线性分类器
在機器學習領域,分類的目標是指將具有相似特徵的对象聚集。而一個線性分類器則透過特徵的線性組合來做出分類決定,以達到此種目的。对象的特征通常被描述为特征值,而在向量中则描述为特征向量。
定義
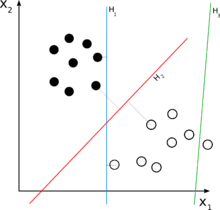
如果輸入的特徵向量是實數向量,則輸出的分數為:

- ,

其中是一個權重向量,而f是一個函數,该函数可以通过预先定义的功能块,映射兩個向量的點積,得到希望的輸出。權重向量是從带标签的訓練樣本集合中所學到的。通常,"f"是個簡單函數,會將超过一定阈值的值對應到第一類,其它的值對應到第二類。一個比较複雜的"f"則可能將某個東西歸屬於某一類。


對於一個二元分類問題,可以设想成是将一个线性分类利用超平面划分高维空间的情况: 在超平面一側的所有點都被分類成"是",另一側則分成"否"。
作为最快分類器,線性分類器通常应用于对分类速度有较高要求的情况下,特別是當为稀疏向量时。雖然如此,決策樹可以更快。此外,當的維度很大時,線形分類器通常表現良好。如文本分類時,傳統上,中的一個元素是文章所使用到的某個辭彙的出現的次數。在這種情況下,分類器應被適當地正則化。
生成模型與判別模型
有兩種類型用來決定[1][2]的線性分類器。第一種模型條件機率。這類的算法包括:

第二種方式則稱為判別模型(discriminative models),这种方法是试图去最大化一個訓練集(training set)的輸出值。在訓練的成本函數中有一個額外的項加入,可以容易地表示正則化。例子包含:
- Logit模型 --- 的最大似然估計,其假設觀察到的訓練集是由一個依赖于分類器的輸出的二元模型所產生。
- 感知元(Perceptron) --- 一個試圖去修正在訓練集中遇到錯誤的算法。
- 支持向量機 --- 一個試圖去最大化決策超平面和訓練集中的样本間的邊界(margin)的算法。
注意:相對於名字,線性判別分析在分類學並不屬於判別模型這類。然而,當我們比較線性判別分析和另一主要的線性降维算法:主成分分析,它的名字則是有意義的。線性判別分析是一個監督式學習算法,會使用資料中的标签。而主成分分析是一個不考慮標籤的非監督式學習算法。简而言之,這個名字是一個歷史因素[3]。
判別訓練通常會比模型化條件密度函數產生較高的準確。然而,在處理遺失資料時,使用條件密度模型通常是更為簡單的。
所有以上所列線性分類器演算法,只要使用kernel trick都可被轉成在另一個向量空間的非線性演算法。
另見
- 二次分類器
- 統計分類
参考文献
引用
- T. Mitchell, Generative and Discriminative Classifiers: Naive Bayes and Logistic Regression. Draft Version, 2005 download (页面存档备份,存于)
- A. Y. Ng and M. I. Jordan. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and Naive Bayes. in NIPS 14, 2002. download (页面存档备份,存于)
- R.O. Duda, P.E. Hart, and D.G. Stork. "Pattern Classification", Wiley, 2001. ISBN 0-471-05669-3, p. 117.
来源
- Y. Yang, X. Liu, "A re-examination of text categorization", Proc. ACM SIGIR Conference, pp. 42-49,(1999). paper @ citeseer (页面存档备份,存于)
- R. Herbrich, "Learning Kernel Classifiers: Theory and Algorithms," MIT Press,(2001). ISBN 0-262-08306-X