Release consistency is one of the synchronization-based consistency models used in concurrent programming (e.g. in distributed shared memory, distributed transactions etc.).
Introduction
In modern parallel computing systems, memory consistency must be maintained to avoid undesirable outcomes. Strict consistency models like sequential consistency are intuitively composed but can be quite restrictive in terms of performance as they would disable instruction level parallelism which is widely applied in sequential programming. To achieve better performance, some relaxed models are explored and release consistency is an aggressive relaxing attempt.[1]
Release consistency vs. sequential consistency
Hardware structure and program-level effort
Sequential consistency can be achieved simply by hardware implementation, while release consistency is also based on an observation that most of the parallel programs are properly synchronized. In programming level, synchronization is applied to clearly schedule a certain memory access in one thread to occur after another. When a synchronized variable is accessed, hardware would make sure that all writes local to a processor have been propagated to all other processors and all writes from other processors are seen and gathered. In release consistency model, the action of entering and leaving a critical section are classified as acquire and release and for either case, explicit code should be put in the program showing when to do these operations.
Conditions for sequential consistent result
In general, a distributed shared memory is release consistent if it obeys the following rules:[2]
1. Before an access to a shared variable is performed, all previous acquires by this processor must have completed.
2. Before a release is performed, all previous reads and writes by this process must have completed.
3. The acquire and release accesses must be processor consistent.
If the conditions above are met and the program is properly synchronized (i.e., processors implement acquire and release properly), the results of any execution will be exactly the same as they would have been executed following sequential consistency. In effect, accesses to shared variables are separated into atomic operation blocks by the acquire and release primitives so that races and interleaving between blocks will be prevented.
Implementations
Lock release

A lock release can be considered as a type of release synchronization. Assume a loop operation is performed using the code shown to the right. Two threads intend to enter a critical section and read the most recent value of a, then exit the critical section. The code shows that thread 0 first acquires the lock and enters the critical section. In order to execute correctly, P1 must read the latest value of a written by P0. In that case, only one thread can be in the critical section at a time. Therefore, the synchronization itself has ensured that the successful lock acquisition at P1 occurs after lock release by P0. Besides, the S2 -> S3 ordering has to be ensured, since the P0 must propagate the new value of a to P1. For the same reason, S5 must occur after S4.[3]
Correctness is not affected if memory accesses following the unlock issue before the unlock complete or memory accesses prior to a lock issue after the lock acquisition. However, the code in critical section can not be issued prior to the lock acquisition is complete because mutual exclusion may not be guaranteed.
Post-wait

Post-wait synchronization is another implementation form of release consistency. As shown in the code to the right, correctness can be ensured if post operations occur only after all memory access are complete, especially the store to ‘a’. Apart from that, read operation should not be executed until the wait operation has completed. S2 acts as a release synchronization and S3 acts as an acquire synchronization. Therefore, S2 needs to prevent previous execution from occurring after it, and S3 needs to prevent any later execution from occurring before it. S2 does not need to prevent later execution from occurring before it, Likewise, S3 does not need to prevent any previous execution from occurring after it.
Lazy release consistency
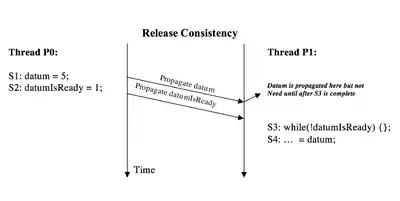
Lazy release consistency is a further optimization of release consistency. It assumes that the thread executing an acquire access does not need the values written by other threads until the acquire access has completed. Hence, all behavior of coherence can be delayed and timing for write propagation can be tweaked.[4]
Example
Consider the scenarios described in the image to the right. This case shows when write propagation is performed on a cache-coherent system based on the release consistency model. The variable datum is completely propagated before the propagation of datumIsReady. But the value of datum is not needed until after the acquire synchronization access in P1 and it can be propagated along with datumIsReady without harming the result of the program.

The second image displays what is the case when lazy release consistency is applied. Considering this scenario, all values written ahead of the release synchronization are delayed and propagated together with the propagation of the release access itself. Hence, datum and datumIsReady are propagated together at the release point.
"TreadMarks"[5] is an actual application of lazy release consistency.
Performance improvement over release consistency
Lazy release consistency can outperform release consistency in certain cases. If there is a system with little bandwidth between processors or it suffers badly from the higher overheads because of frequent propagation of small block of data versus infrequent large data block propagation, LRC can really help the performance.
Consider a system employs a software level shared memory abstraction rather than an actual hardware implementation. In this system, write propagation is executed at a page granularity, which makes it extremely expensive to propagate a whole page when only one block in this page is modified. Therefore, write propagation is delayed until a release synchronization point is reached and the entire page will be modified at this time and the whole page will be propagated.
Drawback
LRC requires performing write propagation in bulk at the release point of synchronization. Propagating such a large number of writes altogether will slow down the release access and the subsequent acquire access. Hence it can hardly improve the performance of a hardware cache coherence system.
Release consistency vs. other relaxed consistency models
Weak ordering (Weak consistency)
Release consistency requires more from the programmers compared to weak ordering. They must label synchronization accesses as acquires or releases, not just as synchronization accesses. Similar to weak ordering, Release consistency allows the compiler to freely reorder loads and stores except that they cannot migrate upward past an acquire synchronization and cannot migrate downward past a release synchronization. However, the flexibility and performance advantage of Release consistency comes at the expense of requiring synchronization accesses to be properly identified and identified as acquires and releases. Unlike in weak ordering, synchronization accesses cannot be easily identified by instruction opcodes alone. Hence, the burden is on programmers’ shoulders to properly identify acquire and release synchronization accesses.[3][6]
Processor consistency
For processor consistency, all processes see writes from each processor in the order they were initiated. Writes from different processors may not be seen in the same order, except that writes to the same location will be seen in the same order everywhere. Compared to processor consistency, release consistency is more relaxed because it does not enforce the ordering between stores that happens in processor consistency. It doesn't follow programmers' intuition as it is relatively less restrictive to compiler optimizations.
See also
References
- ↑ Memory Consistency and Event Ordering in Scalable Shared-Memory Multiprocessors by Kourosh Gharachorloo, Daniel Lenoski, James Laudon, Phillip Gibbons, Anoop Gupta, and John Hennessy published in ISCA '90 Proceedings of the 17th annual international symposium on Computer Architecture
- ↑ Tanenbaum, Andrew (1995). Distributed Operating Systems. Pearson Education. pp. 327–330. ISBN 9788177581799.
- 1 2 Solihin, Yan (2015). Fundamentals of Parallel Multicore Architecture. Chapman & Hall/CRC Computational Science. pp. 315–320. ISBN 9781482211184.
- ↑ Lazy release consistency for software distributed shared memory by Pete Keleher, Alan L. Cox, and Willy Zwaenepoel published in Proceeding ISCA '92 Proceedings of the 19th annual international symposium on Computer architecture
- ↑ TreadMarks: distributed shared memory on standard workstations and operating systems by Pete Keleher, Alan L. Cox, Sandhya Dwarkadas and Willy Zwaenepoel published in WTEC'94 Proceedings of the USENIX Winter 1994 Technical Conference on USENIX Winter 1994 Technical Conference
- ↑ Culler, David; Gupta, Anoop; Singh, Jaswinder (1997). Parallel Computer Architecture: A Hardware/Software Approach. Morgan Kaufmann Publishers Inc. pp. 620–626. ISBN 1558603433.