B-splines[12]
- Chemometrics, Calibration curve, Standard addition, Gran plot, analysis of mixtures


Uses in data fitting
The primary application of linear least squares is in data fitting. Given a set of m data points consisting of experimentally measured values taken at m values of an independent variable ( may be scalar or vector quantities), and given a model function with it is desired to find the parameters such that the model function "best" fits the data. In linear least squares, linearity is meant to be with respect to parameters so








Here, the functions may be nonlinear with respect to the variable x.

Ideally, the model function fits the data exactly, so

for all This is usually not possible in practice, as there are more data points than there are parameters to be determined. The approach chosen then is to find the minimal possible value of the sum of squares of the residuals


so to minimize the function

After substituting for and then for , this minimization problem becomes the quadratic minimization problem above with



and the best fit can be found by solving the normal equations.
Example
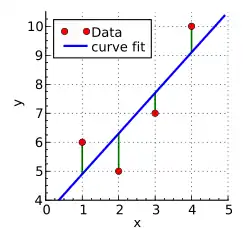
A hypothetical researcher conducts an experiment and obtains four data points: and (shown in red in the diagram on the right). Because of exploratory data analysis or prior knowledge of the subject matter, the researcher suspects that the -values depend on the -values systematically. The -values are assumed to be exact, but the -values contain some uncertainty or "noise", because of the phenomenon being studied, imperfections in the measurements, etc.






Fitting a line
One of the simplest possible relationships between and is a line . The intercept and the slope are initially unknown. The researcher would like to find values of and that cause the line to pass through the four data points. In other words, the researcher would like to solve the system of linear equations




With four equations in two unknowns, this system is overdetermined. There is no exact solution. To consider approximate solutions, one introduces residuals , , , into the equations:





The th residual is the misfit between the th observation and the th prediction :




Among all approximate solutions, the researcher would like to find the one that is "best" in some sense.
In least squares, one focuses on the sum of the squared residuals:

![{\displaystyle {\begin{aligned}S(\beta _{1},\beta _{2})&=r_{1}^{2}+r_{2}^{2}+r_{3}^{2}+r_{4}^{2}\\[6pt]&=[6-(\beta _{1}+1\beta _{2})]^{2}+[5-(\beta _{1}+2\beta _{2})]^{2}+[7-(\beta _{1}+3\beta _{2})]^{2}+[10-(\beta _{1}+4\beta _{2})]^{2}\\[6pt]&=4\beta _{1}^{2}+30\beta _{2}^{2}+20\beta _{1}\beta _{2}-56\beta _{1}-154\beta _{2}+210.\\[6pt]\end{aligned}}}](../I/73568a38878f3247e5109634c8b9c0feb8aec572.svg)
The best solution is defined to be the one that minimizes with respect to and . The minimum can be calculated by setting the partial derivatives of to zero:


These normal equations constitute a system of two linear equations in two unknowns. The solution is and , and the best-fit line is therefore . The residuals are and (see the diagram on the right). The minimum value of the sum of squared residuals is








This calculation can be expressed in matrix notation as follows. The original system of equations is , where

![{\displaystyle \mathbf {y} =\left[{\begin{array}{c}6\\5\\7\\10\end{array}}\right],\;\;\;\;\mathbf {X} =\left[{\begin{array}{cc}1&1\\1&2\\1&3\\1&4\end{array}}\right],\;\;\;\;\mathbf {\beta } =\left[{\begin{array}{c}\beta _{1}\\\beta _{2}\end{array}}\right].}](../I/5a977b4270d3aea582aca39dfa2f171a6be8ef85.svg)
Intuitively,
![{\displaystyle \mathbf {y} =\mathbf {X} \mathbf {\beta } \;\;\;\;\Rightarrow \;\;\;\;\mathbf {X} ^{\top }\mathbf {y} =\mathbf {X} ^{\top }\mathbf {X} \mathbf {\beta } \;\;\;\;\Rightarrow \;\;\;\;\mathbf {\beta } =\left(\mathbf {X} ^{\top }\mathbf {X} \right)^{-1}\mathbf {X} ^{\top }\mathbf {y} =\left[{\begin{array}{c}3.5\\1.4\end{array}}\right].}](../I/6601a0a4914bf25e822c82c177e587ca0c765498.svg)
More rigorously, if is invertible, then the matrix represents orthogonal projection onto the column space of . Therefore, among all vectors of the form , the one closest to is . Setting





it is evident that is a solution.

Fitting a parabola



Suppose that the hypothetical researcher wishes to fit a parabola of the form . Importantly, this model is still linear in the unknown parameters (now just ), so linear least squares still applies. The system of equations incorporating residuals is


The sum of squared residuals is

There is just one partial derivative to set to 0:

The solution is , and the fit model is .


In matrix notation, the equations without residuals are again , where now
![{\displaystyle \mathbf {y} =\left[{\begin{array}{c}6\\5\\7\\10\end{array}}\right],\;\;\;\;\mathbf {X} =\left[{\begin{array}{c}1\\4\\9\\16\end{array}}\right],\;\;\;\;\mathbf {\beta } =\left[{\begin{array}{c}\beta _{1}\end{array}}\right].}](../I/63480bd9450a9c75e38ab6145bd94b0404edbfe1.svg)
By the same logic as above, the solution is
![{\displaystyle \mathbf {\beta } =\left(\mathbf {X} ^{\top }\mathbf {X} \right)^{-1}\mathbf {X} ^{\top }\mathbf {y} =\left[{\begin{array}{c}0.703\end{array}}\right].}](../I/0014be5bec397d685e5aa5f20acab93fcc8ee8ee.svg)
The figure shows an extension to fitting the three parameter parabola using a design matrix with three columns (one for , , and ), and one row for each of the red data points.



Fitting other curves and surfaces
More generally, one can have regressors , and a linear model


See also
References
- ↑ Weisstein, Eric W. "Normal Equation". MathWorld. Wolfram. Retrieved December 18, 2023.
- ↑ Lai, T.L.; Robbins, H.; Wei, C.Z. (1978). "Strong consistency of least squares estimates in multiple regression". PNAS. 75 (7): 3034–3036. Bibcode:1978PNAS...75.3034L. doi:10.1073/pnas.75.7.3034. JSTOR 68164. PMC 392707. PMID 16592540.
- ↑ del Pino, Guido (1989). "The Unifying Role of Iterative Generalized Least Squares in Statistical Algorithms". Statistical Science. 4 (4): 394–403. doi:10.1214/ss/1177012408. JSTOR 2245853.
- ↑ Carroll, Raymond J. (1982). "Adapting for Heteroscedasticity in Linear Models". The Annals of Statistics. 10 (4): 1224–1233. doi:10.1214/aos/1176345987. JSTOR 2240725.
- ↑ Cohen, Michael; Dalal, Siddhartha R.; Tukey, John W. (1993). "Robust, Smoothly Heterogeneous Variance Regression". Journal of the Royal Statistical Society, Series C. 42 (2): 339–353. JSTOR 2986237.
- ↑ Nievergelt, Yves (1994). "Total Least Squares: State-of-the-Art Regression in Numerical Analysis". SIAM Review. 36 (2): 258–264. doi:10.1137/1036055. JSTOR 2132463.
- ↑ Britzger, Daniel (2022). "The Linear Template Fit". Eur. Phys. J. C. 82 (8): 731. arXiv:2112.01548. Bibcode:2022EPJC...82..731B. doi:10.1140/epjc/s10052-022-10581-w. S2CID 244896511.
- ↑ Tofallis, C (2009). "Least Squares Percentage Regression". Journal of Modern Applied Statistical Methods. 7: 526–534. doi:10.2139/ssrn.1406472. hdl:2299/965. SSRN 1406472.
- ↑ Hamilton, W. C. (1964). Statistics in Physical Science. New York: Ronald Press.
- ↑ Spiegel, Murray R. (1975). Schaum's outline of theory and problems of probability and statistics. New York: McGraw-Hill. ISBN 978-0-585-26739-5.
- ↑ Margenau, Henry; Murphy, George Moseley (1956). The Mathematics of Physics and Chemistry. Princeton: Van Nostrand.
- 1 2 Gans, Peter (1992). Data fitting in the Chemical Sciences. New York: Wiley. ISBN 978-0-471-93412-7.
- ↑ Deming, W. E. (1943). Statistical adjustment of Data. New York: Wiley.
- ↑ Acton, F. S. (1959). Analysis of Straight-Line Data. New York: Wiley.
- ↑ Guest, P. G. (1961). Numerical Methods of Curve Fitting. Cambridge: Cambridge University Press.
Further reading
- Bevington, Philip R.; Robinson, Keith D. (2003). Data Reduction and Error Analysis for the Physical Sciences. McGraw-Hill. ISBN 978-0-07-247227-1.
External links
| Computational statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Correlation and dependence | |||||||||
| Regression analysis | |||||||||
| Regression as a statistical model |
| ||||||||
| Decomposition of variance | |||||||||
| Model exploration | |||||||||
| Background | |||||||||
| Design of experiments | |||||||||
| Numerical approximation | |||||||||
| Applications | |||||||||
| |||||||||