Pointer jumping or path doubling is a design technique for parallel algorithms that operate on pointer structures, such as linked lists and directed graphs. Pointer jumping allows an algorithm to follow paths with a time complexity that is logarithmic with respect to the length of the longest path. It does this by "jumping" to the end of the path computed by neighbors.
The basic operation of pointer jumping is to replace each neighbor in a pointer structure with its neighbor's neighbor. In each step of the algorithm, this replacement is done for all nodes in the data structure, which can be done independently in parallel. In the next step when a neighbor's neighbor is followed, the neighbor's path already followed in the previous step is added to the node's followed path in a single step. Thus, each step effectively doubles the distance traversed by the explored paths.
Pointer jumping is best understood by looking at simple examples such as list ranking and root finding.
List ranking
One of the simpler tasks that can be solved by a pointer jumping algorithm is the list ranking problem. This problem is defined as follows: given a linked list of N nodes, find the distance (measured in the number of nodes) of each node to the end of the list. The distance d(n) is defined as follows, for nodes n that point to their successor by a pointer called next:
- If n.next is nil, then d(n) = 0.
- For any other node, d(n) = d(n.next) + 1.
This problem can easily be solved in linear time on a sequential machine, but a parallel algorithm can do better: given n processors, the problem can be solved in logarithmic time, O(log N), by the following pointer jumping algorithm:[1]: 693
- Allocate an array of N integers.
- Initialize: for each processor/list node n, in parallel:
- If n.next = nil, set d[n] ← 0.
- Else, set d[n] ← 1.
- While any node n has n.next ≠ nil:
- For each processor/list node n, in parallel:
- If n.next ≠ nil:
- Set d[n] ← d[n] + d[n.next].
- Set n.next ← n.next.next.
- If n.next ≠ nil:
- For each processor/list node n, in parallel:
The pointer jumping occurs in the last line of the algorithm, where each node's next pointer is reset to skip the node's direct successor. It is assumed, as in common in the PRAM model of computation, that memory access are performed in lock-step, so that each n.next.next memory fetch is performed before each n.next memory store; otherwise, processors may clobber each other's data, producing inconsistencies.[1]: 694
The following diagram follows how the parallel list ranking algorithm uses pointer jumping for a linked list with 11 elements. As the algorithm describes, the first iteration starts initialized with all ranks set to 1 except those with a null pointer for next. The first iteration looks at immediate neighbors. Each subsequent iteration jumps twice as far as the previous.

Analyzing the algorithm yields a logarithmic running time. The initialization loop takes constant time, because each of the N processors performs a constant amount of work, all in parallel. The inner loop of the main loop also takes constant time, as does (by assumption) the termination check for the loop, so the running time is determined by how often this inner loop is executed. Since the pointer jumping in each iteration splits the list into two parts, one consisting of the "odd" elements and one of the "even" elements, the length of the list pointed to by each processor's n is halved in each iteration, which can be done at most O(log N) time before each list has a length of at most one.[1]: 694–695
Root finding
Following a path in a graph is an inherently serial operation, but pointer jumping reduces the total amount of work by following all paths simultaneously and sharing results among dependent operations. Pointer jumping iterates and finds a successor — a vertex closer to the tree root — each time. By following successors computed for other vertices, the traversal down each path can be doubled every iteration, which means that the tree roots can be found in logarithmic time.
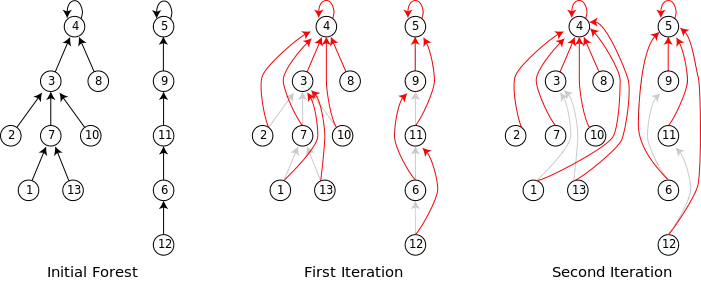
Pointer doubling operates on an array successor with an entry for every vertex in the graph. Each successor[i] is initialized with the parent index of vertex i if that vertex is not a root or to i itself if that vertex is a root. At each iteration, each successor is updated to its successor's successor. The root is found when the successor's successor points to itself.
The following pseudocode demonstrates the algorithm.
algorithm
Input: An array parent representing a forest of trees. parent[i] is the parent of vertex i or itself for a root
Output: An array containing the root ancestor for every vertex
for i ← 1 to length(parent) do in parallel
successor[i] ← parent[i]
while true
for i ← 1 to length(successor) do in parallel
successor_next[i] ← successor[successor[i]]
if successor_next = successor then
break
for i ← 1 to length(successor) do in parallel
successor[i] ← successor_next[i]
return successor
The following image provides an example of using pointer jumping on a small forest. On each iteration the successor points to the vertex following one more successor. After two iterations, every vertex points to its root node.
History and examples
Although the name pointer jumping would come later, JáJá[2]: 88 attributes the first uses of the technique in early parallel graph algorithms[3][4]: 43 and list ranking.[5] The technique has been described with other names such as shortcutting,[6][7] but by the 1990s textbooks on parallel algorithms consistently used the term pointer jumping.[2]: 52–56 [1]: 692–701 [8]: 34–35 Today, pointer jumping is considered a software design pattern for operating on recursive data types in parallel.[9]: 99
As a technique for following linked paths, graph algorithms are a natural fit for pointer jumping. Consequently, several parallel graph algorithms utilizing pointer jumping have been designed. These include algorithms for finding the roots of a forest of rooted trees,[2]: 52–53 [6] connected components,[2]: 213–221 minimum spanning trees[2],: 222–227 [10] and biconnected components[2]: 227–239 [7]. However, pointer jumping has also shown to be useful in a variety of other problems including computer vision,[11] image compression,[12] and Bayesian inference.[13]
References
- 1 2 3 4 Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001) [1990]. Introduction to Algorithms (2nd ed.). MIT Press and McGraw-Hill. ISBN 0-262-03293-7.
- 1 2 3 4 5 6 JáJá, Joseph (1992). An Introduction to Parallel Algorithms. Addison Wesley. ISBN 0-201-54856-9.
- ↑ Hirschberg, D. S. (1976). "Parallel algorithms for the transitive closure and the connected component problems". Proceedings of the eighth annual ACM symposium on Theory of computing - STOC '76. pp. 55–57. doi:10.1145/800113.803631. S2CID 306043.
- ↑ Savage, Carla Diane (1977). Parallel Algorithms for Graph Theoretic Problems (Thesis). University of Illinois at Urbana-Champaign. Archived from the original on June 1, 2022.
- ↑ Wylie, James C. (1979). "Chapter 4: Computational Structures". The Complexity of Parallel Computations (Thesis). Cornell University.
- 1 2 Shiloach, Yossi; Vishkin, Uzi (1982). "An O(log n) Parallel Connectivity Algorithm". Journal of Algorithms. 3 (1): 57–67. doi:10.1016/0196-6774(82)90008-6.
- 1 2 Tarjan, Robert E; Vishkin, Uzi (1984). "Finding biconnected componemts and computing tree functions in logarithmic parallel time". 25th Annual Symposium on Foundations of Computer Science, 1984. pp. 12–20. doi:10.1109/SFCS.1984.715896. ISBN 0-8186-0591-X.
- ↑ Quinn, Michael J. (1994). Parallel Computing: Theory and Practice (2 ed.). McGraw-Hill. ISBN 0-07-051294-9.
- ↑ Mattson, Timothy G.; Sanders, Beverly A.; Massingill, Berna L. (2005). Patterns for Parallel Programming. Addison-Wesley. ISBN 0-321-22811-1.
- ↑ Chung, Sun; Condon, Anne (1996). "Parallel implementation of Bouvka's minimum spanning tree algorithm". Proceedings of International Conference on Parallel Processing. pp. 302–308. doi:10.1109/IPPS.1996.508073. ISBN 0-8186-7255-2. S2CID 12710022.
- ↑ Little, James J.; Blelloch, Guy E.; Cass, Todd A. (1989). "Algorithmic Techniques for Computer Vision on a Fine-Grained Parallel Machine". IEEE Transactions on Pattern Analysis and Machine Intelligence. 11 (3): 244–257. doi:10.1109/34.21793.
- ↑ Cook, Gregory W.; Delp, Edward J. (1994). "An investigation of JPEG image and video compression using parallel processing". Proceedings of ICASSP '94. IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 437–440. doi:10.1109/ICASSP.1994.389394. ISBN 0-7803-1775-0. S2CID 8879246.
- ↑ Namasivayam, Vasanth Krishna; Prasanna, Viktor K. (2006). Scalable Parallel Implementation of ExactInference in Bayesian Networks. 12th International Conference on Parallel and Distributed Systems - (ICPADS'06). pp. 8 pp. doi:10.1109/ICPADS.2006.96. ISBN 0-7695-2612-8. S2CID 15728730.
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |