ROC曲线
在信号检测理论中,接收者操作特征曲線,或者叫ROC曲线(英語:),是一种坐標圖式的分析工具,用於选择最佳的信號偵測模型、捨棄次佳的模型或者在同一模型中設定最佳閾值。
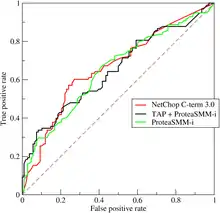
在做決策時,ROC分析能不受成本/效益的影響,給出客觀中立的建議。
ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来偵测战场上的敌军載具(飛機、船艦),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。數十年來,ROC分析被用於医学、无线电、生物學、犯罪心理學领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。
基本概念
|
| Source: Fawcett (2006). |

分类模型(又稱分类器,或診斷)是将一个实例映射到一个特定类的过程。ROC分析的是二元分類模型,也就是輸出結果只有兩種類別的模型,例如:(陽性/陰性)(有病/沒病)(垃圾郵件/非垃圾郵件)(敵軍/非敵軍)。
當訊號偵測(或變數測量)的结果是一個連續值時,類與類的邊界必须用一个阈值(英語:)來界定。举例来说,用血压值来检测一个人是否有高血压,測出的血壓值是連續的實數(從0~200都有可能),以收縮壓140/舒張壓90為閾值,閾值以上便診斷為有高血壓,閾值未滿者診斷為無高血壓。二元分類模型的個案預測有四種結局:
- 真陽性(TP):診斷為有,實際上也有高血壓。
- 偽阳性(FP):診斷為有,实际卻没有高血壓。
- 真陰性(TN):診斷為沒有,實際上也沒有高血壓。
- 偽阴性(FN):診斷為沒有,实际却有高血壓。
這四種結局可以畫成2 × 2的混淆矩阵:
| 真实值 | 總 數 | |||
|---|---|---|---|---|
| p | n | |||
| 预 测 输 出 |
p' | 真阳性 (TP) | 偽阳性 (FP) | P' |
| n' | 偽阴性 (FN) | 真阴性 (TN) | N' | |
| 總數 | P | N | ||
ROC空間
ROC空间将偽陽性率(FPR)定義為 X 軸,真陽性率(TPR)定义为 Y 轴。
- TPR:在所有實際為陽性的樣本中,被正確地判斷為陽性之比率。

- FPR:在所有實際為阴性的样本中,被錯誤地判斷為陽性之比率。

給定一個二元分類模型和它的閾值,就能從所有樣本的(陽性/陰性)真實值和預測值計算出一個 (X=FPR, Y=TPR) 座標點。 在这条线的以上的点代表了一个好的分类结果(勝過隨機分類),而在这条线以下的点代表了差的分类结果(劣於隨機分類)。
完美的預測是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有偽阳性,Y=1 代表著沒有偽阴性(所有的陽性都是真陽性);也就是說,不管分類器輸出結果是陽性或陰性,都是100%正確。一个随机的预测会得到位於从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
让我们来看在實際有100个阳性和100个阴性的案例時,四種預測方法(可能是四種分類器,或是同一分類器的四種閾值設定)的結果差異:
| A | B | C | C' | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
| ||||||||||||||||||||||||||||||||||||
| TPR = 0.63 | TPR = 0.77 | TPR = 0.24 | TPR = 0.76 | ||||||||||||||||||||||||||||||||||||
| FPR = 0.28 | FPR = 0.77 | FPR = 0.88 | FPR = 0.12 | ||||||||||||||||||||||||||||||||||||
| ACC = 0.675 | ACC = 0.500 | ACC = 0.180 | ACC = 0.820 |
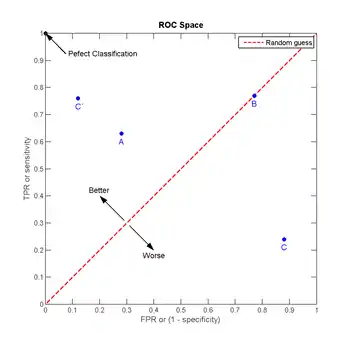
將這4種结果畫在ROC空间裡:
- 點與随机猜测线的距離,是預測力的指標:离左上角越近的點預測(診斷)準確率越高。離右下角越近的點,预测越不準。
- 在A、B、C三者當中,最好的結果是A方法。
- B方法的结果位於随机猜测线(對角線)上,在例子中我们可以看到B的準確度(ACC,定義見前面表格)是50%。
- C雖然預測準確度最差,甚至劣於隨機分類,也就是低於0.5(低於對角線)。然而,当将C以 (0.5, 0.5) 為中點作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单說,不管C(或任何ROC點低於對角線的情況)预测了什么,就做相反的結論。
ROC曲線
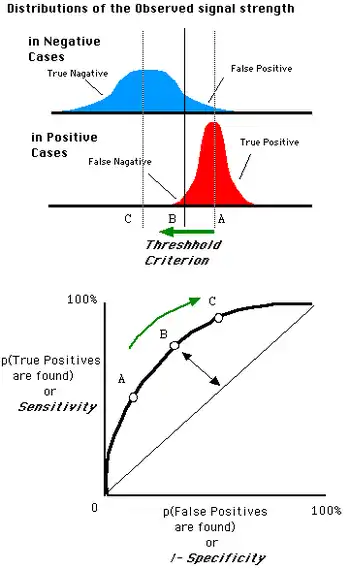
上述ROC空間裡的單點,是給定分類模型且給定閾值後得出的。但同一個二元分類模型的閾值可能設定為高或低,每種閾值的設定會得出不同的FPR和TPR。
- 將同一模型每個閾值 的 (FPR, TPR) 座標都畫在ROC空間裡,就成為特定模型的ROC曲線。
例如右圖,人體的血液蛋白濃度是呈正态分布的連續變數,病人的分布是紅色,平均值為A g/dL,健康人的分布是藍色,平均值是C g/dL。健康檢查會測量血液樣本中的某種蛋白質濃度,達到某個值(閾值,threshold)以上診斷為有疾病徵兆。研究者可以調整閾值的高低(將左上圖的B垂直線往左或右移動),便會得出不同的偽陽性率與真陽性率,總之即得出不同的預測準確率。
1. 由於每個不同的分類器(診斷工具、偵測工具)有各自的測量標準和測量值的單位(標示為:「健康人-病人分佈圖」的橫軸),所以不同分類器的「健康人-病人分佈圖」都長得不一樣。
2. 比較不同分類器時,ROC曲線的實際形狀,便視兩個實際分佈的重疊範圍而定,沒有規律可循。
3. 但在同一個分類器之內,閾值的不同設定對ROC曲線的影響,仍有一些規律可循:
- 當閾值設定為最高時,亦即所有樣本都被預測為陰性,沒有樣本被預測為陽性,此時在偽陽性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同時在真陽性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%
- → 當閾值設定為最高時,必得出ROC座標系左下角的點 (0, 0)。
- 當閾值設定為最低時,亦即所有樣本都被預測為陽性,沒有樣本被預測為陰性,此時在偽陽性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同時在真陽性率 TPR = TP / ( TP + FN ) 算式中的 FN = 0,所以 TPR=100%
- → 當閾值設定為最低時,必得出ROC座標系右上角的點 (1, 1)。
- 因為TP、FP、TN、FN都是累積次數,TN和FN隨著閾值調低而減少(或持平),TP和FP隨著閾值調低而增加(或持平),所以FPR和TPR皆必隨著閾值調低而增加(或持平)。
- → 隨著閾值調低,ROC點 往右上(或右/或上)移動,或不動;但絕不會往左下(或左/或下)移動。
曲線下面積(AUC)

在比較不同的分類模型時,可以將每個模型的ROC曲線都畫出來,比較曲線下面積做為模型優劣的指標。
意義
ROC曲線下方的面積(英語:),其意義是:
- 因為是在1x1的方格裡求面積,AUC必在0~1之間。
- 假設閾值以上是陽性,以下是陰性;
- 若隨機抽取一個陽性樣本和一個陰性樣本,分類器正確判斷陽性樣本的值高於陰性樣本之機率 [1]。
- 簡單說:AUC值越大的分類器,正確率越高。

從AUC判斷分類器(預測模型)優劣的標準:
- AUC = 1,是完美分類器,採用這個預測模型時,存在至少一個閾值能得出完美預測。絕大多數預測的場合,不存在完美分類器。
- 0.5 < AUC < 1,優於隨機猜測。這個分類器(模型)妥善設定閾值的話,能有預測價值。
- AUC = 0.5,跟隨機猜測一樣(例:丟銅板),模型沒有預測價值。
- AUC < 0.5,比隨機猜測還差;但只要總是反預測而行,就優於隨機猜測。
計算
AUC的計算有兩種方式,都是以逼近法求近似值。
梯形法
梯形法(英語:):簡單地將每個相鄰的點以直線連接,計算連線下方的總面積。因為每一線段下方都是一個梯形,所以叫梯形法。
- 優點:簡單,所以常用。
- 缺點:傾向於低估AUC。
分析軟體
所有常用於統計分析的軟體(例:SPSS、SAS、SYSTAT、S-Plus、ROCKIT、RscorePlus)都有依據不同閾值自動計算真陽性和偽陽性比率、並依此繪製ROC曲線的功能。
离散分类器(英語:,或稱「間斷分類器」),如决策树,产生的是离散的数值或者一个二元标签。应用到实例中,这样的分类器最后只会在ROC空间产生单一的点。而一些其他的分类器,如朴素贝叶斯分类器,邏輯斯諦迴歸或者人工神经网络,产生的是实例属于某一类的可能性,对于这些方法,一个阈值就决定了ROC空间中点的位置。举例来说,如果可能值低于或者等于0.8这个阈值就将其认为是阳性的类,而其他的值被认为是阴性类。这样就可以通过画每一个阈值的ROC点来生成一个生成一条曲线。MedCalc是较好的ROC曲线分析软件。
参考文献
引用
- Fawcett, Tom (2006); An introduction to ROC analysis, Pattern Recognition Letters, 27, 861–874.
- Hanley, James A.; McNeil, Barbara J. . Radiology. 1983-09-01, 148 (3): 839–843 [2008-12-03]. PMID 6878708. (原始内容存档于2008-09-05).
- Hanczar, Blaise; Hua, Jianping; Sima, Chao; Weinstein, John; Bittner, Michael; and Dougherty, Edward R. (2010); Small-sample precision of ROC-related estimates, Bioinformatics 26 (6): 822–830
- Lobo, Jorge M.; Jiménez-Valverde, Alberto; and Real, Raimundo (2008), AUC: a misleading measure of the performance of predictive distribution models, Global Ecology and Biogeography, 17: 145–151
- Hand, David J. (2009); Measuring classifier performance: A coherent alternative to the area under the ROC curve, Machine Learning, 77: 103–123
来源
- Zou, K.H., O'Malley, A.J., Mauri, L. (2007). Receiver-operating characteristic analysis for evaluating diagnostic tests and predictive models. Circulation, 6;115(5):654–7.
- X. H., Zhou. . Wiley & Sons. 2002. ISBN 9780471347729.
- Lasko, T.A., J.G. Bhagwat, K.H. Zou and Ohno-Machado, L. (2005). The use of receiver operating characteristic curves in biomedical informatics. Journal of Biomedical Informatics, 38(5):404–415.
- Balakrishnan, N., (1991) Handbook of the Logistic Distribution, Marcel Dekker, Inc., ISBN 978-0824785871.
- Gonen M., (2007) Analyzing Receiver Operating Characteristic Curves Using SAS, SAS Press, ISBN 978-1-59994-298-1.
- Green, W.H., (2003) Econometric Analysis, fifth edition, Prentice Hall, ISBN 0-13-066189-9.
- Heagerty, P.J., Lumley, T., Pepe, M. S. (2000) Time-dependent ROC Curves for Censored Survival Data and a Diagnostic Marker Biometrics, 56:337–344
- Hosmer, D.W. and Lemeshow, S., (2000) Applied Logistic Regression, 2nd ed., New York; Chichester, Wiley, ISBN 0-471-35632-8.
- Brown, C.D., and Davis, H.T. (2006) Receiver operating characteristic curves and related decision measures: a tutorial, Chemometrics and Intelligent Laboratory Systems, 80:24–38
- Mason, S.J. and Graham, N.E. (2002) Areas beneath the relative operating characteristics (ROC) and relative operating levels (ROL) curves: Statistical significance and interpretation. Q.J.R. Meteorol. Soc., 128:2145–2166.
- Pepe, M.S. (2003). The statistical evaluation of medical tests for classification and prediction. Oxford. ISBN 0198565828.
- Carsten, S. Wesseling, S., Schink, T., and Jung, K. (2003) Comparison of Eight Computer Programs for Receiver-Operating Characteristic Analysis. Clinical Chemistry, 49:433–439
- Swets, J.A. (1995). Signal detection theory and ROC analysis in psychology and diagnostics: Collected papers. Lawrence Erlbaum Associates.
- Swets, J.A., Dawes, R., and Monahan, J. (2000) Better Decisions through Science. Scientific American, October, pages 82–87.
外部链接
- An introduction to ROC analysis
- A more thorough treatment of ROC curves and signal detection theory
- Tom Fawcett's ROC Convex Hull: tutorial, program and papers(页面存档备份,存于)
- Peter Flach's tutorial on ROC analysis in machine learning
- The magnificent ROC(页面存档备份,存于) — An explanation and interactive demonstration of the connection of ROCs to archetypal bi-normal test result plots