Modern Hopfield networks[1][2] (also known as Dense Associative Memories[3]) are generalizations of the classical Hopfield networks that break the linear scaling relationship between the number of input features and the number of stored memories. This is achieved by introducing stronger non-linearities (either in the energy function or neurons’ activation functions) leading to super-linear[3] (even an exponential[4]) memory storage capacity as a function of the number of feature neurons. The network still requires a sufficient number of hidden neurons.[5]
The key theoretical idea behind the Modern Hopfield networks is to use an energy function and an update rule that is more sharply peaked around the stored memories in the space of neuron’s configurations compared to the classical Hopfield network.[3]
Classical Hopfield networks
Hopfield networks[6][7] are recurrent neural networks with dynamical trajectories converging to fixed point attractor states and described by an energy function. The state of each model neuron is defined by a time-dependent variable , which can be chosen to be either discrete or continuous. A complete model describes the mathematics of how the future state of activity of each neuron depends on the known present or previous activity of all the neurons.


In the original Hopfield model of associative memory,[6] the variables were binary, and the dynamics were described by a one-at-a-time update of the state of the neurons. An energy function quadratic in the was defined, and the dynamics consisted of changing the activity of each single neuron only if doing so would lower the total energy of the system. This same idea was extended to the case of being a continuous variable representing the output of neuron , and being a monotonic function of an input current. The dynamics became expressed as a set of first-order differential equations for which the "energy" of the system always decreased.[7] The energy in the continuous case has one term which is quadratic in the (as in the binary model), and a second term which depends on the gain function (neuron's activation function). While having many desirable properties of associative memory, both of these classical systems suffer from a small memory storage capacity, which scales linearly with the number of input features.[6]

Discrete variables
A simple example[3] of the Modern Hopfield network can be written in terms of binary variables that represent the active and inactive state of the model neuron .



In this formula the weights represent the matrix of memory vectors (index enumerates different memories, and index enumerates the content of each memory corresponding to the -th feature neuron), and the function is a rapidly growing non-linear function. The update rule for individual neurons (in the asynchronous case) can be written in the following form




![{\displaystyle V_{i}^{(t+1)}=\operatorname {sign} {\bigg [}\sum \limits _{\mu =1}^{N_{\text{mem}}}{\bigg (}F{\Big (}\xi _{\mu i}+\sum \limits _{j\neq i}\xi _{\mu j}V_{j}^{(t)}{\Big )}-F{\Big (}-\xi _{\mu i}+\sum \limits _{j\neq i}\xi _{\mu j}V_{j}^{(t)}{\Big )}{\bigg )}{\bigg ]}}](../I/586059565d4ce854be961dd9e94a984fd15ec901.svg)
which states that in order to calculate the updated state of the -th neuron the network compares two energies: the energy of the network with the -th neuron in the ON state and the energy of the network with the -th neuron in the OFF state, given the states of the remaining neuron. The updated state of the -th neuron selects the state that has the lowest of the two energies.[3]
In the limiting case when the non-linear energy function is quadratic these equations reduce to the familiar energy function and the update rule for the classical binary Hopfield network.[6]

The memory storage capacity of these networks can be calculated for random binary patterns. For the power energy function the maximal number of memories that can be stored and retrieved from this network without errors is given by[3]


For an exponential energy function the memory storage capacity is exponential in the number of feature neurons[4]


Continuous variables
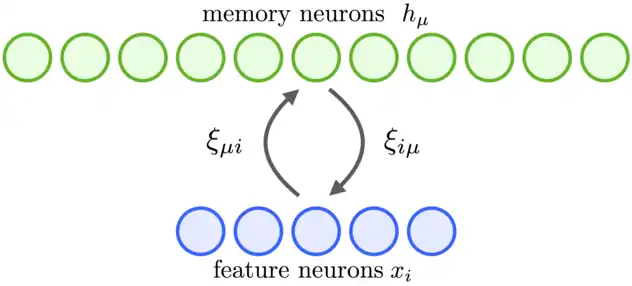


Modern Hopfield networks or Dense Associative Memories can be best understood in continuous variables and continuous time.[1][5] Consider the network architecture, shown in Fig.1, and the equations for the neurons' state evolution[5]
-
(1)

where the currents of the feature neurons are denoted by , and the currents of the memory neurons are denoted by ( stands for hidden neurons). There are no synaptic connections among the feature neurons or the memory neurons. A matrix denotes the strength of synapses from a feature neuron to the memory neuron . The synapses are assumed to be symmetric, so that the same value characterizes a different physical synapse from the memory neuron to the feature neuron . The outputs of the memory neurons and the feature neurons are denoted by and , which are non-linear functions of the corresponding currents. In general these outputs can depend on the currents of all the neurons in that layer so that and . It is convenient to define these activation function as derivatives of the Lagrangian functions for the two groups of neurons









-
(2)

This way the specific form of the equations for neuron's states is completely defined once the Lagrangian functions are specified. Finally, the time constants for the two groups of neurons are denoted by and , is the input current to the network that can be driven by the presented data.




General systems of non-linear differential equations can have many complicated behaviors that can depend on the choice of the non-linearities and the initial conditions. For Hopfield networks, however, this is not the case - the dynamical trajectories always converge to a fixed point attractor state. This property is achieved because these equations are specifically engineered so that they have an underlying energy function[5]
-
(3)
![{\displaystyle E(t)={\Big [}\sum \limits _{i=1}^{N_{f}}(x_{i}-I_{i})g_{i}-L_{x}{\Big ]}+{\Big [}\sum \limits _{\mu =1}^{N_{h}}h_{\mu }f_{\mu }-L_{h}{\Big ]}-\sum \limits _{\mu ,i}f_{\mu }\xi _{\mu i}g_{i}}](../I/49e7d96e213a43700492bcdcc56832be110a2f0d.svg)
The terms grouped into square brackets represent a Legendre transform of the Lagrangian function with respect to the states of the neurons. If the Hessian matrices of the Lagrangian functions are positive semi-definite, the energy function is guaranteed to decrease on the dynamical trajectory[5]
-
(4)

This property makes it possible to prove that the system of dynamical equations describing temporal evolution of neurons' activities will eventually reach a fixed point attractor state.
In certain situations one can assume that the dynamics of hidden neurons equilibrates at a much faster time scale compared to the feature neurons, . In this case the steady state solution of the second equation in the system (1) can be used to express the currents of the hidden units through the outputs of the feature neurons. This makes it possible to reduce the general theory (1) to an effective theory for feature neurons only. The resulting effective update rules and the energies for various common choices of the Lagrangian functions are shown in Fig.2. In the case of log-sum-exponential Lagrangian function the update rule (if applied once) for the states of the feature neurons is the attention mechanism[1] commonly used in many modern AI systems (see Ref.[5] for the derivation of this result from the continuous time formulation).

Relationship to classical Hopfield network with continuous variables
Classical formulation of continuous Hopfield networks[6] can be understood[5] as a special limiting case of the Modern Hopfield networks with one hidden layer. Continuous Hopfield Networks for neurons with graded response are typically described[6] by the dynamical equations
-
(5)

and the energy function
-
(6)

where , and is the inverse of the activation function . This model is a special limit of the class of models that is called models A,[5] with the following choice of the Lagrangian functions



-
(7)

that, according to the definition (2), leads to the activation functions
-
(8)

If we integrate out the hidden neurons the system of equations (1) reduces to the equations on the feature neurons (5) with , and the general expression for the energy (3) reduces to the effective energy

-
(9)

While the first two terms in equation (6) are the same as those in equation (9), the third terms look superficially different. In equation (9) it is a Legendre transform of the Lagrangian for the feature neurons, while in (6) the third term is an integral of the inverse activation function. Nevertheless, these two expressions are in fact equivalent, since the derivatives of a function and its Legendre transform are inverse functions of each other. The easiest way to see that these two terms are equal explicitly is to differentiate each one with respect to . The results of these differentiations for both expressions are equal to . Thus, the two expressions are equal up to an additive constant. This completes the proof[5] that the classical Hopfield network with continuous states[6] is a special limiting case of the modern Hopfield network (1) with energy (3).


General formulation of the modern Hopfield network
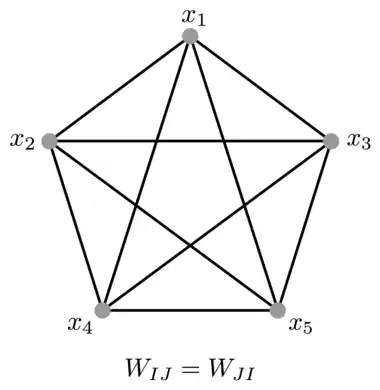

Biological neural networks have a large degree of heterogeneity in terms of different cell types. This section describes a mathematical model of a fully connected Modern Hopfield network assuming the extreme degree of heterogeneity: every single neuron is different.[8] Specifically, an energy function and the corresponding dynamical equations are described assuming that each neuron has its own activation function and kinetic time scale. The network is assumed to be fully connected, so that every neuron is connected to every other neuron using a symmetric matrix of weights , indices and enumerate different neurons in the network, see Fig.3. The easiest way to mathematically formulate this problem is to define the architecture through a Lagrangian function that depends on the activities of all the neurons in the network. The activation function for each neuron is defined as a partial derivative of the Lagrangian with respect to that neuron's activity



-
(10)

From the biological perspective one can think about as an axonal output of the neuron . In the simplest case, when the Lagrangian is additive for different neurons, this definition results in the activation that is a non-linear function of that neuron's activity. For non-additive Lagrangians this activation function can depend on the activities of a group of neurons. For instance, it can contain contrastive (softmax) or divisive normalization. The dynamical equations describing temporal evolution of a given neuron are given by[8]

-
(11)

This equation belongs to the class of models called firing rate models in neuroscience. Each neuron collects the axonal outputs from all the neurons, weights them with the synaptic coefficients and produces its own time-dependent activity . The temporal evolution has a time constant , which in general can be different for every neuron. This network has a global energy function[8]



-
(12)

where the first two terms represent the Legendre transform of the Lagrangian function with respect to the neurons' currents . The temporal derivative of this energy function can be computed on the dynamical trajectories leading to (see [8] for details)
-
(13)

The last inequality sign holds provided that the matrix (or its symmetric part) is positive semi-definite. If, in addition to this, the energy function is bounded from below the non-linear dynamical equations are guaranteed to converge to a fixed point attractor state. The advantage of formulating this network in terms of the Lagrangian functions is that it makes it possible to easily experiment with different choices of the activation functions and different architectural arrangements of neurons. For all those flexible choices the conditions of convergence are determined by the properties of the matrix and the existence of the lower bound on the energy function.


Hierarchical associative memory network
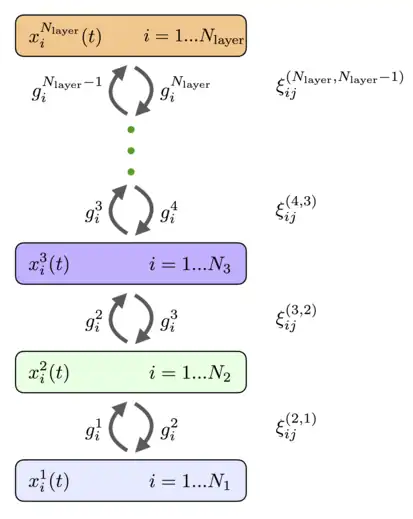
The neurons can be organized in layers so that every neuron in a given layer has the same activation function and the same dynamic time scale. If we assume that there are no horizontal connections between the neurons within the layer (lateral connections) and there are no skip-layer connections, the general fully connected network (11), (12) reduces to the architecture shown in Fig.4. It has layers of recurrently connected neurons with the states described by continuous variables and the activation functions , index enumerates the layers of the network, and index enumerates individual neurons in that layer. The activation functions can depend on the activities of all the neurons in the layer. Every layer can have a different number of neurons . These neurons are recurrently connected with the neurons in the preceding and the subsequent layers. The matrices of weights that connect neurons in layers and are denoted by (the order of the upper indices for weights is the same as the order of the lower indices, in the example above this means that the index enumerates neurons in the layer , and index enumerates neurons in the layer ). The feedforward weights and the feedback weights are equal. The dynamical equations for the neurons' states can be written as[8]








-
(14)

with boundary conditions
-
(15)

The main difference of these equations from the conventional feedforward networks is the presence of the second term, which is responsible for the feedback from higher layers. These top-down signals help neurons in lower layers to decide on their response to the presented stimuli. Following the general recipe it is convenient to introduce a Lagrangian function for the -th hidden layer, which depends on the activities of all the neurons in that layer.[8] The activation functions in that layer can be defined as partial derivatives of the Lagrangian

-
(16)

With these definitions the energy (Lyapunov) function is given by[8]
-
(17)
![{\displaystyle E=\sum \limits _{A=1}^{N_{\text{layer}}}{\Big [}\sum \limits _{i=1}^{N_{A}}x_{i}^{A}g_{i}^{A}-L^{A}{\Big ]}-\sum \limits _{A=1}^{N_{\text{layer}}-1}\sum \limits _{i=1}^{N_{A+1}}\sum \limits _{j=1}^{N_{A}}g_{i}^{A+1}\xi _{ij}^{(A+1,A)}g_{j}^{A}}](../I/087774b10637a0e122dd10a4f8e5893df2aca372.svg)
If the Lagrangian functions, or equivalently the activation functions, are chosen in such a way that the Hessians for each layer are positive semi-definite and the overall energy is bounded from below, this system is guaranteed to converge to a fixed point attractor state. The temporal derivative of this energy function is given by[8]
-
(18)

Thus, the hierarchical layered network is indeed an attractor network with the global energy function. This network is described by a hierarchical set of synaptic weights that can be learned for each specific problem.
References
- 1 2 3 4 Ramsauer, Hubert; et al. (2021). "Hopfield Networks is All You Need". International Conference on Learning Representations. arXiv:2008.02217.
- ↑ "Hopfield Networks is All You Need". hopfield-layers. 2020-08-25. Archived from the original on 26 Mar 2023. Retrieved 2023-05-04.
- 1 2 3 4 5 6 7 Krotov, Dmitry; Hopfield, John (2016). "Dense Associative Memory for Pattern Recognition". Neural Information Processing Systems. 29: 1172–1180. arXiv:1606.01164.
- 1 2 3 Demircigil, Mete; et al. (2017). "On a model of associative memory with huge storage capacity". Journal of Statistical Physics. 168 (2): 288–299. arXiv:1702.01929. Bibcode:2017JSP...168..288D. doi:10.1007/s10955-017-1806-y. S2CID 119317128.
- 1 2 3 4 5 6 7 8 9 10 Krotov, Dmitry; Hopfield, John (2021). "Large associative memory problem in neurobiology and machine learning". International Conference on Learning Representations. arXiv:2008.06996.
- 1 2 3 4 5 6 7 Hopfield, John (1982). "Neural networks and physical systems with emergent collective computational abilities". Proceedings of the National Academy of Sciences. 79 (8): 2554–2558. Bibcode:1982PNAS...79.2554H. doi:10.1073/pnas.79.8.2554. PMC 346238. PMID 6953413.
- 1 2 Hopfield, John (1984). "Neurons with graded response have collective computational properties like those of two-state neurons". Proceedings of the National Academy of Sciences. 81 (10): 3088–3092. Bibcode:1984PNAS...81.3088H. doi:10.1073/pnas.81.10.3088. PMC 345226. PMID 6587342.
- 1 2 3 4 5 6 7 8 9 Krotov, Dmitry (2021). "Hierarchical Associative Memory". arXiv:2107.06446 [cs.NE].