| Reed–Solomon codes | |
|---|---|
| Named after | Irving S. Reed and Gustave Solomon |
| Classification | |
| Hierarchy | Linear block code Polynomial code Reed–Solomon code |
| Block length | n |
| Message length | k |
| Distance | n − k + 1 |
| Alphabet size | q = pm ≥ n (p prime) Often n = q − 1. |
| Notation | [n, k, n − k + 1]q-code |
| Algorithms | |
| Berlekamp–Massey Euclidean et al. | |
| Properties | |
| Maximum-distance separable code | |
Reed–Solomon codes are a group of error-correcting codes that were introduced by Irving S. Reed and Gustave Solomon in 1960.[1] They have many applications, the most prominent of which include consumer technologies such as MiniDiscs, CDs, DVDs, Blu-ray discs, QR codes, data transmission technologies such as DSL and WiMAX, broadcast systems such as satellite communications, DVB and ATSC, and storage systems such as RAID 6.
Reed–Solomon codes operate on a block of data treated as a set of finite-field elements called symbols. Reed–Solomon codes are able to detect and correct multiple symbol errors. By adding t = n − k check symbols to the data, a Reed–Solomon code can detect (but not correct) any combination of up to t erroneous symbols, or locate and correct up to ⌊t/2⌋ erroneous symbols at unknown locations. As an erasure code, it can correct up to t erasures at locations that are known and provided to the algorithm, or it can detect and correct combinations of errors and erasures. Reed–Solomon codes are also suitable as multiple-burst bit-error correcting codes, since a sequence of b + 1 consecutive bit errors can affect at most two symbols of size b. The choice of t is up to the designer of the code and may be selected within wide limits.
There are two basic types of Reed–Solomon codes – original view and BCH view – with BCH view being the most common, as BCH view decoders are faster and require less working storage than original view decoders.
History
Reed–Solomon codes were developed in 1960 by Irving S. Reed and Gustave Solomon, who were then staff members of MIT Lincoln Laboratory. Their seminal article was titled "Polynomial Codes over Certain Finite Fields". (Reed & Solomon 1960). The original encoding scheme described in the Reed & Solomon article used a variable polynomial based on the message to be encoded where only a fixed set of values (evaluation points) to be encoded are known to encoder and decoder. The original theoretical decoder generated potential polynomials based on subsets of k (unencoded message length) out of n (encoded message length) values of a received message, choosing the most popular polynomial as the correct one, which was impractical for all but the simplest of cases. This was initially resolved by changing the original scheme to a BCH code like scheme based on a fixed polynomial known to both encoder and decoder, but later, practical decoders based on the original scheme were developed, although slower than the BCH schemes. The result of this is that there are two main types of Reed Solomon codes, ones that use the original encoding scheme, and ones that use the BCH encoding scheme.
Also in 1960, a practical fixed polynomial decoder for BCH codes developed by Daniel Gorenstein and Neal Zierler was described in an MIT Lincoln Laboratory report by Zierler in January 1960 and later in a paper in June 1961.[2] The Gorenstein–Zierler decoder and the related work on BCH codes are described in a book Error Correcting Codes by W. Wesley Peterson (1961).[3] By 1963 (or possibly earlier), J. J. Stone (and others) recognized that Reed Solomon codes could use the BCH scheme of using a fixed generator polynomial, making such codes a special class of BCH codes,[4] but Reed Solomon codes based on the original encoding scheme, are not a class of BCH codes, and depending on the set of evaluation points, they are not even cyclic codes.
In 1969, an improved BCH scheme decoder was developed by Elwyn Berlekamp and James Massey, and has since been known as the Berlekamp–Massey decoding algorithm.
In 1975, another improved BCH scheme decoder was developed by Yasuo Sugiyama, based on the extended Euclidean algorithm.[5]

In 1977, Reed–Solomon codes were implemented in the Voyager program in the form of concatenated error correction codes. The first commercial application in mass-produced consumer products appeared in 1982 with the compact disc, where two interleaved Reed–Solomon codes are used. Today, Reed–Solomon codes are widely implemented in digital storage devices and digital communication standards, though they are being slowly replaced by Bose–Chaudhuri–Hocquenghem (BCH) codes. For example, Reed–Solomon codes are used in the Digital Video Broadcasting (DVB) standard DVB-S, in conjunction with a convolutional inner code, but BCH codes are used with LDPC in its successor, DVB-S2.
In 1986, an original scheme decoder known as the Berlekamp–Welch algorithm was developed.
In 1996, variations of original scheme decoders called list decoders or soft decoders were developed by Madhu Sudan and others, and work continues on these types of decoders – see Guruswami–Sudan list decoding algorithm.
In 2002, another original scheme decoder was developed by Shuhong Gao, based on the extended Euclidean algorithm.[6]
Applications
Data storage
Reed–Solomon coding is very widely used in mass storage systems to correct the burst errors associated with media defects.
Reed–Solomon coding is a key component of the compact disc. It was the first use of strong error correction coding in a mass-produced consumer product, and DAT and DVD use similar schemes. In the CD, two layers of Reed–Solomon coding separated by a 28-way convolutional interleaver yields a scheme called Cross-Interleaved Reed–Solomon Coding (CIRC). The first element of a CIRC decoder is a relatively weak inner (32,28) Reed–Solomon code, shortened from a (255,251) code with 8-bit symbols. This code can correct up to 2 byte errors per 32-byte block. More importantly, it flags as erasures any uncorrectable blocks, i.e., blocks with more than 2 byte errors. The decoded 28-byte blocks, with erasure indications, are then spread by the deinterleaver to different blocks of the (28,24) outer code. Thanks to the deinterleaving, an erased 28-byte block from the inner code becomes a single erased byte in each of 28 outer code blocks. The outer code easily corrects this, since it can handle up to 4 such erasures per block.
The result is a CIRC that can completely correct error bursts up to 4000 bits, or about 2.5 mm on the disc surface. This code is so strong that most CD playback errors are almost certainly caused by tracking errors that cause the laser to jump track, not by uncorrectable error bursts.[7]
DVDs use a similar scheme, but with much larger blocks, a (208,192) inner code, and a (182,172) outer code.
Reed–Solomon error correction is also used in parchive files which are commonly posted accompanying multimedia files on USENET. The distributed online storage service Wuala (discontinued in 2015) also used Reed–Solomon when breaking up files.
Bar code
Almost all two-dimensional bar codes such as PDF-417, MaxiCode, Datamatrix, QR Code, and Aztec Code use Reed–Solomon error correction to allow correct reading even if a portion of the bar code is damaged. When the bar code scanner cannot recognize a bar code symbol, it will treat it as an erasure.
Reed–Solomon coding is less common in one-dimensional bar codes, but is used by the PostBar symbology.
Data transmission
Specialized forms of Reed–Solomon codes, specifically Cauchy-RS and Vandermonde-RS, can be used to overcome the unreliable nature of data transmission over erasure channels. The encoding process assumes a code of RS(N, K) which results in N codewords of length N symbols each storing K symbols of data, being generated, that are then sent over an erasure channel.
Any combination of K codewords received at the other end is enough to reconstruct all of the N codewords. The code rate is generally set to 1/2 unless the channel's erasure likelihood can be adequately modelled and is seen to be less. In conclusion, N is usually 2K, meaning that at least half of all the codewords sent must be received in order to reconstruct all of the codewords sent.
Reed–Solomon codes are also used in xDSL systems and CCSDS's Space Communications Protocol Specifications as a form of forward error correction.
Space transmission
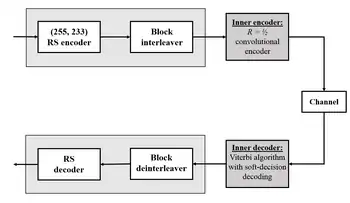
One significant application of Reed–Solomon coding was to encode the digital pictures sent back by the Voyager program.
Voyager introduced Reed–Solomon coding concatenated with convolutional codes, a practice that has since become very widespread in deep space and satellite (e.g., direct digital broadcasting) communications.
Viterbi decoders tend to produce errors in short bursts. Correcting these burst errors is a job best done by short or simplified Reed–Solomon codes.
Modern versions of concatenated Reed–Solomon/Viterbi-decoded convolutional coding were and are used on the Mars Pathfinder, Galileo, Mars Exploration Rover and Cassini missions, where they perform within about 1–1.5 dB of the ultimate limit, the Shannon capacity.
These concatenated codes are now being replaced by more powerful turbo codes:
| Years | Code | Mission(s) |
|---|---|---|
| 1958–present | Uncoded | Explorer, Mariner, many others |
| 1968–1978 | convolutional codes (CC) (25, 1/2) | Pioneer, Venus |
| 1969–1975 | Reed-Muller code (32, 6) | Mariner, Viking |
| 1977–present | Binary Golay code | Voyager |
| 1977–present | RS(255, 223) + CC(7, 1/2) | Voyager, Galileo, many others |
| 1989–2003 | RS(255, 223) + CC(7, 1/3) | Voyager |
| 1989–2003 | RS(255, 223) + CC(14, 1/4) | Galileo |
| 1996–present | RS + CC (15, 1/6) | Cassini, Mars Pathfinder, others |
| 2004–present | Turbo codes[nb 1] | Messenger, Stereo, MRO, others |
| est. 2009 | LDPC codes | Constellation, MSL |
Constructions (encoding)
The Reed–Solomon code is actually a family of codes, where every code is characterised by three parameters: an alphabet size , a block length , and a message length , with . The set of alphabet symbols is interpreted as the finite field of order , and thus, must be a prime power. In the most useful parameterizations of the Reed–Solomon code, the block length is usually some constant multiple of the message length, that is, the rate is some constant, and furthermore, the block length is equal to or one less than the alphabet size, that is, or .








Reed & Solomon's original view: The codeword as a sequence of values
There are different encoding procedures for the Reed–Solomon code, and thus, there are different ways to describe the set of all codewords. In the original view of Reed & Solomon (1960), every codeword of the Reed–Solomon code is a sequence of function values of a polynomial of degree less than . In order to obtain a codeword of the Reed–Solomon code, the message symbols (each within the q-sized alphabet) are treated as the coefficients of a polynomial of degree less than k, over the finite field with elements. In turn, the polynomial p is evaluated at n ≤ q distinct points of the field F, and the sequence of values is the corresponding codeword. Common choices for a set of evaluation points include {0, 1, 2, ..., n − 1}, {0, 1, α, α2, ..., αn−2}, or for n < q, {1, α, α2, ..., αn−1}, ... , where α is a primitive element of F.


Formally, the set of codewords of the Reed–Solomon code is defined as follows:


Since any two distinct polynomials of degree less than agree in at most points, this means that any two codewords of the Reed–Solomon code disagree in at least positions. Furthermore, there are two polynomials that do agree in points but are not equal, and thus, the distance of the Reed–Solomon code is exactly . Then the relative distance is , where is the rate. This trade-off between the relative distance and the rate is asymptotically optimal since, by the Singleton bound, every code satisfies . Being a code that achieves this optimal trade-off, the Reed–Solomon code belongs to the class of maximum distance separable codes.






While the number of different polynomials of degree less than k and the number of different messages are both equal to , and thus every message can be uniquely mapped to such a polynomial, there are different ways of doing this encoding. The original construction of Reed & Solomon (1960) interprets the message x as the coefficients of the polynomial p, whereas subsequent constructions interpret the message as the values of the polynomial at the first k points and obtain the polynomial p by interpolating these values with a polynomial of degree less than k. The latter encoding procedure, while being slightly less efficient, has the advantage that it gives rise to a systematic code, that is, the original message is always contained as a subsequence of the codeword.


Simple encoding procedure: The message as a sequence of coefficients
In the original construction of Reed & Solomon (1960), the message is mapped to the polynomial with



The codeword of is obtained by evaluating at different points of the field . Thus the classical encoding function for the Reed–Solomon code is defined as follows:




This function is a linear mapping, that is, it satisfies for the following -matrix with elements from :





This matrix is a Vandermonde matrix over . In other words, the Reed–Solomon code is a linear code, and in the classical encoding procedure, its generator matrix is .
Systematic encoding procedure: The message as an initial sequence of values
There is an alternative encoding procedure that produces a systematic Reed–Solomon code. Here, we use a different polynomial . In this variant, the polynomial is defined as the unique polynomial of degree less than such that

To compute this polynomial from , one can use Lagrange interpolation. Once it has been found, it is evaluated at the other points .

This variant is systematic since the first entries, , are exactly by the definition of .


Discrete Fourier transform and its inverse
A discrete Fourier transform is essentially the same as the encoding procedure; it uses the generator polynomial to map a set of evaluation points into the message values as shown above:
The inverse Fourier transform could be used to convert an error free set of n < q message values back into the encoding polynomial of k coefficients, with the constraint that in order for this to work, the set of evaluation points used to encode the message must be a set of increasing powers of α:


However, Lagrange interpolation performs the same conversion without the constraint on the set of evaluation points or the requirement of an error free set of message values and is used for systematic encoding, and in one of the steps of the Gao decoder.
The BCH view: The codeword as a sequence of coefficients
In this view, the message is interpreted as the coefficients of a polynomial . The sender computes a related polynomial of degree where and sends the polynomial . The polynomial is constructed by multiplying the message polynomial , which has degree , with a generator polynomial of degree that is known to both the sender and the receiver. The generator polynomial is defined as the polynomial whose roots are sequential powers of the Galois field primitive








For a "narrow sense code", .


Systematic encoding procedure
The encoding procedure for the BCH view of Reed–Solomon codes can be modified to yield a systematic encoding procedure, in which each codeword contains the message as a prefix, and simply appends error correcting symbols as a suffix. Here, instead of sending , the encoder constructs the transmitted polynomial such that the coefficients of the largest monomials are equal to the corresponding coefficients of , and the lower-order coefficients of are chosen exactly in such a way that becomes divisible by . Then the coefficients of are a subsequence of the coefficients of . To get a code that is overall systematic, we construct the message polynomial by interpreting the message as the sequence of its coefficients.

Formally, the construction is done by multiplying by to make room for the check symbols, dividing that product by to find the remainder, and then compensating for that remainder by subtracting it. The check symbols are created by computing the remainder :





The remainder has degree at most , whereas the coefficients of in the polynomial are zero. Therefore, the following definition of the codeword has the property that the first coefficients are identical to the coefficients of :




As a result, the codewords are indeed elements of , that is, they are divisible by the generator polynomial :[10]

Properties
The Reed–Solomon code is a [n, k, n − k + 1] code; in other words, it is a linear block code of length n (over F) with dimension k and minimum Hamming distance The Reed–Solomon code is optimal in the sense that the minimum distance has the maximum value possible for a linear code of size (n, k); this is known as the Singleton bound. Such a code is also called a maximum distance separable (MDS) code.

The error-correcting ability of a Reed–Solomon code is determined by its minimum distance, or equivalently, by , the measure of redundancy in the block. If the locations of the error symbols are not known in advance, then a Reed–Solomon code can correct up to erroneous symbols, i.e., it can correct half as many errors as there are redundant symbols added to the block. Sometimes error locations are known in advance (e.g., "side information" in demodulator signal-to-noise ratios)—these are called erasures. A Reed–Solomon code (like any MDS code) is able to correct twice as many erasures as errors, and any combination of errors and erasures can be corrected as long as the relation 2E + S ≤ n − k is satisfied, where is the number of errors and is the number of erasures in the block.



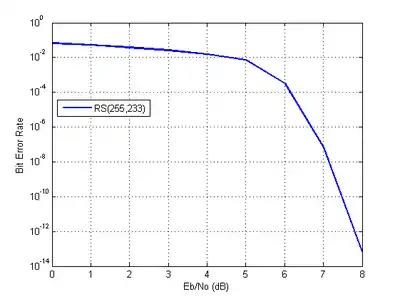
The theoretical error bound can be described via the following formula for the AWGN channel for FSK:[11]

and for other modulation schemes:

where , , , is the symbol error rate in uncoded AWGN case and is the modulation order.





For practical uses of Reed–Solomon codes, it is common to use a finite field with elements. In this case, each symbol can be represented as an -bit value. The sender sends the data points as encoded blocks, and the number of symbols in the encoded block is . Thus a Reed–Solomon code operating on 8-bit symbols has symbols per block. (This is a very popular value because of the prevalence of byte-oriented computer systems.) The number , with , of data symbols in the block is a design parameter. A commonly used code encodes eight-bit data symbols plus 32 eight-bit parity symbols in an -symbol block; this is denoted as a code, and is capable of correcting up to 16 symbol errors per block.







The Reed–Solomon code properties discussed above make them especially well-suited to applications where errors occur in bursts. This is because it does not matter to the code how many bits in a symbol are in error — if multiple bits in a symbol are corrupted it only counts as a single error. Conversely, if a data stream is not characterized by error bursts or drop-outs but by random single bit errors, a Reed–Solomon code is usually a poor choice compared to a binary code.
The Reed–Solomon code, like the convolutional code, is a transparent code. This means that if the channel symbols have been inverted somewhere along the line, the decoders will still operate. The result will be the inversion of the original data. However, the Reed–Solomon code loses its transparency when the code is shortened. The "missing" bits in a shortened code need to be filled by either zeros or ones, depending on whether the data is complemented or not. (To put it another way, if the symbols are inverted, then the zero-fill needs to be inverted to a one-fill.) For this reason it is mandatory that the sense of the data (i.e., true or complemented) be resolved before Reed–Solomon decoding.
Whether the Reed–Solomon code is cyclic or not depends on subtle details of the construction. In the original view of Reed and Solomon, where the codewords are the values of a polynomial, one can choose the sequence of evaluation points in such a way as to make the code cyclic. In particular, if is a primitive root of the field , then by definition all non-zero elements of take the form for , where . Each polynomial over gives rise to a codeword . Since the function is also a polynomial of the same degree, this function gives rise to a codeword ; since holds, this codeword is the cyclic left-shift of the original codeword derived from . So choosing a sequence of primitive root powers as the evaluation points makes the original view Reed–Solomon code cyclic. Reed–Solomon codes in the BCH view are always cyclic because BCH codes are cyclic.







Remarks
Designers are not required to use the "natural" sizes of Reed–Solomon code blocks. A technique known as "shortening" can produce a smaller code of any desired size from a larger code. For example, the widely used (255,223) code can be converted to a (160,128) code by padding the unused portion of the source block with 95 binary zeroes and not transmitting them. At the decoder, the same portion of the block is loaded locally with binary zeroes. The Delsarte–Goethals–Seidel[12] theorem illustrates an example of an application of shortened Reed–Solomon codes. In parallel to shortening, a technique known as puncturing allows omitting some of the encoded parity symbols.
BCH view decoders
The decoders described in this section use the BCH view of a codeword as a sequence of coefficients. They use a fixed generator polynomial known to both encoder and decoder.
Peterson–Gorenstein–Zierler decoder
Daniel Gorenstein and Neal Zierler developed a decoder that was described in a MIT Lincoln Laboratory report by Zierler in January 1960 and later in a paper in June 1961.[13] The Gorenstein–Zierler decoder and the related work on BCH codes are described in a book Error Correcting Codes by W. Wesley Peterson (1961).[14]
Formulation
The transmitted message, , is viewed as the coefficients of a polynomial s(x):


As a result of the Reed-Solomon encoding procedure, s(x) is divisible by the generator polynomial g(x):

where α is a primitive element.
Since s(x) is a multiple of the generator g(x), it follows that it "inherits" all its roots.

Therefore,

The transmitted polynomial is corrupted in transit by an error polynomial e(x) to produce the received polynomial r(x).


Coefficient ei will be zero if there is no error at that power of x and nonzero if there is an error. If there are ν errors at distinct powers ik of x, then

The goal of the decoder is to find the number of errors (ν), the positions of the errors (ik), and the error values at those positions (eik). From those, e(x) can be calculated and subtracted from r(x) to get the originally sent message s(x).
Syndrome decoding
The decoder starts by evaluating the polynomial as received at points . We call the results of that evaluation the "syndromes", Sj. They are defined as:


Note that because has roots at , as shown in the previous section.


The advantage of looking at the syndromes is that the message polynomial drops out. In other words, the syndromes only relate to the error, and are unaffected by the actual contents of the message being transmitted. If the syndromes are all zero, the algorithm stops here and reports that the message was not corrupted in transit.
Error locators and error values
For convenience, define the error locators Xk and error values Yk as:

Then the syndromes can be written in terms of these error locators and error values as

This definition of the syndrome values is equivalent to the previous since .

The syndromes give a system of n − k ≥ 2ν equations in 2ν unknowns, but that system of equations is nonlinear in the Xk and does not have an obvious solution. However, if the Xk were known (see below), then the syndrome equations provide a linear system of equations that can easily be solved for the Yk error values.

Consequently, the problem is finding the Xk, because then the leftmost matrix would be known, and both sides of the equation could be multiplied by its inverse, yielding Yk
In the variant of this algorithm where the locations of the errors are already known (when it is being used as an erasure code), this is the end. The error locations (Xk) are already known by some other method (for example, in an FM transmission, the sections where the bitstream was unclear or overcome with interference are probabilistically determinable from frequency analysis). In this scenario, up to errors can be corrected.
The rest of the algorithm serves to locate the errors, and will require syndrome values up to , instead of just the used thus far. This is why twice as many error correcting symbols need to be added as can be corrected without knowing their locations.


Error locator polynomial
There is a linear recurrence relation that gives rise to a system of linear equations. Solving those equations identifies those error locations Xk.
Define the error locator polynomial Λ(x) as

The zeros of Λ(x) are the reciprocals . This follows from the above product notation construction since if then one of the multiplied terms will be zero , making the whole polynomial evaluate to zero.




Let be any integer such that . Multiply both sides by and it will still be zero.



![{\displaystyle {\begin{aligned}&Y_{k}X_{k}^{j+\nu }\Lambda (X_{k}^{-1})=0.\\[1ex]&Y_{k}X_{k}^{j+\nu }\left(1+\Lambda _{1}X_{k}^{-1}+\Lambda _{2}X_{k}^{-2}+\cdots +\Lambda _{\nu }X_{k}^{-\nu }\right)=0.\\[1ex]&Y_{k}X_{k}^{j+\nu }+\Lambda _{1}Y_{k}X_{k}^{j+\nu }X_{k}^{-1}+\Lambda _{2}Y_{k}X_{k}^{j+\nu }X_{k}^{-2}+\cdots +\Lambda _{\nu }Y_{k}X_{k}^{j+\nu }X_{k}^{-\nu }=0.\\[1ex]&Y_{k}X_{k}^{j+\nu }+\Lambda _{1}Y_{k}X_{k}^{j+\nu -1}+\Lambda _{2}Y_{k}X_{k}^{j+\nu -2}+\cdots +\Lambda _{\nu }Y_{k}X_{k}^{j}=0.\end{aligned}}}](../I/6573fa0f429ac4349f5da794df9c4fb7831e8cbf.svg)
Sum for k = 1 to ν and it will still be zero.

Collect each term into its own sum.

Extract the constant values of that are unaffected by the summation.


These summations are now equivalent to the syndrome values, which we know and can substitute in! This therefore reduces to

Subtracting from both sides yields


Recall that j was chosen to be any integer between 1 and v inclusive, and this equivalence is true for any and all such values. Therefore, we have v linear equations, not just one. This system of linear equations can therefore be solved for the coefficients Λi of the error location polynomial:

The above assumes the decoder knows the number of errors ν, but that number has not been determined yet. The PGZ decoder does not determine ν directly but rather searches for it by trying successive values. The decoder first assumes the largest value for a trial ν and sets up the linear system for that value. If the equations can be solved (i.e., the matrix determinant is nonzero), then that trial value is the number of errors. If the linear system cannot be solved, then the trial ν is reduced by one and the next smaller system is examined. (Gill n.d., p. 35)
Find the roots of the error locator polynomial
Use the coefficients Λi found in the last step to build the error location polynomial. The roots of the error location polynomial can be found by exhaustive search. The error locators Xk are the reciprocals of those roots. The order of coefficients of the error location polynomial can be reversed, in which case the roots of that reversed polynomial are the error locators (not their reciprocals ). Chien search is an efficient implementation of this step.

Calculate the error values
Once the error locators Xk are known, the error values can be determined. This can be done by direct solution for Yk in the error equations matrix given above, or using the Forney algorithm.
Calculate the error locations
Calculate ik by taking the log base of Xk. This is generally done using a precomputed lookup table.
Fix the errors
Finally, e(x) is generated from ik and eik and then is subtracted from r(x) to get the originally sent message s(x), with errors corrected.
Example
Consider the Reed–Solomon code defined in GF(929) with α = 3 and t = 4 (this is used in PDF417 barcodes) for a RS(7,3) code. The generator polynomial is

If the message polynomial is p(x) = 3 x2 + 2 x + 1, then a systematic codeword is encoded as follows.


Errors in transmission might cause this to be received instead.

The syndromes are calculated by evaluating r at powers of α.



Using Gaussian elimination:

The coefficients can be reversed to produce roots with positive exponents, but typically this isn't used:
with the log of the roots corresponding to the error locations (right to left, location 0 is the last term in the codeword).
To calculate the error values, apply the Forney algorithm.
Subtracting from the received polynomial r(x) reproduces the original codeword s.

Berlekamp–Massey decoder
The Berlekamp–Massey algorithm is an alternate iterative procedure for finding the error locator polynomial. During each iteration, it calculates a discrepancy based on a current instance of Λ(x) with an assumed number of errors e:

and then adjusts Λ(x) and e so that a recalculated Δ would be zero. The article Berlekamp–Massey algorithm has a detailed description of the procedure. In the following example, C(x) is used to represent Λ(x).
Example
Using the same data as the Peterson Gorenstein Zierler example above:
| n | Sn+1 | d | C | B | b | m |
|---|---|---|---|---|---|---|
| 0 | 732 | 732 | 197 x + 1 | 1 | 732 | 1 |
| 1 | 637 | 846 | 173 x + 1 | 1 | 732 | 2 |
| 2 | 762 | 412 | 634 x2 + 173 x + 1 | 173 x + 1 | 412 | 1 |
| 3 | 925 | 576 | 329 x2 + 821 x + 1 | 173 x + 1 | 412 | 2 |
The final value of C is the error locator polynomial, Λ(x).
Euclidean decoder
Another iterative method for calculating both the error locator polynomial and the error value polynomial is based on Sugiyama's adaptation of the extended Euclidean algorithm .
Define S(x), Λ(x), and Ω(x) for t syndromes and e errors:
![{\displaystyle {\begin{aligned}S(x)&=S_{t}x^{t-1}+S_{t-1}x^{t-2}+\cdots +S_{2}x+S_{1}\\[1ex]\Lambda (x)&=\Lambda _{e}x^{e}+\Lambda _{e-1}x^{e-1}+\cdots +\Lambda _{1}x+1\\[1ex]\Omega (x)&=\Omega _{e}x^{e}+\Omega _{e-1}x^{e-1}+\cdots +\Omega _{1}x+\Omega _{0}\end{aligned}}}](../I/a84cd05dee4a72d23c59b3f95c4efdf3c8703600.svg)
The key equation is:

For t = 6 and e = 3:

The middle terms are zero due to the relationship between Λ and syndromes.
The extended Euclidean algorithm can find a series of polynomials of the form
where the degree of R decreases as i increases. Once the degree of Ri(x) < t/2, then
B(x) and Q(x) don't need to be saved, so the algorithm becomes:
R−1 := xt R0 := S(x) A−1 := 0 A0 := 1 i := 0 while degree of Ri ≥ t/2 i := i + 1 Q := Ri-2 / Ri-1 Ri := Ri-2 - Q Ri-1 Ai := Ai-2 - Q Ai-1
to set low order term of Λ(x) to 1, divide Λ(x) and Ω(x) by Ai(0):
Ai(0) is the constant (low order) term of Ai.
Example
Using the same data as the Peterson–Gorenstein–Zierler example above:
| i | Ri | Ai |
|---|---|---|
| −1 | 001 x4 + 000 x3 + 000 x2 + 000 x + 000 | 000 |
| 0 | 925 x3 + 762 x2 + 637 x + 732 | 001 |
| 1 | 683 x2 + 676 x + 024 | 697 x + 396 |
| 2 | 673 x + 596 | 608 x2 + 704 x + 544 |
Decoder using discrete Fourier transform
A discrete Fourier transform can be used for decoding.[15] To avoid conflict with syndrome names, let c(x) = s(x) the encoded codeword. r(x) and e(x) are the same as above. Define C(x), E(x), and R(x) as the discrete Fourier transforms of c(x), e(x), and r(x). Since r(x) = c(x) + e(x), and since a discrete Fourier transform is a linear operator, R(x) = C(x) + E(x).
Transform r(x) to R(x) using discrete Fourier transform. Since the calculation for a discrete Fourier transform is the same as the calculation for syndromes, t coefficients of R(x) and E(x) are the same as the syndromes:

Use through as syndromes (they're the same) and generate the error locator polynomial using the methods from any of the above decoders.


Let v = number of errors. Generate E(x) using the known coefficients to , the error locator polynomial, and these formulas



Then calculate C(x) = R(x) − E(x) and take the inverse transform (polynomial interpolation) of C(x) to produce c(x).
Decoding beyond the error-correction bound
The Singleton bound states that the minimum distance d of a linear block code of size (n,k) is upper-bounded by n − k + 1. The distance d was usually understood to limit the error-correction capability to ⌊(d−1) / 2⌋. The Reed–Solomon code achieves this bound with equality, and can thus correct up to ⌊(n−k) / 2⌋ errors. However, this error-correction bound is not exact.
In 1999, Madhu Sudan and Venkatesan Guruswami at MIT published "Improved Decoding of Reed–Solomon and Algebraic-Geometry Codes" introducing an algorithm that allowed for the correction of errors beyond half the minimum distance of the code.[16] It applies to Reed–Solomon codes and more generally to algebraic geometric codes. This algorithm produces a list of codewords (it is a list-decoding algorithm) and is based on interpolation and factorization of polynomials over and its extensions.

Soft-decoding
The algebraic decoding methods described above are hard-decision methods, which means that for every symbol a hard decision is made about its value. For example, a decoder could associate with each symbol an additional value corresponding to the channel demodulator's confidence in the correctness of the symbol. The advent of LDPC and turbo codes, which employ iterated soft-decision belief propagation decoding methods to achieve error-correction performance close to the theoretical limit, has spurred interest in applying soft-decision decoding to conventional algebraic codes. In 2003, Ralf Koetter and Alexander Vardy presented a polynomial-time soft-decision algebraic list-decoding algorithm for Reed–Solomon codes, which was based upon the work by Sudan and Guruswami.[17] In 2016, Steven J. Franke and Joseph H. Taylor published a novel soft-decision decoder.[18]
MATLAB example
Encoder
Here we present a simple MATLAB implementation for an encoder.
function encoded = rsEncoder(msg, m, prim_poly, n, k)
% RSENCODER Encode message with the Reed-Solomon algorithm
% m is the number of bits per symbol
% prim_poly: Primitive polynomial p(x). Ie for DM is 301
% k is the size of the message
% n is the total size (k+redundant)
% Example: msg = uint8('Test')
% enc_msg = rsEncoder(msg, 8, 301, 12, numel(msg));
% Get the alpha
alpha = gf(2, m, prim_poly);
% Get the Reed-Solomon generating polynomial g(x)
g_x = genpoly(k, n, alpha);
% Multiply the information by X^(n-k), or just pad with zeros at the end to
% get space to add the redundant information
msg_padded = gf([msg zeros(1, n - k)], m, prim_poly);
% Get the remainder of the division of the extended message by the
% Reed-Solomon generating polynomial g(x)
[~, remainder] = deconv(msg_padded, g_x);
% Now return the message with the redundant information
encoded = msg_padded - remainder;
end
% Find the Reed-Solomon generating polynomial g(x), by the way this is the
% same as the rsgenpoly function on matlab
function g = genpoly(k, n, alpha)
g = 1;
% A multiplication on the galois field is just a convolution
for k = mod(1 : n - k, n)
g = conv(g, [1 alpha .^ (k)]);
end
end
Decoder
Now the decoding part:
function [decoded, error_pos, error_mag, g, S] = rsDecoder(encoded, m, prim_poly, n, k)
% RSDECODER Decode a Reed-Solomon encoded message
% Example:
% [dec, ~, ~, ~, ~] = rsDecoder(enc_msg, 8, 301, 12, numel(msg))
max_errors = floor((n - k) / 2);
orig_vals = encoded.x;
% Initialize the error vector
errors = zeros(1, n);
g = [];
S = [];
% Get the alpha
alpha = gf(2, m, prim_poly);
% Find the syndromes (Check if dividing the message by the generator
% polynomial the result is zero)
Synd = polyval(encoded, alpha .^ (1:n - k));
Syndromes = trim(Synd);
% If all syndromes are zeros (perfectly divisible) there are no errors
if isempty(Syndromes.x)
decoded = orig_vals(1:k);
error_pos = [];
error_mag = [];
g = [];
S = Synd;
return;
end
% Prepare for the euclidean algorithm (Used to find the error locating
% polynomials)
r0 = [1, zeros(1, 2 * max_errors)]; r0 = gf(r0, m, prim_poly); r0 = trim(r0);
size_r0 = length(r0);
r1 = Syndromes;
f0 = gf([zeros(1, size_r0 - 1) 1], m, prim_poly);
f1 = gf(zeros(1, size_r0), m, prim_poly);
g0 = f1; g1 = f0;
% Do the euclidean algorithm on the polynomials r0(x) and Syndromes(x) in
% order to find the error locating polynomial
while true
% Do a long division
[quotient, remainder] = deconv(r0, r1);
% Add some zeros
quotient = pad(quotient, length(g1));
% Find quotient*g1 and pad
c = conv(quotient, g1);
c = trim(c);
c = pad(c, length(g0));
% Update g as g0-quotient*g1
g = g0 - c;
% Check if the degree of remainder(x) is less than max_errors
if all(remainder(1:end - max_errors) == 0)
break;
end
% Update r0, r1, g0, g1 and remove leading zeros
r0 = trim(r1); r1 = trim(remainder);
g0 = g1; g1 = g;
end
% Remove leading zeros
g = trim(g);
% Find the zeros of the error polynomial on this galois field
evalPoly = polyval(g, alpha .^ (n - 1 : - 1 : 0));
error_pos = gf(find(evalPoly == 0), m);
% If no error position is found we return the received work, because
% basically is nothing that we could do and we return the received message
if isempty(error_pos)
decoded = orig_vals(1:k);
error_mag = [];
return;
end
% Prepare a linear system to solve the error polynomial and find the error
% magnitudes
size_error = length(error_pos);
Syndrome_Vals = Syndromes.x;
b(:, 1) = Syndrome_Vals(1:size_error);
for idx = 1 : size_error
e = alpha .^ (idx * (n - error_pos.x));
err = e.x;
er(idx, :) = err;
end
% Solve the linear system
error_mag = (gf(er, m, prim_poly) \ gf(b, m, prim_poly))';
% Put the error magnitude on the error vector
errors(error_pos.x) = error_mag.x;
% Bring this vector to the galois field
errors_gf = gf(errors, m, prim_poly);
% Now to fix the errors just add with the encoded code
decoded_gf = encoded(1:k) + errors_gf(1:k);
decoded = decoded_gf.x;
end
% Remove leading zeros from Galois array
function gt = trim(g)
gx = g.x;
gt = gf(gx(find(gx, 1) : end), g.m, g.prim_poly);
end
% Add leading zeros
function xpad = pad(x, k)
len = length(x);
if len < k
xpad = [zeros(1, k - len) x];
end
end
Reed Solomon original view decoders
The decoders described in this section use the Reed Solomon original view of a codeword as a sequence of polynomial values where the polynomial is based on the message to be encoded. The same set of fixed values are used by the encoder and decoder, and the decoder recovers the encoding polynomial (and optionally an error locating polynomial) from the received message.
Theoretical decoder
Reed & Solomon (1960) described a theoretical decoder that corrected errors by finding the most popular message polynomial. The decoder only knows the set of values to and which encoding method was used to generate the codeword's sequence of values. The original message, the polynomial, and any errors are unknown. A decoding procedure could use a method like Lagrange interpolation on various subsets of n codeword values taken k at a time to repeatedly produce potential polynomials, until a sufficient number of matching polynomials are produced to reasonably eliminate any errors in the received codeword. Once a polynomial is determined, then any errors in the codeword can be corrected, by recalculating the corresponding codeword values. Unfortunately, in all but the simplest of cases, there are too many subsets, so the algorithm is impractical. The number of subsets is the binomial coefficient, , and the number of subsets is infeasible for even modest codes. For a code that can correct 3 errors, the naïve theoretical decoder would examine 359 billion subsets.




Berlekamp Welch decoder
In 1986, a decoder known as the Berlekamp–Welch algorithm was developed as a decoder that is able to recover the original message polynomial as well as an error "locator" polynomial that produces zeroes for the input values that correspond to errors, with time complexity , where is the number of values in a message. The recovered polynomial is then used to recover (recalculate as needed) the original message.

Example
Using RS(7,3), GF(929), and the set of evaluation points ai = i − 1
If the message polynomial is
The codeword is
Errors in transmission might cause this to be received instead.
The key equations are:

Assume maximum number of errors: e = 2. The key equations become:


Using Gaussian elimination:

Recalculate P(x) where E(x) = 0 : {2, 3} to correct b resulting in the corrected codeword:
Gao decoder
In 2002, an improved decoder was developed by Shuhong Gao, based on the extended Euclid algorithm.[6]
Example
Using the same data as the Berlekamp Welch example above:
- Lagrange interpolation of for i = 1 to n





| i | Ri | Ai |
|---|---|---|
| −1 | 001 x7 + 908 x6 + 175 x5 + 194 x4 + 695 x3 + 094 x2 + 720 x + 000 | 000 |
| 0 | 055 x6 + 440 x5 + 497 x4 + 904 x3 + 424 x2 + 472 x + 001 | 001 |
| 1 | 702 x5 + 845 x4 + 691 x3 + 461 x2 + 327 x + 237 | 152 x + 237 |
| 2 | 266 x4 + 086 x3 + 798 x2 + 311 x + 532 | 708 x2 + 176 x + 532 |
divide Q(x) and E(x) by most significant coefficient of E(x) = 708. (Optional)
Recalculate P(x) where E(x) = 0 : {2, 3} to correct b resulting in the corrected codeword:
See also
Notes
- ↑ Authors in Andrews et al. (2007), provide simulation results which show that for the same code rate (1/6) turbo codes outperform Reed-Solomon concatenated codes up to 2 dB (bit error rate).[9]
References
- ↑ Reed & Solomon (1960)
- ↑ Gorenstein, D.; Zierler, N. (June 1961). "A class of cyclic linear error-correcting codes in p^m symbols". J. SIAM. 9 (2): 207–214. doi:10.1137/0109020. JSTOR 2098821.
- ↑ Peterson, W. Wesley (1961). Error Correcting Codes. MIT Press. OCLC 859669631.
- ↑ Peterson, W. Wesley; Weldon, E.J. (1996) [1972]. Error Correcting Codes (2nd ed.). MIT Press. ISBN 978-0-585-30709-1. OCLC 45727875.
- ↑ Sugiyama, Y.; Kasahara, M.; Hirasawa, S.; Namekawa, T. (1975). "A method for solving key equation for decoding Goppa codes". Information and Control. 27 (1): 87–99. doi:10.1016/S0019-9958(75)90090-X.
- 1 2 Gao, Shuhong (January 2002), New Algorithm For Decoding Reed-Solomon Codes (PDF), Clemson
- ↑ Immink, K. A. S. (1994), "Reed–Solomon Codes and the Compact Disc", in Wicker, Stephen B.; Bhargava, Vijay K. (eds.), Reed–Solomon Codes and Their Applications, IEEE Press, ISBN 978-0-7803-1025-4
- ↑ Hagenauer, J.; Offer, E.; Papke, L. (1994). "11. Matching Viterbi Decoders and Reed-Solomon Decoders in a Concatenated System". Reed Solomon Codes and Their Applications. IEEE Press. p. 433. ISBN 9780470546345. OCLC 557445046.
- 1 2 Andrews, K.S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C.R.; Pollara, F. (2007). "The development of turbo and LDPC codes for deep-space applications" (PDF). Proceedings of the IEEE. 95 (11): 2142–56. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ↑ See Lin & Costello (1983, p. 171), for example.
- ↑ "Analytical Expressions Used in bercoding and BERTool". Archived from the original on 2019-02-01. Retrieved 2019-02-01.
- ↑ Pfender, Florian; Ziegler, Günter M. (September 2004), "Kissing Numbers, Sphere Packings, and Some Unexpected Proofs" (PDF), Notices of the American Mathematical Society, 51 (8): 873–883, archived (PDF) from the original on 2008-05-09, retrieved 2009-09-28. Explains the Delsarte-Goethals-Seidel theorem as used in the context of the error correcting code for compact disc.
- ↑ D. Gorenstein and N. Zierler, "A class of cyclic linear error-correcting codes in p^m symbols," J. SIAM, vol. 9, pp. 207–214, June 1961
- ↑ Error Correcting Codes by W Wesley Peterson, 1961
- ↑ Shu Lin and Daniel J. Costello Jr, "Error Control Coding" second edition, pp. 255–262, 1982, 2004
- ↑ Guruswami, V.; Sudan, M. (September 1999), "Improved decoding of Reed–Solomon codes and algebraic geometry codes", IEEE Transactions on Information Theory, 45 (6): 1757–1767, CiteSeerX 10.1.1.115.292, doi:10.1109/18.782097
- ↑ Koetter, Ralf; Vardy, Alexander (2003). "Algebraic soft-decision decoding of Reed–Solomon codes". IEEE Transactions on Information Theory. 49 (11): 2809–2825. CiteSeerX 10.1.1.13.2021. doi:10.1109/TIT.2003.819332.
- ↑ Franke, Steven J.; Taylor, Joseph H. (2016). "Open Source Soft-Decision Decoder for the JT65 (63,12) Reed–Solomon Code" (PDF). QEX (May/June): 8–17. Archived (PDF) from the original on 2017-03-09. Retrieved 2017-06-07.
Further reading
- Gill, John (n.d.), EE387 Notes #7, Handout #28 (PDF), Stanford University, archived from the original (PDF) on June 30, 2014, retrieved April 21, 2010
- Hong, Jonathan; Vetterli, Martin (August 1995), "Simple Algorithms for BCH Decoding" (PDF), IEEE Transactions on Communications, 43 (8): 2324–33, doi:10.1109/26.403765
- Lin, Shu; Costello, Jr., Daniel J. (1983), Error Control Coding: Fundamentals and Applications, Prentice-Hall, ISBN 978-0-13-283796-5
- Massey, J. L. (1969), "Shift-register synthesis and BCH decoding" (PDF), IEEE Transactions on Information Theory, IT-15 (1): 122–127, doi:10.1109/tit.1969.1054260, S2CID 9003708
- Peterson, Wesley W. (1960), "Encoding and Error Correction Procedures for the Bose-Chaudhuri Codes", IRE Transactions on Information Theory, IT-6 (4): 459–470, doi:10.1109/TIT.1960.1057586
- Reed, Irving S.; Solomon, Gustave (1960), "Polynomial Codes over Certain Finite Fields", Journal of the Society for Industrial and Applied Mathematics, 8 (2): 300–304, doi:10.1137/0108018
- Welch, L. R. (1997), The Original View of Reed–Solomon Codes (PDF), Lecture Notes
- Berlekamp, Elwyn R. (1967), Nonbinary BCH decoding, International Symposium on Information Theory, San Remo, Italy, OCLC 45195002, AD0669824
- Berlekamp, Elwyn R. (1984) [1968], Algebraic Coding Theory (Revised ed.), Laguna Hills, CA: Aegean Park Press, ISBN 978-0-89412-063-3
- Cipra, Barry Arthur (1993), "The Ubiquitous Reed–Solomon Codes", SIAM News, 26 (1)
- Forney, Jr., G. (October 1965), "On Decoding BCH Codes", IEEE Transactions on Information Theory, 11 (4): 549–557, doi:10.1109/TIT.1965.1053825
- Koetter, Ralf (2005), Reed–Solomon Codes, MIT Lecture Notes 6.451 (Video), archived from the original on 2013-03-13
- MacWilliams, F. J.; Sloane, N. J. A. (1977), The Theory of Error-Correcting Codes, North-Holland, ISBN 978-0-444-85010-2
- Reed, Irving S.; Chen, Xuemin (2012) [1999], Error-Control Coding for Data Networks, Springer, ISBN 9781461550051
External links
Information and tutorials
- Introduction to Reed–Solomon codes: principles, architecture and implementation (CMU)
- A Tutorial on Reed–Solomon Coding for Fault-Tolerance in RAID-like Systems
- Algebraic soft-decoding of Reed–Solomon codes
- Wikiversity:Reed–Solomon codes for coders
- BBC R&D White Paper WHP031
- Geisel, William A. (August 1990), Tutorial on Reed–Solomon Error Correction Coding, Technical Memorandum, NASA, TM-102162
- Concatenated codes by Dr. Dave Forney (scholarpedia.org).
- Reid, Jeff A. (April 1995), CRC and Reed Solomon ECC (PDF)
Implementations
- FEC library in C by Phil Karn (aka KA9Q) includes Reed–Solomon codec, both arbitrary and optimized (223,255) version
- Schifra Open Source C++ Reed–Solomon Codec
- Henry Minsky's RSCode library, Reed–Solomon encoder/decoder
- Open Source C++ Reed–Solomon Soft Decoding library
- Matlab implementation of errors and-erasures Reed–Solomon decoding
- Octave implementation in communications package
- Pure-Python implementation of a Reed–Solomon codec