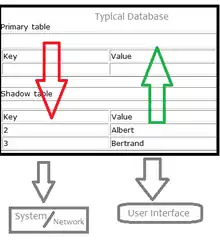
Shadow tables are objects in computer science used to improve the way machines, networks and programs handle information.[1] More specifically, a shadow table is an object that is read and written by a processor and contains data similar to (in the same format as) its primary table, which is the table it's "shadowing". Shadow tables usually contain data that is relevant to the operation and maintenance of its primary table, but not within the subset of data required for the primary table to exist.[2] Shadow tables are related to the data type "trails" in data storage systems. Trails are very similar to shadow tables but instead of storing identically formatted information that is different (like shadow tables), they store a history of modifications and functions operated on a table.[3]
History
Shadow tables, as an abstract concept, have been used since the beginning of modern computing. However, widespread usage of the specific phrase "shadow table" began when relational database management systems (RDBMS) became widely used in the 1970s.[4]
The initial usage of relational DBMs for commercial purposes lead to the term "shadow tables" becoming widespread. A relational DBM uses related data fields (columns) to correlate information between tables.[5] For example, two tables, transaction_user and transaction_amount, would both contain the column "key", and keys between tables would match, making it easy to find both the user and the amount of a specific transaction if the key is known. This relational technology allowed people to correlate information stored in a primary table and its shadow.
Applications
Since shadow tables are such an abstract concept, their applications remain in the realm of computer science. Although their usage may not be specifically declared as "shadow table(s)", the concept remains the same. Shadow tables are usually used in order to improve the performance, capacity, and ability of an existing computer/network system. In most applications, shadow tables are usually a carbon copy of their primary tables' structure, but with unique data.
Theoretical application
Since shadow tables are a specific type of object in computer science, the applications vary greatly, because their application depends on what data is stored in the shadow table and how that data is used. The following is a list of general, abstract applications for shadow tables that span all real-world applications.
- Storage - The storage of a data entry in a shadow table that would have normally been deleted or modified.
- Encapsulation - The placement of data within a shadow table in order to separate a set of data from another.
- Modularity - The placement of data within a shadow table to make modification and handling of the data easier.
Engineering Applications
When shadow tables are used to solve current problems in today's computer/network systems, usually a combination of more than one of the aforementioned theoretical/abstract applications of shadow tables are used. The following list is a very tiny subset of all real-world applications of shadow tables and is only shown to give an example of common applications of shadow tables.
Database management systems
Database management systems (DBMS) are software that handle the maintenance, security, and manipulation of data tables. Well known and widely used examples of DBMS' are SQL Server, MySQL, Oracle and PostgreSQL. Each of these DBMS' create a virtual "environment" in which tables of data are held and can be read and written to via a specific type of programming language known as a query language. Query languages specialize in the simple modification or retrieval of large and specific amounts of data. Most modern DBMS' specifically support SQL (a specific type of query language). Using SQL, one can easily create tables that share the same structure as already existing tables. SQL can also get data written to these new tables, creating a shadow table. Shadow tables are often used with DBMS' to improve efficiency by preventing redundant operations being performed by the DBM. Shadow tables are also easy to implement in most modern DBMS' because they do not affect the original data, so the way the databases and applications accessing them work together is not affected, unless desired.[6]
For example, shadow tables could be used in an efficient backup system that supports large data tables that rarely change.
- Without shadow tables, one could create a program that simply saves a version of that table every day.
After 50 days, with this backup system, there would be 50 copies of the same table, - With shadow tables, one could create an empty "shadow table" of that table and use a program that inserts a copy of a row into the shadow table every time that row gets deleted from the primary table.
After 50 days using the shadow table system in the worst-case scenario, there would be one copy of the primary table, assuming every row in the primary table got deleted.[5][7]
Interfacing
Interfacing is the process of using "layers" to simplify the communications between technologies and between people and technologies. One example of layered interfacing is the buttons and menus used by home computer operating systems. These graphical objects exist as a link to the underlying "buttons" of the operating system. The command console is one level below these graphical objects as it gives you an even closer link to the underlying functions of the operating system.
Shadow tables are often used as layers between the end-user and the database. For example, if a user logs into his/her bank account and requests a history of all his/her past transactions, the database usually stores all transactions for all users in one huge table and distinguishes the parties involved in each transaction in one specific column of that table. At this point the server has two options:
- The database can send the whole transactions table.
- The database can send a shadow table that only contains the transactions involving the user that requested his/her transaction history.
The second option is usually more favorable because it saves bandwidth and processing power on the user's end. It also keeps others' transaction data secure.
Operating system virtualization
Operating system virtualization is the process of simulating the operation of a computer within another computer. This technique is useful for someone who wants to run more than one type of operating system on his/her PC concurrently. Shadow page tables are often used in simulating more than one operating system on a single set of memory and processor. A page table is used by an operating system to map the virtual memory, the actual memory used by programs and the operating system to store information, to its location on the physical memory, the hardware-specific memory stored in bytes on the RAM (Random Access Memory).[8] A shadow page table is a pseudo-page table within a computer's main page table which allows a system to run more than one kind of operating system concurrently.[9]
References
- ↑ "Shadow Databases". Supporting Advancements. Retrieved 26 October 2011.
- ↑ Ambler, Scott. "Shadow Information and Scaffolding". Mapping Objects to Relational Databases: O/R Mapping In Detail. Agile Data. Retrieved 28 October 2011.
- ↑ Wehlou, Martin. "Shadows and Trails". Wehlou. Retrieved 26 October 2011.
- ↑ Brown, Pete. "Mountain Man". A Brief History of Modern RDBMS IT Management. Retrieved 30 October 2011.
- 1 2 Codd, Edgar (June 1970). "A Relational Model of Data for Large Shared Data Banks" (PDF). Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685. Retrieved 28 October 2011.
- ↑ Speaker, Devin Spackman, Mark (2005). Enterprise integration solutions. Redmond, Wash.: Microsoft Press. p. 45. ISBN 978-0-7356-2060-5.
{{cite book}}: CS1 maint: multiple names: authors list (link) - ↑ Kent, Jack, and Hector Garcia-Molina. 1988. p. 13.
- ↑ Denning, P.J. "Page Tables". Retrieved 30 October 2011.
- ↑ "Virtualization: Architectural Considerations And Other Evaluation Criteria" (PDF). Retrieved 30 October 2011.