The relational model (RM) is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd,[1][2] where all data is represented in terms of tuples, grouped into relations. A database organized in terms of the relational model is a relational database.
The purpose of the relational model is to provide a declarative method for specifying data and queries: users directly state what information the database contains and what information they want from it, and let the database management system software take care of describing data structures for storing the data and retrieval procedures for answering queries.
Most relational databases use the SQL data definition and query language; these systems implement what can be regarded as an engineering approximation to the relational model. A table in a SQL database schema corresponds to a predicate variable; the contents of a table to a relation; key constraints, other constraints, and SQL queries correspond to predicates. However, SQL databases deviate from the relational model in many details, and Codd fiercely argued against deviations that compromise the original principles.[3]
History
The relational model was developed by Edgar F. Codd as a general model of data, and subsequently promoted by Chris Date and Hugh Darwen among others. In their 1995 The Third Manifesto, Date and Darwen try to demonstrate how the relational model can accommodate certain "desired" object-oriented features.
Extensions
Some years after publication of his 1970 model, Codd proposed a three-valued logic (True, False, Missing/NULL) version of it to deal with missing information, and in his The Relational Model for Database Management Version 2 (1990) he went a step further with a four-valued logic (True, False, Missing but Applicable, Missing but Inapplicable) version.[4]
Overview
Basic Concepts
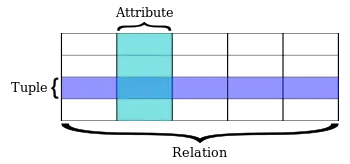
A relation consists of a heading and a body. The heading defines a set of attributes, each with a name and data type (sometimes called a domain). The number of attributes in this set is the relation's degree or arity. The body is a set of tuples. A tuple is a collection of n values, where n is the relation's degree, and each value in the tuple corresponds to a unique attribute.[nb 1] The number of tuples in this set is the relation's cardinality.[5]: 17–22
Relations are represented by relational variables or relvars, which can be reassigned.[5]: 22–24 A database is a collection of relvars.[5]: 112–113
In this model, databases follow the Information Principle: At any given time, all information in the database is represented solely by values within tuples, corresponding to attributes, in relations identified by relvars.[5]: 111
Constraints
A database may define arbitrary boolean expressions as constraints. If all constraints evaluate as true, the database is consistent; otherwise, it is inconsistent. If a change to a database's relvars would leave the database in an inconsistent state, that change is illegal and must not succeed.[5]: 91
In general, constraints are expressed using relational comparison operators, of which just one, "is subset of" (⊆), is theoretically sufficient.
Two special cases of constraints are expressed as keys and foreign keys:
Keys
A candidate key, or simply a key, is the smallest subset of attributes guaranteed to uniquely differentiate each tuple in a relation. Since each tuple in a relation must be unique, every relation necessarily has a key, which may be its complete set of attributes. A relation may have multiple keys, as there may be multiple ways to uniquely differentiate each tuple.[5]: 31–33
An attribute may be unique across tuples without being a key. For example, a relation describing a company's employees may have two attributes: ID and Name. Even if no employees currently share a name, if it is possible to eventually hire a new employee with the same name as a current employee, the attribute subset {Name} is not a key. Conversely, if the subset {ID} is a key, this means not only that no employees currently share an ID, but that no employees will ever share an ID.[5]: 31–33
Foreign Keys
A foreign key is a subset of attributes {A} in a relation R1 that corresponds with a key of another relation R2, with the property that the projection of R1 on {A} is a subset of the projection of R2 on {A}. In other words, if a tuple in R1 contains values for a foreign key, there must be a corresponding tuple in R2 containing the same values for the corresponding key.[5]: 34
Relational operations
Users (or programs) request data from a relational database by sending it a query. In response to a query, the database returns a result set.
Often, data from multiple tables are combined into one, by doing a join. Conceptually, this is done by taking all possible combinations of rows (the Cartesian product), and then filtering out everything except the answer.
There are a number of relational operations in addition to join. These include project (the process of eliminating some of the columns), restrict (the process of eliminating some of the rows), union (a way of combining two tables with similar structures), difference (that lists the rows in one table that are not found in the other), intersect (that lists the rows found in both tables), and product (mentioned above, which combines each row of one table with each row of the other). Depending on which other sources you consult, there are a number of other operators – many of which can be defined in terms of those listed above. These include semi-join, outer operators such as outer join and outer union, and various forms of division. Then there are operators to rename columns, and summarizing or aggregating operators, and if you permit relation values as attributes (relation-valued attribute), then operators such as group and ungroup.
The flexibility of relational databases allows programmers to write queries that were not anticipated by the database designers. As a result, relational databases can be used by multiple applications in ways the original designers did not foresee, which is especially important for databases that might be used for a long time (perhaps several decades). This has made the idea and implementation of relational databases very popular with businesses.
Database normalization
Relations are classified based upon the types of anomalies to which they're vulnerable. A database that is in the first normal form is vulnerable to all types of anomalies, while a database that is in the domain/key normal form has no modification anomalies. Normal forms are hierarchical in nature. That is, the lowest level is the first normal form, and the database cannot meet the requirements for higher level normal forms without first having met all the requirements of the lesser normal forms.[6]
Logical Interpretation
The relational model is a formal system. A relation's attributes define a set of logical propositions. Each proposition can be expressed as a tuple. The body of a relation is a subset of these tuples, representing which propositions are true. Constraints represent additional propositions which must also be true. Relational algebra is a set of logical rules that can validly infer conclusions from these propositions. [5]: 95–101
The definition of a tuple allows for a unique empty tuple with no values, corresponding to the empty set of attributes. If a relation has a degree of 0 (i.e. its heading contains no attributes), it may have either a cardinality of 0 (a body containing no tuples) or a cardinality of 1 (a body containing the single empty tuple). These relations represent Boolean truth values. The relation with degree 0 and cardinality 0 is False, while the relation with degree 0 and cardinality 1 is True.[5]: 221–223
Example
If a relation of Employees contains the attributes {Name, ID}, then the tuple {Alice, 1} represents the proposition: "There exists an employee named Alice with ID 1". This proposition may be true or false. If this tuple exists in the relation's body, the proposition is true (there is such an employee). If this tuple is not in the relation's body, the proposition is false (there is no such employee).[5]: 96–97
Furthermore, if {ID} is a key, then a relation containing the tuples {Alice, 1} and {Bob, 1} would represent the following contradiction:
- There exists an employee with the name Alice and the ID 1.
- There exists an employee with the name Bob and the ID 1.
- There do not exist multiple employees with the same ID.
Under the principle of explosion, this contradiction would allow the system to prove that any arbitrary proposition is true. The database must enforce the key constraint to prevent this.[5]: 104
Examples
Database
An idealized, very simple example of a description of some relvars (relation variables) and their attributes:
- Customer (Customer ID, Name)
- Order (Order ID, Customer ID, Invoice ID, Date)
- Invoice (Invoice ID, Customer ID, Order ID, Status)
In this design we have three relvars: Customer, Order, and Invoice. The bold, underlined attributes are candidate keys. The non-bold, underlined attributes are foreign keys.
Usually one candidate key is chosen to be called the primary key and used in preference over the other candidate keys, which are then called alternate keys.
A candidate key is a unique identifier enforcing that no tuple will be duplicated; this would make the relation into something else, namely a bag, by violating the basic definition of a set. Both foreign keys and superkeys (that includes candidate keys) can be composite, that is, can be composed of several attributes. Below is a tabular depiction of a relation of our example Customer relvar; a relation can be thought of as a value that can be attributed to a relvar.
Customer relation
| Customer ID | Name |
|---|---|
| 123 | Alice |
| 456 | Bob |
| 789 | Carol |
If we attempted to insert a new customer with the ID 123, this would violate the design of the relvar since Customer ID is a primary key and we already have a customer 123. The DBMS must reject a transaction such as this that would render the database inconsistent by a violation of an integrity constraint. However, it is possible to insert another customer named Alice, as long as this new customer has a unique ID, since the Name field is not part of the primary key.
Foreign keys are integrity constraints enforcing that the value of the attribute set is drawn from a candidate key in another relation. For example, in the Order relation the attribute Customer ID is a foreign key. A join is the operation that draws on information from several relations at once. By joining relvars from the example above we could query the database for all of the Customers, Orders, and Invoices. If we only wanted the tuples for a specific customer, we would specify this using a restriction condition. If we wanted to retrieve all of the Orders for Customer 123, we could query the database to return every row in the Order table with Customer ID 123 .
There is a flaw in our database design above. The Invoice relvar contains an Order ID attribute. So, each tuple in the Invoice relvar will have one Order ID, which implies that there is precisely one Order for each Invoice. But in reality an invoice can be created against many orders, or indeed for no particular order. Additionally the Order relvar contains an Invoice ID attribute, implying that each Order has a corresponding Invoice. But again this is not always true in the real world. An order is sometimes paid through several invoices, and sometimes paid without an invoice. In other words, there can be many Invoices per Order and many Orders per Invoice. This is a many-to-many relationship between Order and Invoice (also called a non-specific relationship). To represent this relationship in the database a new relvar should be introduced whose role is to specify the correspondence between Orders and Invoices:
OrderInvoice (Order ID, Invoice ID)
Now, the Order relvar has a one-to-many relationship to the OrderInvoice table, as does the Invoice relvar. If we want to retrieve every Invoice for a particular Order, we can query for all orders where Order ID in the Order relation equals the Order ID in OrderInvoice, and where Invoice ID in OrderInvoice equals the Invoice ID in Invoice.
Application to relational databases
A data type in a relational database might be the set of integers, the set of character strings, the set of dates, etc. The relational model does not dictate what types are to be supported.
Attributes are commonly represented as columns, tuples as rows, and relations as tables. A table is specified as a list of column definitions, each of which specifies a unique column name and the type of the values that are permitted for that column. An attribute value is the entry in a specific column and row.
A database relvar (relation variable) is commonly known as a base table. The heading of its assigned value at any time is as specified in the table declaration and its body is that most recently assigned to it by an update operator (typically, INSERT, UPDATE, or DELETE). The heading and body of the table resulting from evaluating a query are determined by the definitions of the operators used in that query.
SQL and the relational model
SQL, initially pushed as the standard language for relational databases, deviates from the relational model in several places. The current ISO SQL standard doesn't mention the relational model or use relational terms or concepts.
According to the relational model, a Relation's attributes and tuples are mathematical sets, meaning they are unordered and unique. In a SQL table, neither rows nor columns are proper sets. A table may contain both duplicate rows and duplicate columns, and a table's columns are explicitly ordered. SQL uses a Null value to indicate missing data, which has no analog in the relational model. Because a row can represent unknown information, SQL does not adhere to the relational model's Information Principle.[5]: 153–155, 162
Set-theoretic formulation
Basic notions in the relational model are relation names and attribute names. We will represent these as strings such as "Person" and "name" and we will usually use the variables and to range over them. Another basic notion is the set of atomic values that contains values such as numbers and strings.


Our first definition concerns the notion of tuple, which formalizes the notion of row or record in a table:
- Tuple
- A tuple is a partial function from attribute names to atomic values.
- Header
- A header is a finite set of attribute names.
- Projection
- The projection of a tuple on a finite set of attributes is .


![t[A] = \{ (a, v) : (a, v) \in t, a \in A \}](../I/9f73aac5669f24d1ad1da4c7c16d2f0d39ee6f5c.svg)
The next definition defines relation that formalizes the contents of a table as it is defined in the relational model.
- Relation
- A relation is a tuple with , the header, and , the body, a set of tuples that all have the domain .



Such a relation closely corresponds to what is usually called the extension of a predicate in first-order logic except that here we identify the places in the predicate with attribute names. Usually in the relational model a database schema is said to consist of a set of relation names, the headers that are associated with these names and the constraints that should hold for every instance of the database schema.
- Relation universe
- A relation universe over a header is a non-empty set of relations with header .
- Relation schema
- A relation schema consists of a header and a predicate that is defined for all relations with header . A relation satisfies a relation schema if it has header and satisfies .





Key constraints and functional dependencies
One of the simplest and most important types of relation constraints is the key constraint. It tells us that in every instance of a certain relational schema the tuples can be identified by their values for certain attributes.
A superkey is a set of column headers for which the values of those columns concatenated are unique across all rows. Formally:
- A superkey is written as a finite set of attribute names.
- A superkey holds in a relation if:
- and
- there exist no two distinct tuples such that .
- A superkey holds in a relation universe if it holds in all relations in .
- Theorem: A superkey holds in a relation universe over if and only if and holds in .
- Candidate key



![t_1[K] = t_2[K]](../I/4928b6dcf764d568ea802cfa2623a21fc4fb92ac.svg)

A candidate key is a superkey that cannot be further subdivided to form another superkey.
- A superkey holds as a candidate key for a relation universe if it holds as a superkey for and there is no proper subset of that also holds as a superkey for .
- Functional dependency
Functional dependency is the property that a value in a tuple may be derived from another value in that tuple.
- A functional dependency (FD for short) is written as for finite sets of attribute names.
- A functional dependency holds in a relation if:
- and
- tuples ,
- A functional dependency holds in a relation universe if it holds in all relations in .
- Trivial functional dependency
- A functional dependency is trivial under a header if it holds in all relation universes over .
- Theorem: An FD is trivial under a header if and only if .
- Closure
- Armstrong's axioms: The closure of a set of FDs under a header , written as , is the smallest superset of such that:
- (reflexivity)
- (transitivity) and
- (augmentation)
- Theorem: Armstrong's axioms are sound and complete; given a header and a set of FDs that only contain subsets of , if and only if holds in all relation universes over in which all FDs in hold.
- Completion
- The completion of a finite set of attributes under a finite set of FDs , written as , is the smallest superset of such that:
- The completion of an attribute set can be used to compute if a certain dependency is in the closure of a set of FDs.
- Theorem: Given a set of FDs, if and only if .
- Irreducible cover
- An irreducible cover of a set of FDs is a set of FDs such that:
- there exists no such that
- is a singleton set and
- .




![t_1[X] = t_2[X]~\Rightarrow~t_1[Y] = t_2[Y]](../I/a565b9a0bf40d42340cc26ae0053f1e5a2ac8a55.svg)

















Algorithm to derive candidate keys from functional dependencies
algorithm derive candidate keys from functional dependencies is
input: a set S of FDs that contain only subsets of a header H
output: the set C of superkeys that hold as candidate keys in
all relation universes over H in which all FDs in S hold
C := ∅ // found candidate keys
Q := { H } // superkeys that contain candidate keys
while Q <> ∅ do
let K be some element from Q
Q := Q – { K }
minimal := true
for each X->Y in S do
K' := (K – Y) ∪ X // derive new superkey
if K' ⊂ K then
minimal := false
Q := Q ∪ { K' }
end if
end for
if minimal and there is not a subset of K in C then
remove all supersets of K from C
C := C ∪ { K }
end if
end while
Alternatives
Other models include the hierarchical model and network model. Some systems using these older architectures are still in use today in data centers with high data volume needs, or where existing systems are so complex and abstract that it would be cost-prohibitive to migrate to systems employing the relational model. Also of note are newer object-oriented databases.[7] and Datalog.[8]
Datalog is a database definition language, which combines a relational view of data, as in the relational model, with a logical view, as in logic programming. Whereas relational databases use a relational calculus or relational algebra, with relational operations, such as union, intersection, set difference and cartesian product to specify queries, Datalog uses logical connectives, such as if, or, and and not to define relations as part of the database itself.
In contrast with the relational model, which cannot expressive recursive queries without introducing a least-fixed-point operator,[9] recursive relations can be defined in Datalog, without introducing any new logical connectives or operators.
See also
Notes
References
- ↑ Codd, E.F (1969), Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks, Research Report, IBM.
- ↑ Codd, E.F (1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM. Classics. 13 (6): 377–87. doi:10.1145/362384.362685. S2CID 207549016. Archived from the original on 2007-06-12.
- ↑ Codd, E. F (1990), The Relational Model for Database Management, Addison-Wesley, pp. 371–388, ISBN 978-0-201-14192-4.
- ↑ Date, Christopher J. (2006). "18. Why Three- and Four-Valued Logic Don't Work". Date on Database: Writings 2000–2006. Apress. pp. 329–41. ISBN 978-1-59059-746-0.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 Date, Chris J. (2013). Relational Theory for Computer Professionals: What Relational Databases are Really All About (1. ed.). Sebastopol, Calif: O'Reilly Media. ISBN 978-1-449-36943-9.
- ↑ David M. Kroenke, Database Processing: Fundamentals, Design, and Implementation (1997), Prentice-Hall, Inc., pages 130–144
- ↑ Atkinson, M., Dewitt, D., Maier, D., Bancilhon, F., Dittrich, K. and Zdonik, S., 1990. The object-oriented database system manifesto. In Deductive and object-oriented databases (pp. 223-240). North-Holland.
- ↑ Maier, D., Tekle, K.T., Kifer, M. and Warren, D.S., 2018. Datalog: concepts, history, and outlook. In Declarative Logic Programming: Theory, Systems, and Applications (pp. 3-100).
- ↑ Aho, A.V. and Ullman, J.D., 1979, January. Universality of data retrieval languages. In Proceedings of the 6th ACM SIGACT-SIGPLAN symposium on Principles of programming languages (pp. 110-119).
Further reading
- Date, Christopher J.; Darwen, Hugh (2000). Foundation for future database systems: the third manifesto; a detailed study of the impact of type theory on the relational model of data, including a comprehensive model of type inheritance (2 ed.). Reading, MA: Addison-Wesley. ISBN 978-0-201-70928-5.
- ——— (2007). An Introduction to Database Systems (8 ed.). Boston: Pearson Education. ISBN 978-0-321-19784-9.
External links
- Childs (1968), Feasibility of a set-theoretic data structure: a general structure based on a reconstituted definition of relation (research), Handle, hdl:2027.42/4164 cited in Codd's 1970 paper.
- Darwen, Hugh, The Third Manifesto (TTM).
- Relational Databases at Curlie
- "Relational Model", C2.
- Binary relations and tuples compared with respect to the semantic web (World Wide Web log), Sun.
| Types | |
|---|---|
| Concepts | |
| Objects | |
| Components | |
| Functions | |
| Related topics | |
| |