遗传密码
遺傳密碼[1][2](Genetic code)又稱遺傳編碼,是遺傳的傳遞規則,將DNA或mRNA序列以三個核苷酸為一組的“密码子(codon)”轉譯為蛋白質的氨基酸序列,以用於蛋白質合成。幾乎所有的生物都使用同樣的遺傳密碼,稱為“標準遺傳密碼”;即使是非細胞結構的病毒,它們也是使用標準遺傳密碼。有些具感染性的致病因子,使用一些稍微不同的遺傳密碼,如朊毒體以蛋白質為遺傳密碼。密码子简并性是遗传密码的突出特征。[3]

破解歷史
自從發現了DNA的結構,科學家便開始致力研究有關製造蛋白質的秘密。伽莫夫通过计算指出需要以三個核酸一組才能為20個氨基酸編碼[4]。1961年,弗朗西斯·克里克对T4噬菌体的某个基因中增加或删除碱基对。以该基因最终合成蛋白的情况。证明“以三个碱基对编码一个氨基酸”,以及遗传密码有固定起点,且以非重叠无分隔符形式阅读的特点。美國國家衛生院的J·海因里希·马特伊與馬歇爾·沃倫·尼倫伯格在無細胞系統環境下,把一條只由尿嘧啶(U)組成的RNA轉釋成一條只有苯丙氨酸(Phe)的多肽,由此破解了首個密碼子(UUU -> Phe)[5]。隨後哈爾·葛賓·科拉納破解了其它密碼子,接著羅伯特·W·霍利發現了負責轉錄過程的tRNA。1968年,科拉納、霍利和尼倫伯格分享了諾貝爾生理學或醫學獎。
基因組的表達
一個生物體攜帶的遺傳信息-即基因組-被記錄在DNA或RNA分子中,分子中每個有功能的單位被稱作基因。每個基因均是由一連串單核苷酸組成。每個單核苷酸均由鹼基,戊糖(即五碳糖,DNA中為脫氧核糖,RNA中為核糖)和磷酸三部分組成。碱基不同構成了不同的單核苷酸。組成DNA的碱基有腺嘌呤(A),鳥嘌呤(G),胞嘧啶(C)及胸腺嘧啶(T)。組成RNA的碱基以尿嘧啶(U)代替了胸腺嘧啶(T)。三個單核苷酸形成一組密碼子,而每個密碼子代表一個氨基酸或停止訊號。
製造蛋白質的過程中,基因先被從DNA轉錄為對應的RNA範本,即信使RNA(mRNA)。接下來在核糖體和轉移RNA(tRNA)以及一些酶的作用下,由該RNA範本轉譯成為氨基酸組成的鏈(多肽),然後經過轉譯後修飾形成蛋白質。詳情參閱轉譯。
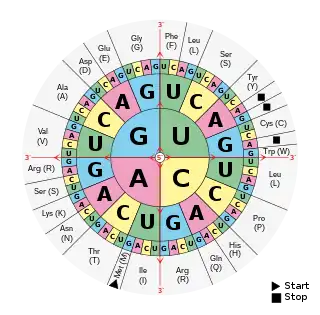
因為密碼子由三個核苷酸組成,故一共有43=64種密碼子。例如,RNA序列UAGCAAUCC包含了三個密碼子:UAG,CAA和UCC。這段RNA編碼代表了長度為3個氨基酸的一段蛋白質序列。(DNA也有類似的序列,但是以T代替了U)。
標準遺傳密碼如下表所示:由3個鹼基對應到氨基酸的密碼子表以及由氨基酸對應到3個鹼基的反密碼子表。
密码子表
RNA密码子表
| 氨基酸生化性质 | 非极性 | 极性 | 碱性 | 酸性 | 终止密码子 |
| 碱基1 | 碱基2 | 碱基3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| U | C | A | G | ||||||
| U | UUU | (Phe/F) |
UCU | (Ser/S) |
UAU | (Tyr/Y) |
UGU | (Cys/C) |
U |
| UUC | UCC | UAC | UGC | C | |||||
| UUA | (Leu/L) |
UCA | UAA[B] | 终止(赭石) | UGA[B] | 终止(蛋白石) | A | ||
| UUG | UCG | UAG[B] | 终止(琥珀) | UGG | (Trp/W)色氨酸 | G | |||
| C | CUU | CCU | (Pro/P) |
CAU | (His/H) |
CGU | (Arg/R) |
U | |
| CUC | CCC | CAC | CGC | C | |||||
| CUA | CCA | CAA | (Gln/Q) |
CGA | A | ||||
| CUG | CCG | CAG | CGG | G | |||||
| A | AUU | (Ile/I) |
ACU | (Thr/T) |
AAU | (Asn/N) |
AGU | (Ser/S) |
U |
| AUC | ACC | AAC | AGC | C | |||||
| AUA | ACA | AAA | (Lys/K) |
AGA | (Arg/R) |
A | |||
| AUG[A] | (Met/M) |
ACG | AAG | AGG | G | ||||
| G | GUU | (Val/V) |
GCU | (Ala/A) |
GAU | (Asp/D) |
GGU | (Gly/G) |
U |
| GUC | GCC | GAC | GGC | C | |||||
| GUA | GCA | GAA | (Glu/E) |
GGA | A | ||||
| GUG | GCG | GAG | GGG | G | |||||
- A 密码子AUG同时编码甲硫氨酸并作为起始点:在信使RNA的编码区里,首个ATG的出现标志着蛋白质翻译的开始。[6]
- B ^ ^ ^ 标示终止密码子为琥珀、赭石和蛋白石的历史原因可在悉尼·布伦纳()的自传[7]和鲍勃·埃德加()的一篇历史性文章中找到。[8]
| 氨基酸 | 密码子 | 缩写 | 氨基酸 | 密码子 | 缩写 |
|---|---|---|---|---|---|
| Ala/A | GCU、GCC、GCA、GCG | GCN | Leu/L | UUA、UUG、CUU、CUC、CUA、CUG | YUR、CUN |
| Arg/R | CGU、CGC、CGA、CGG、AGA、AGG | CGN、MGR | Lys/K | AAA、AAG | AAR |
| Asn/N | AAU、AAC | AAY | Met/M | AUG | |
| Asp/D | GAU、GAC | GAY | Phe/F | UUU、UUC | UUY |
| Cys/C | UGU、UGC | UGY | Pro/P | CCU、CCC、CCA、CCG | CCN |
| Gln/Q | CAA、CAG | CAR | Ser/S | UCU、UCC、UCA、UCG、AGU、AGC | UCN、AGY |
| Glu/E | GAA、GAG | GAR | Thr/T | ACU、ACC、ACA、ACG | ACN |
| Gly/G | GGU、GGC、GGA、GGG | GGN | Trp/W | UGG | |
| His/H | CAU、CAC | CAY | Tyr/Y | UAU、UAC | UAY |
| Ile/I | AUU、AUC、AUA | AUH | Val/V | GUU、GUC、GUA、GUG | GUN |
| 起始 | AUG | 终止 | UAA、UGA、UAG | UAR、URA | |
技術細節
起始和終止密碼子
蛋白質的轉譯從初始化密碼子(起始密碼子)開始,但亦需要適當的初始化序列和起始因子才能使mRNA和核糖體結合。最常見的起始密碼子為AUG,其同時編碼的氨基酸在細菌為甲醯甲硫氨酸,在真核生物為甲硫氨酸,但在個別情況其它一些密碼子也具有起始的功能。
在經典遺傳學中,終止密碼子各有名稱:UAG為琥珀(amber),UGA為蛋白石(opal),UAA為赭石(ochre)。這些名稱來源於最初發現到這些終止密碼子的基因的名稱。終止密碼子使核醣體和釋放因子結合,使多肽從核醣體分離而結束轉譯的程式。另外,在哺乳動物的線粒體中,AGA和AGG也充當終止密碼子。
密碼子簡併性
大部分密碼子具有簡併性,即兩個或者多個密碼子編碼同一氨基酸。簡併的密碼子通常只有第三位元碱基不同,例如,GAA和GAG都編碼穀氨醯胺。如果密码子前两位相同,而且不管密碼子的第三位為哪種核苷酸,都編碼同一種氨基酸,則稱之為四重簡併密碼子(fourfold degenerate codons);如果三位中的某一位有两种核苷酸使该密码子編碼同一種氨基酸,則稱之為二重簡併密碼子(twofold degenerate codons),一般第三位上兩種等價的核苷酸同為嘌呤(A/G,或R)或者嘧啶(C/T,或Y)。只有兩種氨基酸僅由一個密碼子編碼,一個是甲硫氨酸,由AUG編碼,同時也是起始密碼子;另一個是色氨酸,由UGG編碼。
遺傳密碼的這些性質可使基因更加耐受點突變。例如,四重簡併密碼子可以容忍密碼子第三位元的任何變異;二重簡併密碼子使三分之一可能的第三位的變異不影響蛋白質序列。由於轉換變異(嘌呤變為嘌呤或者嘧啶變為嘧啶)比顛換變異(嘌呤變為嘧啶或者嘧啶變為嘌呤)的可能性更大,因此二重簡併密碼子也具有很強的對抗突變的能力。不影響氨基酸序列的突變稱為沉默突變。
簡併性的出現是由於tRNA反密碼子的第一位碱基可以和mRNA構成擺動碱基對,常見的情況為反密碼子上的次黃嘌呤(I),以及和密碼子形成非標準的U-G配對。
另一種有助對抗點突變的情況,是NUN(N代表任何核苷酸)傾向於代表疏水性氨基酸,故此即使出現突變,仍有較大機會維持蛋白質的親水度,減低致命破壞的可能。
閱讀框
“密碼子”是由閱讀的起始位點決定的。例如,一段序列GGGAAACCC,如果由第一個位置開始讀,包括3個密碼子GGG,AAA和CCC。如果從第二位開始讀,包括GGA和AAC(忽略不完整的密碼子)。如果從第三位開始讀,則為GAA和ACC。故此每段序列都包括多個閱讀框,每個都能產生不同的氨基酸序列(在上例中,相應為Gly-Lys-Pro,Gly-Asp,和Glu-Thr)。而因為DNA的雙螺旋結構,每段DNA實際上有六個閱讀框。 實際的框架是由起始密碼子確定,通常是mRNA序列上第一個出現的AUG。
破壞閱讀框架的變異(例如,插入或刪除1個或2個核苷酸)稱為閱讀框變異,通常會嚴重影響到蛋白質的功能,故此並不常見,因為它們通常不能在演化中存活下來。
非標準的遺傳密碼
雖然遺傳密碼在不同生命之間有很強的一致性,但亦存在非標準的遺傳密碼。在有「細胞能量工廠」之稱的線粒體中,便有和標準遺傳密碼數個相異的之處,甚至不同生物的線粒體有不同的遺傳密碼。支原體會把UGA轉譯為色氨酸。纖毛蟲則把UAG(有時候還有UAA)轉譯為穀氨醯胺(一些綠藻也有同樣現象),或把UGA轉譯為半胱氨酸。一些酵母會把GUG轉譯為絲氨酸。在一些罕見情況,一些蛋白質會有AUG以外的起始密碼子。
真菌、原生生物和人以及其它動物的粒線體中的遺傳密碼與標準遺傳密碼的差異,主要變化如下:
| 密码子 | 通常的作用 | 例外的作用 | 所屬的生物 |
|---|---|---|---|
| UGA | 中止編碼 | 色氨酸編碼 | 人、牛、酵母線粒體,支原體(Mycoplasma)基因組,如Capricolum |
| UGA | 中止編碼 | 半胱氨酸編碼 | 一些纖毛蟲(ciliate)細胞核基因組,如遊纖蟲屬(Euplotes) |
| UGA | 中止編碼 | 硒半胱氨酸編碼 | 人,大鼠,小鼠等哺乳体系 |
| AGR | 精氨酸編碼 | 中止編碼 | 大部分動物線粒體,脊椎動物線粒體 |
| AGA | 精氨酸編碼 | 絲氨酸編碼 | 果蠅線粒體 |
| AUA | 異亮氨酸編碼 | 蛋氨酸編碼 | 一些動物和酵母線粒體 |
| UAA | 中止編碼 | 穀氨醯胺編碼 | 草履蟲、一些纖毛蟲(ciliate)細胞核基因組,如嗜熱四膜蟲(ThermophAilus tetrahymena) |
| UAG | 中止編碼 | 谷氨酸編碼 | 草履蟲核細胞核基因組 |
| UAG | 中止編碼 | 吡咯赖氨酸編碼 | 甲烷八叠球菌(Methanosarcina barkeri)核基因組,表达转甲基酶(methyltransferase) |
| GUG | 纈氨酸編碼 | 絲氨酸編碼 | 假絲酵母核基因組 |
| AAA | 賴氨酸編碼 | 天冬氨酸編碼 | 一些動物的線粒體,果蠅線粒體 |
| CUG | 亮氨酸編碼 | 絲氨酸編碼 | 白色念珠菌(Candida albicans)等酵母的細胞核基因組 |
| CUN | 亮氨酸編碼 | 蘇氨酸編碼 | 酵母線粒體 |
按信使RNA的序列,在一些蛋白質裏停止密碼子會被翻譯成非標準的氨基酸,例如UGA轉譯為硒半胱氨酸和UAG轉譯為吡咯賴氨酸,隨著對基因組序列加深瞭解,科學家可能還會發現其它非標準的轉譯方式,以及其它未知氨基酸在生物中的應用。
遺傳密碼的起源
除了少數的不同之外,地球上已知生物的遺傳密碼均非常接近;這顯示遺傳密碼應在生命演化的歷史中很早期就出現,並且證明了所有生物都源自共同祖先。
現有的證據表明遺傳密碼的設定並非是隨機的結果,對此有以下的可能解釋1:
- 最近一項研究顯示,一些氨基酸與它們相對應的密碼子有選擇性的化學結合力2,這顯示現在複雜的蛋白質製造過程可能並非一早存在,最初的蛋白質可能是直接在核酸上形成。
搖擺特性
1966年,弗朗西斯·克里克提出了摆动假说(英文:wobble hypothesis)。即一組密碼子可對應多個反密碼子。因為第三對鹼基對有時不遵守配對原則,稱為搖擺鹼基對。[5]
搖擺特性的碱基配对如下:
| 密碼子第三對鹼基 | 反密碼子第一對鹼基 |
| G | C |
| U | A |
| A、G | U |
| C、U | G |
摆动假说现已被多方实验证明。[5]
參考資料
- ^ 注解1: Knight, R.D.; Freeland S. J. and Landweber, L.F. (1999) The 3 Faces of the Genetic Code. Trends in the Biochemical Sciences 24(6), 241-247.
- ^ 注解2: Knight, R.D. and Landweber, L.F. (1998). Rhyme or reason: RNA-arginine interactions and the genetic code. (页面存档备份,存于) Chemistry & Biology 5(9), R215-R220. PDF version of manuscript
- ^ 注解3: Brooks, Dawn J.; Fresco, Jacques R.; Lesk, Arthur M.; and Singh, Mona. (2002). Evolution of Amino Acid Frequencies in Proteins Over Deep Time: Inferred Order of Introduction of Amino Acids into the Genetic Code. Molecular Biology and Evolution 19, 1645-1655.
- ^ 注解4: Amirnovin R. (1997) An analysis of the metabolic theory of the origin of the genetic code. Journal of Molecular Evolution 44(5), 473-6.
- ^ 注解5: Ronneberg T.A.; Landweber L.F. and Freeland S.J. (2000) Testing a biosynthetic theory of the genetic code: Fact or artifact? (页面存档备份,存于) Proceedings of the National Academy of Sciences, USA 97(25), 13690-13695.
- ^ 注解6: Freeland S.J.; Wu T. and Keulmann N. (2003) The Case for an Error Minimizing Genetic Code. (页面存档备份,存于) Orig Life Evol Biosph. 33(4-5), 457-77.
其它參考資料
網路上有很多有關本題目的資料,由美國國家衛生院提供NCBI Bookshelf。
- Griffiths, Anthony J.F.; Miller, Jeffrey H.; Suzuki, David T.; Lewontin, Richard C.; Gelbart, William M. (1999). Introduction to Genetic Analysis (7th ed.). New York: W. H. Freeman & Co. ISBN 0-7167-3771-X
- Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Raff, Martin; Roberts, Keith; Walter, Peter. (2002). Molecular Biology of the Cell (4th ed.). New York: Garland Publishing. ISBN 0-8153-3218-1
- Lodish, Harvey; Berk, Arnold; Zipursky, S. Lawrence; Matsudaira, Paul; Baltimore, David; Darnell, James E. (1999). Molecular Cell Biology (4th ed.). New York: W. H. Freeman & Co. ISBN 0-7167-3706-X
- 有關遺傳密碼演化的wiki (页面存档备份,存于)
- NCBI網頁,有關遺傳密碼的詳細的說明 (页面存档备份,存于)
参考文献
- . [2021-10-07]. (原始内容存档于2021-10-07).
- . [2021-10-07]. (原始内容存档于2021-10-07).
- Shu, Jian-Jun. . BioSystems. January 2017, 151: 21–26. Bibcode:2017arXiv170303787S. PMID 27887904. arXiv:1703.03787
 . doi:10.1016/j.biosystems.2016.11.004.
. doi:10.1016/j.biosystems.2016.11.004. - Wang, Liming,; 王立铭,. . Di 1 ban. Hangzhou. ISBN 978-7-213-07975-7. OCLC 1000575553.
- Paolella, Peter. . . Qing hua ta xue chu ban she. 2002. ISBN 7-302-05095-3. OCLC 298594848.
- Nakamoto T. . Gene. March 2009, 432 (1–2): 1–6. PMID 19056476. doi:10.1016/j.gene.2008.11.001.
- Brenner S. A Life in Science (2001) Published by Biomed Central Limited ISBN 0-9540278-0-9 see pages 101-104
- . Genetics. 2004, 168 (2): 575–82. PMC 1448817 . PMID 15514035.