蛋白质家族
蛋白质家族(英語:)是一组与演化相关的蛋白质。在许多情况下,蛋白质家族具有相应的基因家族,其中每个基因编码具有1:1关系的相应蛋白质。
术语「蛋白质家族」的「家族」(Family)不应该与「科 (生物)」(英語:)混淆,因为「科 (生物)」用于生物分类学。
家族中的蛋白质来自共同的祖先(见同源),通常具有相似的三维结构,功能和显着的序列相似性。其中最重要的是序列相似性(通常是氨基酸序列),因为它是同源的最严格指标,因此是共同祖先的最清晰的指标。使用序列比对方法评估一组序列之间的相似性的重要性存在相当完善的框架。不共享共同祖先的蛋白质不太可能显示统计学上显着的序列相似性,使序列比对成为识别蛋白质家族成员的有力工具。
有时候,家族有时被分组成更大的演化支称为蛋白质超家族,基于结构和机械相似性,即使没有可识别的序列同源性。
目前,已经定义了超过60,000个蛋白质家族[1],尽管在“蛋白质家族”定义中的歧义导致不同的研究人员在得到的蛋白质家族总数上有数量的变化。
术语和用法
与许多生物学术语一样,术语「蛋白质家族」的使用在一定程度上取决于上下文。 它可能表示具有尽可能低的可检测序列相似性水平的大群的蛋白质,或者表示具有几乎相同的序列,功能和三维结构的非常狭窄的蛋白质群,或介于两者之间的任何群。 为了区分这些情况,术语「蛋白质超家族」通常用于远距离相关的蛋白质,这些蛋白质的相关性无法通过序列相似性检测到,而只能通过共享的结构特征来检测[2][3][4]。这些年来,诸如蛋白质类别(class),组别(group),氏族(clan),和亚家族(sub-family)之类的其他术语也被创造出来了,但是它们在用法上都存在相似的歧义。 一种常见用法是,超家族(结构同源性)包含具有亚家族的家族(序列同源性)。 因此,一个超家族,例如蛋白酶的蛋白酶PA氏族,其序列保守性远低于其所包含的家族之一的C04家族。 不太可能会商定确切的定义,而是由读者来确定确切地在特定上下文中使用这些术语的方式。

蛋白质的结构域和模体
蛋白质家族的概念是在还很少知道蛋白质结构或序列的时候被构想的。 那时,在结构上理解的主要是小的和单一结构域的蛋白,例如肌红蛋白,血红蛋白和细胞色素c。 从那时起,发现许多蛋白质包含多个独立的结构和功能单元或结构域(protein domain)。 由于演化改组,一个蛋白质中的不同结构域已经有独立的演化。 近年来,这导致了对蛋白质结构域家族的关注。 许多在线资源致力于标识和分类这样的结构域(请参阅本文结尾处的列表)。
每种蛋白质的区域具有不同的功能限制(对于蛋白质的结构和功能至关重要的特征)。 例如,酶的活性位点需要某些氨基酸残基在三个维度上精确定向。 另一方面,蛋白质与蛋白质的结合界面可能由较大的表面组成,并限制了氨基酸残基的疏水性或极性。 蛋白质的功能限制区比无限制区(如表面环)进化得更慢,当比较蛋白质家族的序列时,会形成可辨别的保守序列区(请参阅多重序列比對)。 尽管使用了许多其他术语(块,签名,指纹等),但这些块通常被称为模体(motif)。 同样,许多在线资源都致力于识别和分类蛋白质模体(请参阅文章结尾处的列表)。
蛋白质家族的演化
根据目前的共识,蛋白质家族以两种方式产生。 首先,将亲本物种分离为两个遗传分离的后代物种可以使基因/蛋白质独立地积累这两个谱系中的变异(突变)。 这产生了直系同源蛋白家族,通常具有保守的序列基序。 其次,基因重复可以产生基因的第二个拷贝(称为旁系同源物)。 因为原本的基因仍然能够执行其功能,所以复制的基因可以自由发散并可以获取新功能(通过随机突变)。某些基因/蛋白质家族,特别是在真核生物中,在进化过程中会经历极端的扩张和收缩,有时会与全基因组复制相一致。 蛋白质家族的这种扩张和收缩是基因组进化的显着特征之一,但是其重要性和后果目前尚不清楚。
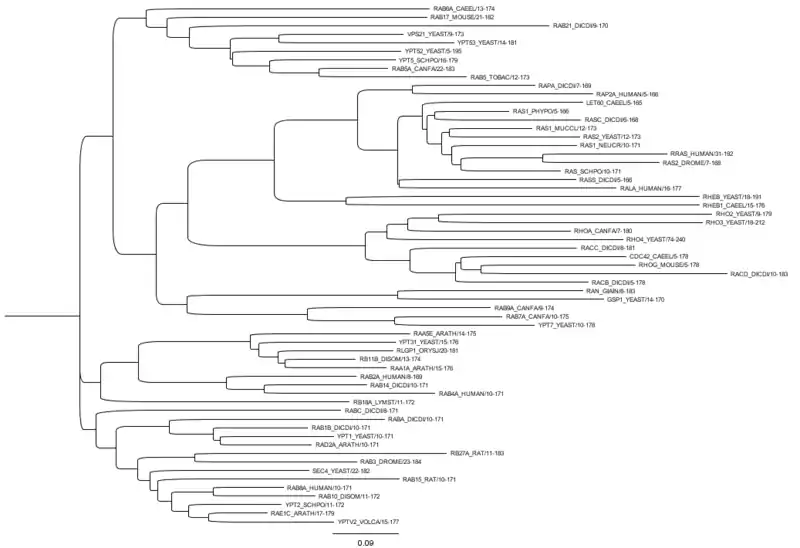
蛋白质家族的用途和重要性
随着已经被测序蛋白质总数的增加以及对蛋白质组分析的兴趣不断扩大,人们正在努力将蛋白质组织成家族并描述其组成结构域和模体。 可靠地鉴定蛋白质家族对于系统发生分析,功能注释以及在给定的系统发育分支中探索蛋白质功能的多样性至关重要。酶功能倡议(Enzyme Function Initiative,EFI)正在使用蛋白质家族和超家族作为开发基于序列/结构的策略的基础,以用于未知功能酶的大规模功能分配[5]。
用于大规模建立蛋白质家族的算法手段是基于相似性的概念。 在大多数情况下,我们可以访问的唯一相似性是序列相似性。
蛋白质家族资源
有许多生物数据库记录蛋白质家族的例子,并允许用户识别新鉴定的蛋白质是否属于已知家族。 以下是几个例子:
- Pfam - 蛋白家族数据库比对和HMMs
- PROSITE - 蛋白质结构域,家族和功能位点的数据库
- InterPro - 超家族分类系统
- PASS2 - Protein Alignment as Structural Superfamilies v2 - PASS2@NCBS[6]
- Superfamily database - 超家族的数据库
- SCOP和CATH - 蛋白质结构的分类分为超家族,家族和结构域
类似地,存在许多数据库搜索算法,例如:
参考文献
- Kunin, V.; Cases, I.; Enright, A. J.; De Lorenzo, V.; Ouzounis, C. A. . Genome Biology. 2003, 4 (2): 401. PMC 151299
 . PMID 12620116. doi:10.1186/gb-2003-4-2-401.
. PMID 12620116. doi:10.1186/gb-2003-4-2-401. - Dayhoff MO. . Federation Proceedings. December 1974, 33 (12): 2314–6. PMID 4435228.
- Dayhoff MO, McLaughlin PJ, Barker WC, Hunt LT. . Die Naturwissenschaften. 1975, 62 (4): 154–161. Bibcode:1975NW.....62..154D. doi:10.1007/BF00608697.
- Dayhoff MO. . Federation Proceedings. August 1976, 35 (10): 2132–8. PMID 181273.
- Gerlt JA, Allen KN, Almo SC, Armstrong RN, Babbitt PC, Cronan JE, Dunaway-Mariano D, Imker HJ, Jacobson MP, Minor W, Poulter CD, Raushel FM, Sali A, Shoichet BK, Sweedler JV. . Biochemistry. November 2011, 50 (46): 9950–62. PMC 3238057 . PMID 21999478. doi:10.1021/bi201312u.
- Gandhimathi A, Nair AG, Sowdhamini R. . Nucleic Acids Research. January 2012, 40 (Database issue): D531–4. PMC 3245109 . PMID 22123743. doi:10.1093/nar/gkr1096.
- Emms DM, Kelly S. . Genome Biology. August 2015, 16: 157. PMC 4531804 . PMID 26243257. doi:10.1186/s13059-015-0721-2.
- Emms DM, Kelly S. . Genome Biology. November 2019, 20 (1): 238. PMC 6857279 . PMID 31727128. doi:10.1186/s13059-019-1832-y.