In coding theory, folded Reed–Solomon codes are like Reed–Solomon codes, which are obtained by mapping Reed–Solomon codewords over a larger alphabet by careful bundling of codeword symbols.

Folded Reed–Solomon codes are also a special case of Parvaresh–Vardy codes.
Using optimal parameters one can decode with a rate of R, and achieve a decoding radius of 1 − R.
The term "folded Reed–Solomon codes" was coined in a paper by V.Y. Krachkovsky with an algorithm that presented Reed–Solomon codes with many random "phased burst" errors.[1] The list-decoding algorithm for folded RS codes corrects beyond the bound for Reed–Solomon codes achieved by the Guruswami–Sudan algorithm for such phased burst errors.

History
One of the ongoing challenges in Coding Theory is to have error correcting codes achieve an optimal trade-off between (Coding) Rate and Error-Correction Radius. Though this may not be possible to achieve practically (due to Noisy Channel Coding Theory issues), quasi optimal tradeoffs can be achieved theoretically.
Prior to Folded Reed–Solomon codes being devised, the best Error-Correction Radius achieved was , by Reed–Solomon codes for all rates .

An improvement upon this bound was achieved by Parvaresh and Vardy for rates

For the Parvaresh–Vardy algorithm can decode a fraction of errors.


Folded Reed–Solomon Codes improve on these previous constructions, and can be list decoded in polynomial time for a fraction of errors for any constant .


Definition

Consider a Reed–Solomon code of length and dimension and a folding parameter . Assume that divides .
![[n=q-1,k]_q](../I/04e6d237b3fa76c64bcbcf0e24945eac5c9e2330.svg)



Mapping for Reed–Solomon codes like this:

where is a primitive element in

- .

The folded version of Reed Solomon code , denoted is a code of block length over . are just Reed Solomon codes with consecutive symbols from RS codewords grouped together.




![[q-1,k]](../I/9690daaac77418faa4815cbf39b78069a1d48cf2.svg)
Graphic description

The above definition is made more clear by means of the diagram with , where is the folding parameter.

The message is denoted by , which when encoded using Reed–Solomon encoding, consists of values of at , where .




Then bundling is performed in groups of 3 elements, to give a codeword of length over the alphabet .


Something to be observed here is that the folding operation demonstrated does not change the rate of the original Reed–Solomon code.
To prove this, consider a linear code, of length , dimension and distance . The folding operation will make it a code. By this, the rate will be the same.
![[n, k, d]_q](../I/5eef76e1d6b74cc535236a6249e75afeea540ee3.svg)

![{\displaystyle \left[{\tfrac {n}{m}},{\tfrac {k}{m}},{\tfrac {d}{m}}\right]_{q^{m}}}](../I/37a190c29babbd81c295223862d1a0e7eb8dffd3.svg)

Folded Reed–Solomon codes and the singleton bound
According to the asymptotic version of the singleton bound, it is known that the relative distance , of a code must satisfy where is the rate of the code. As proved earlier, since the rate is maintained, the relative distance also meets the Singleton bound.



Why folding might help?
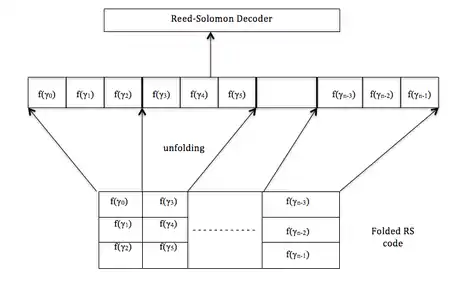
Folded Reed–Solomon codes are basically the same as Reed Solomon codes, just viewed over a larger alphabet. To show how this might help, consider a folded Reed–Solomon code with . Decoding a Reed–Solomon code and folded Reed–Solomon code for the same fraction of errors are tasks of almost the same computational intensity: one can unfold the received word of the folded Reed–Solomon code, treat it as a received word of the original Reed–Solomon code, and run the Reed–Solomon list decoding algorithm on it. Obviously, this list will contain all the folded Reed–Solomon codewords within distance of the received word, along with some extras, which we can expurgate.

Also, decoding a folded Reed–Solomon code is an easier task. Suppose we want to correct a third of the errors. The decoding algorithm chosen must correct an error pattern that corrects every third symbol in the Reed–Solomon encoding. But after folding, this error pattern will corrupt all symbols over and will eliminate the need for error correction. This propagation of errors is indicated by the blue color in the graphical description. This proves that for a fixed fraction of errors the folding operation reduces the channel's flexibility to distribute errors, which in turn leads to a reduction in the number of error patterns that need to be corrected.

How folded Reed–Solomon (FRS) codes and Parvaresh Vardy (PV) codes are related
We can relate Folded Reed Solomon codes with Parvaresh Vardy codes which encodes a polynomial of degree with polynomials where where is an irreducible polynomial. While choosing irreducible polynomial and parameter we should check if every polynomial of degree at most satisfies since is just the shifted counterpart of where is the primitive element in Thus folded RS code with bundling together code symbols is PV code of order for the set of evaluation points









- .

If we compare the folded RS code to a PV code of order 2 for the set of evaluation points

we can see that in PV encoding of , for every and every appears at and ,





unlike in the folded FRS encoding in which it appears only once. Thus, the PV and folded RS codes have same information but only the rate of FRS is bigger by a factor of and hence the list decoding radius trade-off is better for folded RS code by just using the list decodability of the PV codes. The plus point is in choosing FRS code in a way that they are compressed forms of suitable PV code with similar error correction performance with better rate than corresponding PV code. One can use this idea to construct a folded RS codes of rate that are list decodable up to radius approximately for .

![1-R^{s/[s+1]}](../I/1c6815573e1a6531746b660f119638c35c15e1a5.svg)

Brief overview of list-decoding folded Reed–Solomon codes
A list decoding algorithm which runs in quadratic time to decode FRS code up to radius is presented by Guruswami. The algorithm essentially has three steps namely the interpolation step in which welch berlekamp style interpolation is used to interpolate the non-zero polynomial


after which all the polynomials with degree satisfying the equation derived in interpolation are found. In the third step the actual list of close-by codewords are known by pruning the solution subspace which takes time.
![{\displaystyle f\in \mathbb {F} _{q}[X]}](../I/1e9fef99ccb5bce50c8851d0ea6c86710e19e8b3.svg)


Linear-algebraic list decoding algorithm
Guruswami presents a time list decoding algorithm based on linear-algebra, which can decode folded Reed–Solomon code up to radius with a list-size of . There are three steps in this algorithm: Interpolation Step, Root Finding Step and Prune Step. In the Interpolation step it will try to find the candidate message polynomial by solving a linear system. In the Root Finding step, it will try to find the solution subspace by solving another linear system. The last step will try to prune the solution subspace gained in the second step. We will introduce each step in details in the following.



Step 1: The interpolation step
It is a Welch–Berlekamp-style interpolation (because it can be viewed as the higher-dimensional generalization of the Welch–Berlekamp algorithm). Suppose we received a codeword of the -folded Reed–Solomon code as shown below


We interpolate the nonzero polynomial

by using a carefully chosen degree parameter .


So the interpolation requirements will be

Then the number of monomials in is


Because the number of monomials in is greater than the number of interpolation conditions. We have below lemma
- Lemma 1. satisfying the above interpolation condition can be found by solving a homogeneous linear system over with at most constraints and variables. Moreover this interpolation can be performed in operations over .[2]
![{\displaystyle 0\neq Q\in \mathbb {F} _{q}[X,Y_{1},\ldots ,Y_{s}]}](../I/ede638820cda00998d6afa1474e0df34f72fd79f.svg)



This lemma shows us that the interpolation step can be done in near-linear time.
For now, we have talked about everything we need for the multivariate polynomial . The remaining task is to focus on the message polynomials .
- Lemma 2. If a candidate message polynomial is a polynomial of degree at most whose Folded Reed-Solomon encoding agrees with the received word in at least columns with
- then [3]
![f(X) \in \mathbb{F}[X]](../I/871c65bfc22a134400442f8dec90c20c5fe5761f.svg)



Here "agree" means that all the values in a column should match the corresponding values in codeword .
This lemma shows us that any such polynomial presents an algebraic condition that must be satisfied for those message polynomials that we are interested in list decoding.
Combining Lemma 2 and parameter , we have

Further we can get the decoding bound

We notice that the fractional agreement is

Step 2: The root-finding step
During this step, our task focus on how to find all polynomials with degree no more than and satisfy the equation we get from Step 1, namely
![f\in{\mathbb{F}_q[X]}](../I/c1b56e990a045456f6eb05243c09a271e96560ff.svg)

Since the above equation forms a linear system equations over in the coefficients of the polynomial


the solutions to the above equation is an affine subspace of . This fact is the key point that gives rise to an efficient algorithm - we can solve the linear system.

It is natural to ask how large is the dimension of the solution? Is there any upper bound on the dimension? Having an upper bound is very important in constructing an efficient list decoding algorithm because one can simply output all the codewords for any given decoding problem.
Actually it indeed has an upper bound as below lemma argues.
- Lemma 3. If the order of is at least (in particular when is primitive), then the dimension of the solution is at most .[4]

This lemma shows us the upper bound of the dimension for the solution space.
Finally, based on the above analysis, we have below theorem
- Theorem 1. For the folded Reed–Solomon code of block length and rate the following holds for all integers . Given a received word , in time, one can find a basis for a subspace of dimension at most that contains all message polynomials of degree less than whose FRS encoding differs from in at most a fraction
- of the codeword positions.
![FRS^{(m)}_q[n,k]](../I/7d758861ffff233ed613acf4a375c79a06103b90.svg)







When , we notice that this reduces to a unique decoding algorithm with up to a fraction of errors. In other words, we can treat unique decoding algorithm as a specialty of list decoding algorithm. The quantity is about for the parameter choices that achieve a list decoding radius of .



Theorem 1 tells us exactly how large the error radius would be.
Now we finally get the solution subspace. However, there is still one problem standing. The list size in the worst case is . But the actual list of close-by codewords is only a small set within that subspace. So we need some process to prune the subspace to narrow it down. This prune process takes time in the worst case. Unfortunately it is not known how to improve the running time because we do not know how to improve the bound of the list size for folded Reed-Solomon code.

Things get better if we change the code by carefully choosing a subset of all possible degree polynomials as messages, the list size shows to be much smaller while only losing a little bit in the rate. We will talk about this briefly in next step.
Step 3: The prune step
By converting the problem of decoding a folded Reed–Solomon code into two linear systems, one linear system that is used for the interpolation step and another linear system to find the candidate solution subspace, the complexity of the decoding problem is successfully reduced to quadratic. However, in the worst case, the bound of list size of the output is pretty bad.
It was mentioned in Step 2 that if one carefully chooses only a subset of all possible degree polynomials as messages, the list size can be much reduced. Here we will expand our discussion.
To achieve this goal, the idea is to limit the coefficient vector to a special subset , which satisfies below two conditions:


- Condition 1. The set must be large enough ().


This is to make sure that the rate will be at most reduced by factor of .

- Condition 2. The set should have low intersection with any subspace of dimension satisfying and Such a subset is called subspace-evasive subset.




The bound for the list size at worst case is , and it can be reduced to a relative small bound by using subspace-evasive subsets.

During this step, as it has to check each element of the solution subspace that we get from Step 2, it takes time in the worst case ( is the dimension of the solution subspace).
Dvir and Lovett improved the result based on the work of Guruswami, which can reduce the list size to a constant.
Here is only presented the idea that is used to prune the solution subspace. For the details of the prune process, please refer to papers by Guruswami, Dvir and Lovett, which are listed in the reference.
Summary
If we don't consider the Step 3, this algorithm can run in quadratic time. A summary for this algorithm is listed below.
| Steps |
|
|---|---|
| Runtime | |
| Error radius | |
| List size |

See also
References
- ↑ Krachkovsky, V.Y. (November 2003). "Reed-Solomon codes for correcting phased error bursts". IEEE Transactions on Information Theory. 49 (11): 2975–84. doi:10.1109/TIT.2003.819333.
- ↑ Brander 2010, Proposition 5.11
- ↑ Guruswami 2011
- ↑ Guruswami 2011
- Atri Rudra's Lecture Notes: Folded Reed–Solomon Codes
- Atri Rudra's Lecture Notes: Bounds
- Guruswami, V.; Rudra, A. (May 2006). "Explicit capacity-achieving list-decodable codes or decoding Folded Reed-Solomon Codes up to their distance". Proceedings of the thirty-eighth annual ACM symposium on Theory of Computing. pp. 1–10. doi:10.1145/1132516.1132518. ISBN 1595931341.
- Rudra, Atri (2007). "3. List Decoding of Folded Reed-Solomon Codes" (PDF). List Decoding and Property Testing of Error Correcting Codes (PhD). University of Washington. pp. 29–51.
- Venkatesan Guruswami's lecture notes: Elementary bounds on codes
- Venkatesan Guruswami's lecture notes: List Decoding Folded Reed–Solomon Code
- Guruswami, Venkatesan (2011). "Linear-Algebraic List Decoding of Folded Reed-Solomon Codes". 2011 IEEE 26th Annual Conference on Computational Complexity. pp. 77–85. arXiv:1106.0436. Bibcode:2011arXiv1106.0436G. doi:10.1109/CCC.2011.22. ISBN 978-1-4577-0179-5. S2CID 12067714.
- Dvirl, Zeev; Lovett, Shachar (2011). "Subspace evasive sets". arXiv:1110.5696 [cs.CC].
- Brander, K. (2010). Interpolation and list decoding of algebraic codes (PDF) (PhD). Technical University of Denmark.
- Krachkovsky, V. Y. (2003). "Reed–Solomon codes for correcting phased error bursts". IEEE Trans. Inf. Theory. 49 (11): 2975–84. doi:10.1109/TIT.2003.819333.