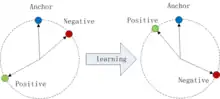
Triplet loss is a loss function for machine learning algorithms where a reference input (called anchor) is compared to a matching input (called positive) and a non-matching input (called negative). The distance from the anchor to the positive is minimized, and the distance from the anchor to the negative input is maximized.[1][2] An early formulation equivalent to triplet loss was introduced (without the idea of using anchors) for metric learning from relative comparisons by M. Schultze and T. Joachims in 2003.[3]
By enforcing the order of distances, triplet loss models embed in the way that a pair of samples with same labels are smaller in distance than those with different labels. Unlike t-SNE which preserves embedding orders via probability distributions, triplet loss works directly on embedded distances. Therefore, in its common implementation, it needs soft margin treatment with a slack variable in its hinge loss-style formulation. It is often used for learning similarity for the purpose of learning embeddings, such as learning to rank, word embeddings, thought vectors, and metric learning.[4]

Consider the task of training a neural network to recognize faces (e.g. for admission to a high security zone). A classifier trained to classify an instance would have to be retrained every time a new person is added to the face database. This can be avoided by posing the problem as a similarity learning problem instead of a classification problem. Here the network is trained (using a contrastive loss) to output a distance which is small if the image belongs to a known person and large if the image belongs to an unknown person. However, if we want to output the closest images to a given image, we want to learn a ranking and not just a similarity. A triplet loss is used in this case.
The loss function can be described by means of the Euclidean distance function
- where is an anchor input, is a positive input of the same class as , is a negative input of a different class from , is a margin between positive and negative pairs, and is an embedding.





This can then be used in a cost function, that is the sum of all losses, which can then be used for minimization of the posed optimization problem

The indices are for individual input vectors given as a triplet. The triplet is formed by drawing an anchor input, a positive input that describes the same entity as the anchor entity, and a negative input that does not describe the same entity as the anchor entity. These inputs are then run through the network, and the outputs are used in the loss function.
Comparison and Extensions
In computer vision tasks such as re-identification, a prevailing belief has been that the triplet loss is inferior to using surrogate losses (i.e., typical classification losses) followed by separate metric learning steps. Recent work showed that for models trained from scratch, as well as pretrained models, a special version of triplet loss doing end-to-end deep metric learning outperforms most other published methods as of 2017.[5]
Additionally, triplet loss has been extended to simultaneously maintain a series of distance orders by optimizing a continuous relevance degree with a chain (i.e., ladder) of distance inequalities. This leads to the Ladder Loss, which has been demonstrated to offer performance enhancements of visual-semantic embedding in learning to rank tasks.[6]
In Natural Language Processing, triplet loss is one of the loss functions considered for BERT fine-tuning in the SBERT architecture.[7]
Other extensions involve specifying multiple negatives (multiple negatives ranking loss).
See also
References
- ↑ Chechik, G.; Sharma, V.; Shalit, U.; Bengio, S. (2010). "Large Scale Online Learning of Image Similarity Through Ranking" (PDF). Journal of Machine Learning Research. 11: 1109–1135.
- ↑ Schroff, F.; Kalenichenko, D.; Philbin, J. (June 2015). "FaceNet: A unified embedding for face recognition and clustering". 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 815–823. arXiv:1503.03832. doi:10.1109/CVPR.2015.7298682. ISBN 978-1-4673-6964-0. S2CID 206592766.
- ↑ Schultz, M.; Joachims, T. (2004). "Learning a distance metric from relative comparisons" (PDF). Advances in Neural Information Processing Systems. 16: 41–48.
- ↑ Ailon, Nir; Hoffer, Elad (2014-12-20). "Deep metric learning using Triplet network". arXiv:1412.6622. Bibcode:2014arXiv1412.6622H.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Hermans, Alexander; Beyer, Lucas; Leibe, Bastian (2017-03-22). "In Defense of the Triplet Loss for Person Re-Identification". arXiv:1703.07737 [cs.CV].
- ↑ Zhou, Mo; Niu, Zhenxing; Wang, Le; Gao, Zhanning; Zhang, Qilin; Hua, Gang (2020-04-03). "Ladder Loss for Coherent Visual-Semantic Embedding" (PDF). Proceedings of the AAAI Conference on Artificial Intelligence. 34 (7): 13050–13057. doi:10.1609/aaai.v34i07.7006. ISSN 2374-3468. S2CID 208139521.
- ↑ Reimers, Nils; Gurevych, Iryna (2019-08-27). "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks". arXiv:1908.10084 [cs.CL].