协变与逆变
协变与逆变(Covariance and contravariance)是在计算机科学中,描述具有父/子型别关系的多个型别通过型别构造器、构造出的多个复杂型别之间是否有父/子型别关系的用语。
概述
許多程式設計語言的型別系統支持子型別。例如,如果Cat是Animal的子型別,那麼Cat型別的表達式可用於任何出現Animal型別表達式的地方。所謂的變型(variance)是指如何根據組成型別之間的子型別關係,來確定更複雜的型別之間(例如Cat列表之於Animal列表,回傳Cat的函數之於回傳Animal的函數...等等)的子型別關係。當我們用型別構造出更複雜的型別,原本型別的子型別性質可能被保持、反轉、或忽略───取決於型別構造器的變型性質。例如在C#中:
IEnumerable<Cat>是IEnumerable<Animal>的子型別,因為型別構造器IEnumerable<T>是協變的(covariant)。注意到複雜型別IEnumerable的子型別關係和其介面中的參數型別是一致的,亦即,參數型別之間的子型別關係被保持住了。
Action<Animal>是Action<Cat>的子型別,因為型別構造器Action<T>是逆變的(contravariant)。(在此,Action<T>被用來表示一個參數型別為T或sub-T的一級函數)。注意到T的子型別關係在複雜型別Action的封裝下是反轉的,但是當它被視為函數的參數時其子型別關係是被保持的。
IList<Cat>或IList<Animal>彼此之間沒有子型別關係。因為IList<T>型別構造器是不變的(invariant),所以參數型別之間的子型別關係被忽略了。
程式語言的設計者在制定陣列、繼承、泛型數據類別等的型別規則時,必須將“變型”列入考量。將型別構造器設計成是協變、逆變而非不變的,可以讓更多的程式俱備良好的型別。另一方面,程式員經常覺得逆變是不直觀的;如果為了避免執行時期錯誤而精確追蹤變型,可能導致複雜的型別規則。為了保持型別系統簡單同時允許有用的編程,一個程式語言可能把型別構造器視為不變的,即使它被視為可變也是安全的;或是把型別構造器視為協變的,即使這樣可能會違反型別安全。
形式定义
在一門程式設計語言的型別系統中,一個型別規則或者型別構造器是:
- 協變(covariant),如果它保持了子型別序關係≦。該序關係是:子型別≦基型別。
- 逆變(contravariant),如果它逆轉了子型別序關係。
- 不变(invariant),如果上述两种均不适用。
下文中將敘述這些概念如何適用於常見的型別構造器。
数组
首先考虑数组类型构造器: 从Animal类型,可以得到Animal[](“animal数组”)。 是否可以把它当作
- 协变:一个
Cat[]也是一个Animal[] - 逆变:一个
Animal[]也是一个Cat[] - 以上二者均不是則為不变
如果要避免类型错误,且数组支持对其元素的读、写操作,那么只有第3个选择是安全的。Animal[]并不是总能当作Cat[],因为当一个客户读取数组并期望得到一个Cat,但Animal[]中包含的可能是个Dog。所以逆变规则是不安全的。
反之,一個Cat[]也不能被當作一個Animal[]。因為總是可以把一個Dog放到Animal[]中。在協變陣列,這就不能保證是安全的,因為背後的存儲可以實際是Cat[]。因此協變規則也不是安全的—陣列構造器應該是不變。注意,這僅是可寫(mutable)陣列的問題;對於不可寫(只讀)陣列,協變規則是安全的。
這示例了一般現像。只讀數據型別(源)是協變的;只寫數據型別(彙/sink)是逆變的。可讀可寫型別應是“不變”的。
Java与C#中的协变数组
早期版本的Java與C#不包含泛型(generics,即參數化多態)。在這樣的設置下,使陣列為“不變”將導致許多有用的多態程式被排除。
例如,考慮一個用於重排(shuffle)陣列的函數,或者測試兩個陣列相等的函數,使用Object與equals方法. 函數的實現並不依賴於陣列元素的確切型別,因此可以寫一個單獨的實現而適用於所有的陣列:
boolean equalArrays (Object[] a1, Object[] a2);
void shuffleArray(Object[] a);
然而,如果陣列型別被處理為“不變”,那麼它僅能用於確切為Object[]型別的陣列。對於字符串陣列等就不能做重排操作了。
所以,Java與C#把陣列型別處理為協變。在C#中,string[]是object[]的子型別,在Java中,String[]是Object[]的子型別。
如前文所述,協變陣列在寫入陣列的操作時會出問題。Java與C#為此把每個陣列对象在創建時附標一個型別。 每當向陣列存入一個值,編譯器插入一段代碼來檢查該值的運行時型別是否等於陣列的運行時型別。如果不匹配,會拋出一個ArrayStoreException(在C#中是ArrayTypeMismatchException):
// a 是单元素的 String 数组
String[] a = new String[1];
// b 是 Object 的数组
Object[] b = a;
// 向 b 中赋一个整数。如果 b 确实是 Object 的数组,这是可能的;然而它其实是个 String 的数组,因此会发生 java.lang.ArrayStoreException
b[0] = 1;
在上例中,可以从b中安全地读。仅在写入数组时可能会遇到麻烦。
這個方法的缺點是留下了運行時錯誤的可能,而一個更嚴格的型別系統本可以在編譯時識別出該錯誤。這個方法還有損性能,因為在運行時要執行額外的型別檢查。
Java與C#有了泛型後,有了型別安全的編寫這種多態函數。陣列比較與重排可以給定參數型別
<T> boolean equalArrays (T[] a1, T[] a2);
<T> void shuffleArray(T[] a);
也可以強制C#方法只讀方式訪問一個集合,可以用界面IEnumerable<object>代替作為陣列object[]。
函数类型
支持一等函数的语言具有函数类型,比如“一个函数期望输入一只 Cat 并返回一只 Animal(写为 OCaml 的 Cat -> Animal 或 C# 的Func<Cat,Animal>)。
這些語言需要指明什麼時候一個函數型別是另一個函數型別的子型別—也就是說,在一個期望某個函數型別的上下文中,什麼時候可以安全地使用另一個函數型別。
可以说,函数f可以安全替换函数g,如果与函数g相比,函数f接受更一般的参数类型,返回更特化的结果类型。
例如,函數型別Cat->Cat可安全用於期望Cat->Animal的地方;類似地,函數型別Animal->Animal可用於期望Cat->Animal的地方——典型地,在 Animal a=Fn(Cat(...)) 这种语境下进行调用,由于 Cat 是 Animal 的子类所以即使 Fn 接受一只 Animal 也同样是安全的。一般規則是:
S1 → S2 ≦ T1 → T2 當T1 ≦ S1且S2 ≦ T2.
换句话说,类型构造符→对输入类型是逆变的而对输出类型是协变的。这一规则首先被Luca Cardelli正式提出。[1]
在處理高階函數時,這一規則可以應用多次。例如,可以應用這一規則兩次,得到(A'→B)→B ≦ (A→B)→B 當 A'≦A。即,型別(A→B)→B在A位置是協變的。在跟蹤判斷為何某一型別特化不是型別安全的可能令人困擾,但是比較容易計算哪個位置是協變或逆變:一個位置是協變當且僅當在偶數個箭頭的左邊。
例如,在Visual Basic中,允许把lambda表达式(匿名函数)赋值给委托(delegate)类型的实例,如果参数是widen,返回值是narrowen:
' 定义委托 Del1
Delegate Function Del1(ByVal arg As Integer) As Integer
' 合法的 lambda 表达式赋值,不论 Option Strict 是开是关:
' 整数匹配于整数
Dim d1 As Del1 = Function(m As Integer) As Integer
' 整数扩展到长整数
Dim d2 As Del1 = Function(m As Long) As Integer
' 整数扩展到双精度浮点
Dim d3 As Del1 = Function(m As Double) As Integer
' 合法的返回值赋值(Option Strict 打开):
' 整数匹配于整数
Dim d6 As Del1 = Function(m As Integer) As Integer
' 短整数扩展到整数
Dim d7 As Del1 = Function(m As Long) As Short
' 字节扩展到整数
Dim d8 As Del1 = Function(m As Double) As Byte
面向对象语言中的继承
当一个子类重写一个超类的方法时,编译器必须检查重写方法是否具有正确的类型。虽然一些语言要求类型必须与超类相同,但允许重写方法有一个“更好的”类型也是类型安全的。对于大部分的方法子类化规则来说,这要求返回值的类型必须更具体,也就是协变,而且接受更宽泛的参数类型,也就是逆变。
对于一下示例,假设Cat 是 Animal 的子类,而且我们以及拥有了这两个类(使用Java语法)
class AnimalShelter {
Animal getAnimalForAdoption() {
...
}
void putAnimal(Animal animal) {
...
}
}
问题是:如果我们子类化 AnimalShelter, 我们可以让getAnimalForAdoption 和 putAnimal具有什么类型?
返回值的协变
在允许协变返回值的语言中, 子类可以重写 getAnimalForAdoption 方法来返回一个更窄的类型:
class CatShelter extends AnimalShelter {
Cat getAnimalForAdoption() {
return new Cat();
}
}
主流的面向对象语言中, Java和C++允许返回值协变,C#不支持。添加返回值协变是1998年C++标准委员会最先允许的对C++语言核心的修改之一。[2] Scala和D语言也支持返回值协变。
方法参数的逆变
类似地,子类重写的方法接受更宽的类型也是类型安全(type safe)的:
class CatShelter extends AnimalShelter {
void putAnimal(Object animal) {
...
}
}
允许参数逆变的面向对象语言并不多——C++和Java会把它当成一个函数重载。
然而,Sather既支持协变,也支持逆变。对于重写的方法,出参数和返回值是协变的,而常规的参数是逆变的。
协变的方法参数类型
在主流的语言中,Eiffel 允许一个重写的方法参数比起父类中的那一个有更加具体的类型,即参数类型协变。因此,Eiffel 版本的 putAnimal 会如下所示:
class CatShelter extends AnimalShelter {
void putAnimal(Cat animal) {
...
}
}
这并不是类型安全的。通过把 CatShelter 转换为 AnimalShelter,程序员可以把“狗”放进猫庇护所里。这种类型安全性的缺失(在 Eiffel 社区里称为“猫调用问题”)由来已久。许多年以来,人们组合使用各种全局 / 局部静态分析以及新的语言特性来进行补救[3]
[4],有些已被写进了一些 Eiffel 编译器。
抛开类型安全问题不谈,Eiffel 的设计者认为在对现实世界建模这一点上,协变的参数类型是不可或缺的[4]。猫庇护所问题演示了一种常见现象:它是一种动物庇护所,但有着额外的限制;而用继承和受限参数类型又似无不可。通过提出继承的这种应用方式,Eiffel 设计者们拒绝了 Liskov 代换原則(即子类对象受的限制一定比它们父类对象少)。
另一个参数类型协变可能有益的例子是所谓二元方法,即其参数与方法所在对象的类型相同。例如 compareTo 方法:a.compareTo(b) 检查 a 和 b 在某种排序下的先后关系,但比较不同类型对象——比如,比较两个有理数以及比较两个字符串——的方式可以大相径庭。其它的常见二元方法例子还有相等性比较、算术运算、以及诸如求交集 / 并集的集合运算。
在旧一点的 Java 版本中,比较方法是以接口 Comparable 的方式指定的:
interface Comparable {
int compareTo(Object o);
}
这种方式的缺点是方法参数类型指定为 Object。一个典型的实现可能是先把这个参数向下强制转换——如果不是期望的类型,那么报错:
class RationalNumber implements Comparable {
int numerator;
int denominator;
...
public int compareTo(Object other) {
RationalNumber otherNum = (RationalNumber)other;
return Integer.compare(numerator*otherNum.denominator,
otherNum.numerator*denominator);
}
}
在有参数协变的语言中,compareTo 的参数可以直接定为希望的类型(RationalNumber),从而把类型转换消除掉。(当然,该报运行时错误的时候还是会报错的,比如对一个 String 调用 compareTo)。
去除对参数类型协变的依赖
其它语言特性可能用来弥补缺乏参数类型协变的缺乏。
在有泛型(即参数化多态及受限量词)的语言中,前面的例子可用更类型安全的方式重写[5]
:不定义 AnimalShelter,改为定义一个参数化的类 Shelter<T>。(这种方法的缺点之一是基类实现者需要预料到哪些类型要在子类中特化)
class Shelter<T extends Animal> {
T getAnimalForAdoption() {
...
}
void putAnimal(T animal) {
...
}
}
class CatShelter extends Shelter<Cat> {
Cat getAnimalForAdoption() {
...
}
void putAnimal(Cat animal) {
...
}
}
相似地,在新版本的 Java 中 Comparable 接口也被参数化了,从而允许以一种类型安全的方式省去向下类型转换:
class RationalNumber implements Comparable<RationalNumber> {
int numerator;
int denominator;
...
public int compareTo(RationalNumber otherNum) {
return Integer.compare(numerator*otherNum.denominator,
otherNum.numerator*denominator);
}
}
另一个有助的语言特性是多分派。二元方法难写的一个原因就是在类似于 a.compareTo(b) 的调用中,对 compareTo 的正确选择其实依赖于 a 和 b 两者的类型,但在经典的面向对象语言中只有 a 的类型被纳入考虑。在有CLOS 样式多分派特性的语言中,比较方法可以写成一个泛型方法,其两个参数类型都在方法选择中被考虑。
Giuseppe Castagna[6] 观察到在一个有类型而且有多分派的语言中,泛型函数的各个参数有些控制分派而余下那些则否。因为方法选择的规则是在可用方法中选择特化程度最高的,如果一个方法重写了另一个方法那么,它(前者)就会在那些控制性的参数上有更特化的类型。而另一方面,为了保证类型安全,语言又得要求剩下的参数越泛化越好。用上面的术语来说,运行时方法选择中使用的类型是协变的,而没用到的类型则是逆变的。常规的单分派语言,例如 Java,也遵循这种规则:只有在其上调用方法的对象(this)类型才用来选择方法,而在子类方法里的 this 的类型也确实要比在父类那里更特化。
Castagna 提议在需要参数类型协变的地方——尤其是二元方法——改用多分派,它本性就是协变的。然而不幸的是,大多数编程语言都不支持多分派。
泛型类型
在支持泛型(即参数化多态)的语言中,程序员可以用新的构造器扩展类型系统。例如,C# 的泛型接口 IList<T> 可以构造 IList<Animal> 和 IList<Cat> 这样的新类型。那么接下来的问题就是这些类型构造器应具有何种变型性质。
有两种主要的处理方式。在有着声明点变型标记法(如 C#)的语言中,程序员在泛型类型处标注其类型参数的预想变型方式;而在使用点变型标记法(如 Java)的语言中,程序员改在泛型类型实例化的位置标注。
声明点变型标记法
具有这种记法的最流行语言包括 C#(使用关键字 in 和 out)、Scala 以及 OCaml(这两者使用加号减号)。其中,C# 只允许在接口类型上标记变型,而 Scala 和 OCaml 既允许在接口类型上标记、也允许在具体的数据类型上标记变型。
接口
在 C# 中,每个泛型接口的类型参数都可被标注为协变(out)、逆变(in)或不变(不标注)。例如,可以定义一个接口 IEnumerator<T> 作为只读的迭代器,并声明它在其类型参数上具有协变性:
interface IEnumerator<out T>{
T Current{
get;
}
bool MoveNext();
}
通过这样声明,IEnumerator<T> 就会在其类型参数上具有协变性。例如,IEnumerator<Cat> 是 IEnumerator<Animal> 的子类型。
类型检查器保证接口里每个函数声明都通过符合 in/out 规则的方式使用其类型参数。也就是说,被声明为协变的参数不得出现在任何逆变的位置(一个位置称为逆变的,如果它经过了逆变类型构造器的奇数的应用)。精确的规则[7][8]是接口里所有函数的返回值类型都必须协变合法,而所有函数参数的类型都必须逆变合法。具体来说,协 / 逆变合法定义如下:
- 非泛型类型(类、结构、枚举等)既协变合法、也逆变合法。
- 类型参数 T 如果没有标 in,那么是协变合法;如果没有标 out,那么是逆变合法。
- 数组类型 A[] 是协 / 逆变合法,如果相对应地 A 是协 / 逆变合法。(C# 的数组是协变的)
- 泛型类型 G<A1, A2, ..., An> 是协 / 逆变合法,如果对于每个类型参数 Ai:
- Ai 是协 / 逆变合法,并且 G 中的第 i 个参数被声明为协变;或者
- Ai 是逆 / 协变合法(反转),并且 G 中的第 i 个参数被声明为逆变;或者
- Ai 既协变合法又逆变合法,并且 G 中的第 i 个参数被声明为不变。
举例而言,考虑下面的 IList<T> 接口:
interface IList<T>{
void Insert(int index, T item);
IEnumerator<T> GetEnumerator();
}
Insert 函数的参数类型 T 必须逆变合法,即 T 不得被标注为 out。相似地,由于 GetEnumerator 函数以一个协变的接口类型 IEnumerator<T> 为返回值类型,T 必须不是 in。这样一来,IList<T> 既不能是协变,也不能是逆变。
在诸如 IList<T> 这种泛型数据结构的通常情况下,上述的限制意味着 out 参数只能用在从对象中读出数据的函数上,而 in 参数只能用在写入数据的函数上。这也就是为何选择这两个单词作为关键字的原因。
数据
C# 允许在接口的类型参数上标注变型,但不能在类上应用。由于 C# 的成员变量永远是可变的,类型参数可变型的类在 C# 中并没有多大用途。不过强调不可变数据的语言就可以利用协变数据类型,例如在 Scala 和 OCaml 中不可变列表类型是协变的:List[Cat] 是 List[Animal] 的子类型。
Scala 的变型类型检查规则基本上跟 C# 相同。然而,有一些习惯用法会被套用到不可变数据结构上,如下从 List[A] 类中摘抄的代码所示:
sealed abstract class List[+A] extends AbstractSeq[A] {
def head: A
def tail: List[A]
/** 向列表头添加元素 */
def ::[B >: A] (x: B): List[B] =
new scala.collection.immutable.::(x, this)
...
}
首先,具有变型类型的类成员必须是不可变的。在这里,head 成员具有类型 A,其声明为协变(+),而且 head 成员确实被声明为函数(def)。试图将其声明为可变成员变量(var)将会得到一个类型错误。
其次,即使数据结构是不可变的,它也经常会有返回值类型逆变的函数。例如,考虑向列表头添加元素的函数 ::。(这个实现创建一个同名类 ::——即非空列表的类——的新对象。)这个函数最显然的类型莫过于
def :: (x: A): List[A]
然而这是个类型错误,因为协变的参数 A(作为函数参数而)出现在了逆变位置。不过也有绕过这个问题的方法:给 :: 一个更泛化的类型,使其能添加具有任何 A 的超类型 B 的元素。注意这依赖于 List 是协变的,因为 this 具有类型 List[A]、而我们要把它作为 List[B] 对待。乍看之下这个泛化的类型似乎不那么可靠,但如果程序员真拿那个简单的声明出来的话、类型错误会指出需要泛化的地方的。
变型的推断
设计一个让编译器能在所有类型参数上自动推断出尽量好的变型的类型系统是可能的[9]。然而,分析过程可能由于许多原因而变得复杂:其一,分析过程不是局部的,因为一个接口的变型性质取决于其所有使用到的接口;其二,为了得到最优解,类型系统必须允许双向变型——既是协变、同时也是逆变——的类型参数;其三,类型参数的变型性质应当是接口设计者深思熟虑的结果,而不是随机发生的事情。
因此[10],许多语言都几乎对变型不做干预。C# 和 Scala 完全不推断任何变型注;而 Ocaml 虽然可以推断具体数据类型的变型,程序员还是需要显式指定抽象类型(接口)的变型。
例如,考虑一个 OCaml 的数据类型 T,其包装了一个函数:
type ('a, 'b) t = T of ('a -> 'b)
编译器会推断出第一参数是逆变、第二参数是协变的。程序员也可以显式提供标注、让编译器检查是否满足,因此下面的声明等价于上面:
type (-'a, +'b) t = T of ('a -> 'b)
当定义接口时,OCaml 中的显式标注就有用了。例如,标准库给关联表的接口 Map.S 包括一个标注,指明类型构造器 map 的返回类型是协变的:
module type S =
sig
type key
type (+'a) t
val empty: 'a t
val mem: key -> 'a t -> bool
...
end
这保证了 IntMap.t cat 是 IntMap.t animal 的子类型。
使用点变型标记法(通配符)
声明点标记法的一个缺点是许多接口类型必须是不变的。例如,前面的 IList<T> 需要是不变的,因为其中既有协变的函数也有逆变的函数。为了暴露更多的变型性,API 设计者可以提供附加的接口以提供可用方法的子集——例如,一个只提供 Insert 函数的“只写列表”。然而这太笨拙了。
使用点标记法试图给某个类的用户以更多的机会去继承,而不要求该类的设计者分开定义具有不同变型性质的若干接口。当某个类或接口被应用于类型声明中时,程序员可以指明用到的只有成员函数的一个子集。就效果而言,类的定义同时也给出了相当于该类的协变和逆变的“部分”的接口。因此,类的设计者不再需要把变型纳入考虑,从而提高了可重用性,
Java 通过通配符提供使用点变型标记,这是一种有界的约束存在量化形式。一个参数化类型可以通过通配符 ? 加上上下界的形式实例化,例如 List<? extends Animal> 或者 List<? super Animal>。(诸如 List<?> 这样不加约束的通配符等价于 List<? extends Object>,因为 Java 的所有类型都派生自 Object)。List<X> 这样的类型表明了未知类型 X 满足约束这件事。例如,如果变量 l 是 List<? extends Animal> 类型,那么类型检查器会接受
Animal a = l.get(3);
因为已知类型 X 是 Animal 的子类,相反
l.add(new Animal())
将会导致类型错误,因为一个 Animal 并不一定是个 X。一般而论,给定某个接口 I<T>,一个 I<? extends A> 的记法禁止使用需要 T 逆变的函数;反之,如果 l 的类型是 List<? super Animal>,我们可以调用 l.add 但不能调用 l.get。
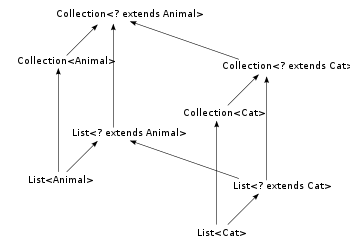
虽然 Java 中的普通泛型类型是不变的(即在 List<Cat> 和 List<Animal> 之间没有子类关系),通配符类型仍可以通过指定一个更严格的界来变得更加特化。例如,List<? extends Cat> 是 List<? extends Animal> 的子类型。这显示了通配符类型是在上界协变(以及在下界逆变)的。总而言之,给定一个诸如 C<? extends T> 的通配符类型,有三种方式可以形成子类:特化类 C、指定更加严格的约束 T、或者把通配符 ? 替换成一个更特化的类型(见图)。
通过把子类化的两个步骤合并,我们就可以做到诸如给期望 List<? extends Animal> 类型参数的函数传递一个 List<Cat> 参数这样的事。这正是协变接口类型所允许的程序。List<? extends Animal> 类型就像一个只包含 List<T> 的那些协变的函数的接口,然而 List<T> 的实现者并不需要预先作出定义。这就是使用点变型。
在 IList<T> 这种常见的泛型数据结构中,协变参数用于从结构中读出数据,而逆变参数用于写入数据。Joshua Bloch 所著《Effective Java》中提出的助记短语 PECS(Producer Extends, Consumer Super)提供了一个合适使用协变 / 逆变的好记方法。
通配符很灵活,但也有个缺点。虽然使用点变型意味着 API 设计者不需要考虑接口的类型参数的变型性质,他们却经常需要使用更复杂的函数签名。一个常见例子涉及到 Java 中的 Comparable 接口。假设我们要写一个查找集合中最大元素的函数,这些元素需要实现 compareTo 函数,所以首先我们可能会做如下尝试:
<T extends Comparable<T>> T max(Collection<T> coll);
然而这并不够泛型——我们会发现能够找到一个 Collection<Calendar> 集合中的最大值,但对 Collection<GregorianCalendar> 而言则否。问题在于 GregorianCalendar 并不实现 Comparable<GregorianCalendar> 接口,而是实现了(更好的)Comparable<Calendar>。不像 C#,在 Java 中 Comparable<Calendar> 并不被认为是 Comparable<GregorianCalendar> 的子类。因此 max 的类型要改成这样:
<T extends Comparable<? super T>> T max(Collection<T> coll);
有界通配符 ? super T 用来表明 max 只调用 Comparable 接口的逆变函数。这个示例令人沮丧的原因是 Comparable 接口中的所有函数都是逆变的,因此条件是平凡真、所有用到这个接口的函数都要这样。声明点变型的系统就可以让这个例子不那么啰嗦:只需要在 Comparable 接口上标注即可。
比较声明点与使用点变型
使用点变型提供了额外的灵活性,允许更多程序得以通过类型检查。然而,它们因为给语言带来的复杂性、以及所引发的复杂类型签名和错误消息而饱受批评。
一个评判这种额外灵活性是否有用的方法是看它能否应用在现存程序里。一个对大量 Java 库的调查[9]发现 39% 的通配符标记本可以用一个声明点标记直接换掉,也即那剩下的 61% 是 Java 受益于有这么个使用点变型系统的地方。
在声明点变型语言中,库必须要么更少地暴露变型、要么定义更多的接口。例如,Scala 集合库给每个接口都定义了三个分开的版本:基本版本是不变型的、也不提供任何写操作,有带副作用函数的可写版本,还有不可写但把类型参数(通常)标为协变的版本[11]。这种设计跟声明点标注配合得很好,但大量的接口给库的用户带来了复杂性开销。并且,修改库接口可能不是一个可行选项——具体来说,Java 泛型的一个目标就是要维持二进制向后兼容性。
另一方面,Java 的通配符本身就有够复杂。在一场会议讲演[12],Joshua Bloch 就批评它们太过难懂难用,声称当添加闭包支持时“再来一个通配符简直就是不能承受之重”。早期版本的 Scala 使用使用点标注,然而程序员觉得它们难于实际应用,而声明点标注就在设计类时有大用[13]。后期版本的 Scala 添加了 Java 样式的存在类型和通配符;然而据 Martin Odersky 所说,假如没有跟 Java 的互操作性需求的话,这些根本都不会被加进来[14]。
Ross Tate 争辩说[15] Java 通配符的复杂性有一部分是因为决定了要用存在类型的记法来标记使用点变型。原本的提案[16]
[17]是使用专门用途的语法来标记变型,写作 List<+Animal> 而不是 Java 这么啰嗦的 List<? extends Animal>。
既然通配符是存在类型的一种形式,它们就不仅可以用来做变型这一种事。一个诸如 List<?>(某种列表)的类型允许对象不必指定类型参数就能被传递给函数或者放进变量里。这对于像 Class 这样的类而言尤其有用,因为其中的大多数函数都根本不管类型参数是什么。
然而,对于存在类型的类型推导是一个难点。对于编译器实现者来说,Java 的通配符提出了类型检查器终结、类型参数推导、以及歧义程序的问题[18]。对程序员来说,它则带来了复杂的类型错误消息。Java 通过把通配符换成新类型变量的方式进行类型检查(所谓捕获检查),这会让错误信息更难读,因为它们现在指向了程序员根本没直接写出的类型变量。例如,试图将一个 Cat 加到 List<? extends Animal> 会得到类似这样的错误:
函数 List.add(capture#1) 不能应用
(实参 Cat 不能被函数调用转换成 capture#1)
其中 capture#1 是新类型变量:
capture#1 extends Animal,由于捕获了 ? extends Animal“协变”一词的来源
这些术语来源于范畴论中函子的记法。考虑范畴 C,其中的对象是类型、其态射代表了子类关系≦(这是一个任何偏序集合可被看成范畴的例子);那么诸如函数的类型构造器接受两个类型 p 和 r 并创建一个新类型 p→r,即它把 C2 中的对象映射到 C 中。通过函数类型的子类规则,这个运算逆转了第一参数上的≦顺序而在第二参数上保持该顺序,即它是一个在第一参数上逆变、而在第二参数上协变的函子。
参考文献
- Luca Cardelli. (PDF). Semantics of Data Types (International Symposium Sophia-Antipolis, France, June 27 – 29, 1984). Lecture Notes in Computer Science 173. Springer. 1984 [2014-01-24]. doi:10.1007/3-540-13346-1_2. (原始内容存档 (PDF)于2014-02-01).(Longer version in Information and Computation, 76(2/3): 138-164, February 1988.)
- Allison, Chuck. . [2014-01-24]. (原始内容存档于2012-05-27).
- Bertrand Meyer. (PDF). . October 1995 [2014-01-24]. (原始内容存档 (PDF)于2012-11-14).
- Howard, Mark; Bezault, Eric; Meyer, Bertrand; Colnet, Dominique; Stapf, Emmanuel; Arnout, Karine; Keller, Markus. (PDF). April 2003 [2013-05-23]. (原始内容存档 (PDF)于2013-10-05).
- Franz Weber. . . 1992 [2014-01-24]. (原始内容存档于2013-10-08).
- Giuseppe Castagna, Covariance and contravariance: conflict without a cause, ACM Transactions on Programming Languages and Systems (TOPLAS), Volume 17, Issue 3, May 1995, pages 431-447.
- Eric Lippert. . 2009-12-03 [July 2013]. (原始内容存档于2013-05-28).
- Section II.9.7 in ECMA International Standard ECMA-335 Common Language Infrastructure (CLI) 6th edition (June 2012); available online (页面存档备份,存于)
- John Altidor; Huang Shan Shan; Yannis Smaragdakis. (PDF). . 2011 [2014-01-24]. (原始内容 (PDF)存档于2012-01-06).
- Eric Lippert. . 2007-10-29 [October 2013]. (原始内容存档于2010-01-23).
- Marin Odersky; Lex Spoon. . 2010-09-07 [May 2013]. (原始内容存档于2014-05-30).
- Joshua Bloch. . Presentation at Javapolis'07. November 2007 [May 2013]. (原始内容存档于2014-02-02).
- Martin Odersky; Matthias Zenger. (PDF). . 2005 [2014-01-24]. (原始内容存档 (PDF)于2013-01-24).
- Bill Venners and Frank Sommers. . 2009-05-18 [May 2013]. (原始内容存档于2014-02-01).
- Ross Tate. . . 2013 [2014-01-24]. (原始内容存档于2014-02-01).
- Atsushi Igarashi; Mirko Viroli. (PDF). . 2002 [2014-01-24]. (原始内容 (PDF)存档于2006-06-22).
- Kresten Krab Thorup; Mads Torgersen. (PDF). . 1999 [2014-01-24]. (原始内容 (PDF)存档于2015-09-23).
- Tate, Ross; Leung, Alan; Lerner, Sorin. . . 2011 [2014-01-24]. (原始内容存档于2014-02-09).
- . 2013-05-06 [May 2013]. (原始内容存档于2014-01-02).
外部链接
- Fabulous Adventures in Coding(页面存档备份,存于): 一系列关于 C# 中协变 / 逆变的实现注意事项的文章
- Contra Vs Co Variance(并没随 C++ 与时俱进)
- Java 7 的闭包(v0.5)(页面存档备份,存于)