Re-Pair (short for recursive pairing) is a grammar-based compression algorithm that, given an input text, builds a straight-line program, i.e. a context-free grammar generating a single string: the input text. In order to perform the compression in linear time, it consumes the amount of memory that is approximately five times the size of its input.
The grammar is built by recursively replacing the most frequent pair of characters occurring in the text. Once there is no pair of characters occurring twice, the resulting string is used as the axiom of the grammar. Therefore, the output grammar is such that all rules but the axiom have two symbols on the right-hand side.
How it works

Re-Pair was first introduced by NJ. Larsson and A. Moffat[1] in 1999.
In their paper the algorithm is presented together with a detailed description of the data structures required to implement it with linear time and space complexity. The experiments showed that Re-Pair achieves high compression ratios and offers good performance for decompression. However, the major drawback of the algorithm is its memory consumption, which is approximately 5 times the size of the input. Such memory usage is required in order to perform the compression in linear time but makes the algorithm impractical for compressing large files.
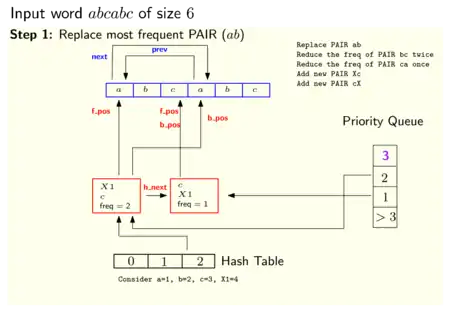
The image on the right shows how the algorithm works compresses the string .

During the first iteration, the pair , which occurs three times in , is replaced by a new symbol . On the second iteration, the most frequent pair in the string , which is , is replaced by a new symbol . Thus, at the end of the second iteration, the remaining string is . In the next two iterations, the pairs and are replaced by symbols and respectively. Finally, the string contains no repeated pair and therefore it is used as the axiom of the output grammar.












Data structures
In order to achieve linear time complexity, Re-Pair requires the following data structures
- A sequence representing the input string. Position of the sequence contains the i-th symbol of the input string plus two references to other positions in the sequence. These references point to the next/previous positions, say and , such that the same substring begins at , and and all three occurrences are captured by the same reference (i.e. there is a variable in the grammar generating the string).
- A priority queue. Each element of the queue is a pair of symbols (terminals or previously defined pairs) that occur consecutively in the sequence. The priority of a pair is given by the number of occurrences of the pair in the remaining sequence. Each time a new pair is created, the priority queue is updated.
- A hash table to keep track of already defined pairs. This table is updated each time a new pair is created or removed.



![{\displaystyle w[i]}](../I/08d28112e853d36fe2eddd7c8ea21076d1882e62.svg)
![w[k]](../I/d09bad62897ec16cdf68b3d95bbe8f2013793bb6.svg)
![{\displaystyle w[m]}](../I/48a05de352d329b45ff39c627a144b4fcc07fa25.svg)
Since the hash table and the priority queue refer to the same elements (pairs), they can be implemented by a common data structure called PAIR with pointers for the hash table (h_next) and the priority queue (p_next and p_prev). Furthermore, each PAIR points to the beginning of the first (f_pos) and the last (b_pos) occurrences of the string represented by the PAIR in the sequence. The following picture shows an overview of this data structure.
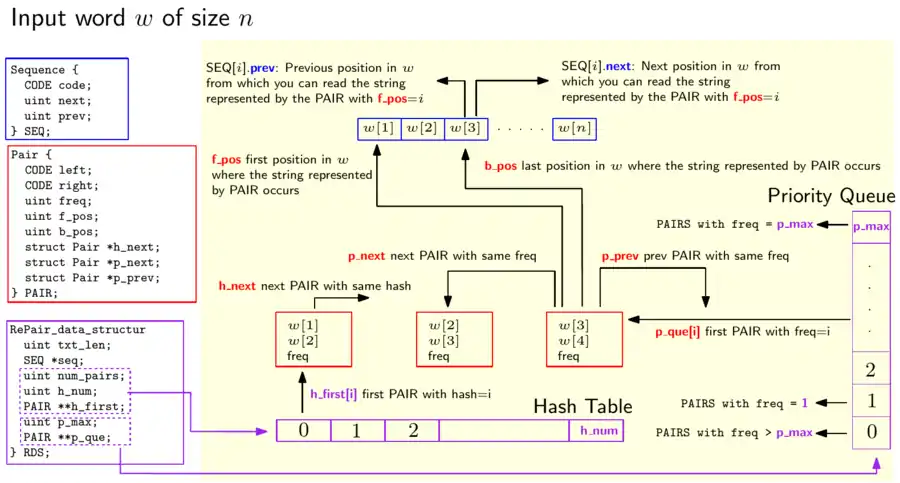
The following two pictures show an example of how these data structures look after the initialization and after applying one step of the pairing process (pointers to NULL are not displayed):

Encoding the grammar
Once the grammar has been built for a given input string, in order to achieve effective compression, this grammar has to be encoded efficiently.
One of the simplest methods for encoding the grammar is the implicit encoding, which consists on invoking function encodeCFG(X), described below, sequentially on all the axiom's symbols.
Intuitively, rules are encoded as they are visited in a depth-first traversal of the grammar. The first time a rule is visited, its right hand side is encoded recursively and a new code is assigned to the rule. From that point, whenever the rule is reached, the assigned value is written.
num_rules_encoded = 256 // By default, the extended ASCII charset are the terminals of the grammar.
writeSymbol(symbol s) {
bitslen = log(num_rules_encoded); // Initially 8, to describe any extended ASCII character
write s in binary using bitslen bits
}
void encodeCFG_rec(symbol s) {
if (s is non-terminal and this is the first time symbol s appears) {
take rule s → X Y;
write bit 1;
encodeCFG_rec(X);
encodeCFG_rec(Y);
assign to symbol s value ++num_rules_encoded;
} else {
write bit 0;
writeSymbol(terminal/value assigned)
}
}
void encodeCFG(symbol s) {
encodeCFG_rec(s);
write bit 1;
}
Another possibility is to separate the rules of the grammar into generations such that a rule belongs to generation iff at least one of or belongs to generation and the other belongs to generation with . Then these generations are encoded subsequently starting from generation . This was the method proposed originally when Re-Pair was first introduced. However, most implementations of Re-Pair use the implicit encoding method due to its simplicity and good performance. Furthermore, it allows on-the-fly decompression.







Versions
There exists a number of different implementations of Re-Pair. Each of these versions aims at improving one specific aspect of the algorithm, such as reducing the runtime, reducing the space consumption or increasing the compression ratio.
| Improvement | Year | Implementation | Description |
|---|---|---|---|
| Phrase Browsing[2] | 2003 | Instead of manipulating the input string as a sequence of characters, this tool first groups the characters into phrases (for instance, words). The compression algorithm works as Re-Pair but considering the identified phrases as the terminals of the grammar. The tool accepts different options to decide which sort of phrases are considered and encodes the resulting grammar into separated files: one containing the axiom and one with the rest of the rules. | |
| Original | 2011 | This is one of the most popular implementations of Re-Pair. It uses the data structures described here (the ones proposed when it was originally published[1]) and encodes the resulting grammar using the implicit encoding method. Most later versions of Re-Pair are implemented starting from this one. | |
| Encoding[3] | 2013 | Instead of the implicit encoding method, this implementation uses a Variable Length to Fixed Length method, in which each rule (represented with a string of Variable Length) is encoded using a code of Fixed Length. | |
| Memory usage[4] | 2017 | The algorithm performs in two phases. During the first phase, it considers the high frequency pairs, i.e. those occurring more than times, while the low frequency pairs are considered in the second. The main difference between the two phases is the implementation of the corresponding priority queues. | |
| Compression[5] | 2017 | This version modifies the way the next pair to be replaced is chosen. Instead of simply considering the most frequent pair, it employs a heuristic which penalizes pairs that are not coherent with a Lempel–Ziv factorisation of the input string. | |
| Compression[6] | 2018 | This algorithm reduces the size of the grammar generated by Re-Pair by replacing maximal repeats first. When a pair is identified as the most frequent pair, i.e. the one to be replaced in the current step of the algorithm, MR-repair extends the pair to find the longest string that occurs the same number of times as the pair to be replaced. The provided implementation encodes the grammar by simply listing the rules in text, hence this tool is purely for research purposes and cannot be used for compression as it is. |

See also
References
- 1 2 Larsson, N. J., & Moffat, A. (2000). Off-line dictionary-based compression. Proceedings of the IEEE, 88(11), 1722–1732.
- ↑ R. Wan. "Browsing and Searching Compressed Documents". PhD thesis, University of Melbourne, Australia, December 2003.
- ↑ Satoshi Yoshida and Takuya Kida, Effective Variable-Length-to-Fixed-Length Coding via a Re-Pair Algorithm, In Proc. of Data Compression Conference 2013 (DCC 2013), p. 532, Snowbird, Utah, USA, March 2013.
- ↑ Bille, P., Gørtz, I. L., & Prezza, N. (2017, April). Space-efficient re-pair compression. In 2017 (DCC) (pp. 171-180). IEEE.
- ↑ Gańczorz, M., & Jeż, A. (2017, April). Improvements on Re-Pair grammar compressor. In 2017 Data Compression Conference (DCC) (pp. 181–190). IEEE.
- ↑ Furuya, I., Takagi, T., Nakashima, Y., Inenaga, S., Bannai, H., & Kida, T. (2018). MR-RePair: Grammar Compression based on Maximal Repeats. arXiv preprint arXiv:1811.04596.
Data compression methods | |||||||
|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||
| Lossy |
| ||||||
| Audio |
| ||||||
| Image |
| ||||||
| Video |
| ||||||
| Theory | |||||||
| |||||||