The swish function is a mathematical function defined as follows:
- [1]
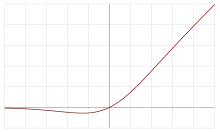 The swish function
The swish function

where β is either constant or a trainable parameter depending on the model. For β = 1, the function becomes equivalent to the Sigmoid Linear Unit[2] or SiLU, first proposed alongside the GELU in 2016. The SiLU was later rediscovered in 2017 as the Sigmoid-weighted Linear Unit (SiL) function used in reinforcement learning.[3][1] The SiLU/SiL was then rediscovered as the swish over a year after its initial discovery, originally proposed without the learnable parameter β, so that β implicitly equalled 1. The swish paper was then updated to propose the activation with the learnable parameter β, though researchers usually let β = 1 and do not use the learnable parameter β. For β = 0, the function turns into the scaled linear function f(x) = x/2.[1] With β → ∞, the sigmoid component approaches a 0-1 function pointwise, so swish approaches the ReLU function pointwise. Thus, it can be viewed as a smoothing function which nonlinearly interpolates between a linear function and the ReLU function.[1] This function uses non-monotonicity, and may have influenced the proposal of other activation functions with this property such as Mish.[4]
When considering positive values, Swish is a particular case of sigmoid shrinkage function defined in [5] (see the doubly parameterized sigmoid shrinkage form given by Equation (3) of this reference).
Applications
In 2017, after performing analysis on ImageNet data, researchers from Google indicated that using this function as an activation function in artificial neural networks improves the performance, compared to ReLU and sigmoid functions.[1] It is believed that one reason for the improvement is that the swish function helps alleviate the vanishing gradient problem during backpropagation.[6]
References
- 1 2 3 4 5 Ramachandran, Prajit; Zoph, Barret; Le, Quoc V. (2017-10-27). "Searching for Activation Functions". arXiv:1710.05941v2 [cs.NE].
- ↑ Hendrycks, Dan; Gimpel, Kevin (2016). "Gaussian Error Linear Units (GELUs)". arXiv:1606.08415 [cs.LG].
- ↑ Elfwing, Stefan; Uchibe, Eiji; Doya, Kenji (2017-11-02). "Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning". arXiv:1702.03118v3 [cs.LG].
- ↑ Misra, Diganta (2019). "Mish: A Self Regularized Non-Monotonic Neural Activation Function". arXiv:1908.08681 [cs.LG].
- ↑ Atto, Abdourrahmane M.; Pastor, Dominique; Mercier, Gregoire (March 2008). "Smooth sigmoid wavelet shrinkage for non-parametric estimation". 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (PDF). pp. 3265–3268. doi:10.1109/ICASSP.2008.4518347. ISBN 978-1-4244-1483-3. S2CID 9959057.
- ↑ Serengil, Sefik Ilkin (2018-08-21). "Swish as Neural Networks Activation Function". Machine Learning, Math. Archived from the original on 2020-06-18. Retrieved 2020-06-18.