皮尔逊积矩相关系数
在统计学中,皮尔逊积矩相关系数(英語:,缩写:PPMCC,或PCCs[1][註 1],有时简称相关系数)用于度量兩組數據的变量X和Y之间的線性相關的程度。它是兩個變量的協方差與其標準差的乘積之比; 因此,它本質上是協方差的歸一化度量,因此結果始終具有介於-1和1之間的值。與協方差本身一樣,該度量只能反映變量的線性相關性,而忽略了許多其他類型的關係或相關性。舉個簡單的例子,可以預期高中青少年樣本的年齡和身高的皮尔逊积矩相关系数顯著大於0,但小於1(因為1表示不切實際的完美相關性)。
命名和歷史
它是由卡尔·皮尔逊从弗朗西斯·高尔顿在1880年代提出的一个相似却又稍有不同的想法演变而来,[2][3]并且其数学公式由奥古斯特·布拉菲(Auguste Bravais)于1844年推导出和发表[註 2][7][8][9][10]。系数的命名因此是史蒂格勒名字由來法則的一个例子。
这个相关系数也称作“皮尔森相关系数r”。
定义
两个变量之间的皮尔逊相关系数定义为两个变量的除以它们标准差的乘积:
![{\displaystyle \rho _{X,Y}={\mathrm {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}={E[(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}}}](../I/8b0d0608b5f85d24a9c572f8d1b5769289664dfb.svg)
上式定义了总体相关系数,常用希腊小寫字母 ρ (rho) 作為代表符號。估算样本的和标准差,可得到样本相关系数(样本皮尔逊系数),常用英文小寫字母 r 表示:

r 亦可由样本点的標準分數均值估算,得到與上式等價的表達式:


其中 、 及 分别是 样本的標準分數、样本平均值和样本标准差。




数学特性
总体和样本皮尔逊系数的绝对值小于或等于1。如果样本数据点精确的落在直线上[註 3],或者双变量分布完全在直线上(计算总体皮尔逊系数的情况),则相关系数等于1或-1。皮尔逊系数是对称的:corr(X,Y) = corr(Y,X)。
皮尔逊相关系数有一个重要的数学特性是,因两个变量的位置和尺度的变化并不会引起该系数的改变,即它该变化的不变量 (由符号确定)。也就是说,我们如果把X移动到a + bX和把Y移动到c + dY,其中a、b、c和d是常数,并不会改变两个变量的相关系数[註 4]。我们发现更一般的线性变换则会改变相关系数:参见之后章节对该特性应用的介绍。
由于μX = E(X), σX2 = E[(X − E(X))2] = E(X2) − E2(X),Y也类似, 并且
![{\displaystyle E[(X-E(X))(Y-E(Y))]=E(XY)-E(X)E(Y),\,}](../I/aca600f8cf4523e7c10cd1117e3e908fefbfd346.svg)
故相关系数也可以表示成

对于样本皮尔逊相关系数:

以上方程给出了计算样本皮尔逊相关系数简单的单流程算法,但是其依赖于涉及到的数据,有时它可能是数值不稳定的。
解释
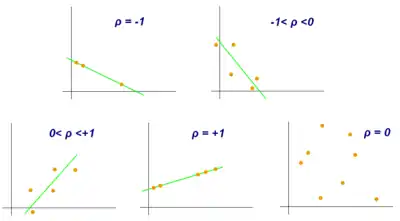
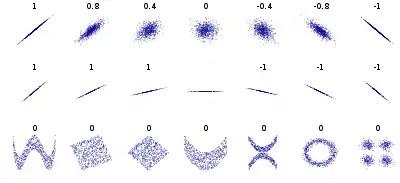
皮尔逊相关系数的变化范围为-1到1。系数的值为1意味着X和 Y可以很好的由直线方程来描述,所有的数据点都很好的落在一条直线上,且 Y 随着 X 的增加而增加。系数的值为−1意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。系数的值为0意味着两个变量之间没有线性关系。
更一般的, 我们发现,当且仅当 Xi 和 Yi 均落在他们各自的均值的同一侧, 则(Xi − X)(Yi − Y) 的值为正。 也就是说,如果Xi 和 Yi 同时趋向于大于, 或同时趋向于小于他们各自的均值,则相关系数为正。 如果 Xi 和 Yi 趋向于落在他们均值的相反一侧,则相关系数为负。
几何学角度的解释
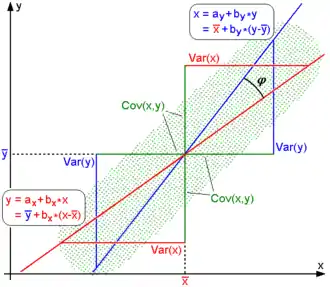
对于没有进行中心化的数据, 相关系数与两条可能的回归线y=gx(x) 和 x=gy(y) 夹角的余弦值一致。
对于中心化过的数据(也就是说, 数据移动一个样本平均值以使其均值为0),相关系数也可以被视作由两个随机变量向量夹角 的余弦值(见下方)。

从一个数据集中可以确定出非中心化的相关系数 (non-Pearson-compliant) 和中心化的相关系数二者。例如,有5个国家的国民生产总值分别为 10, 20, 30, 50 和 80 亿美元。 假设这5个国家 (顺序相同) 的贫困百分比分别为 11%, 12%, 13%, 15%, 和 18% 。 令 x 和 y 分别等于包含上述5个数据的向量: x = (1, 2, 3, 5, 8) 和 y = (0.11, 0.12, 0.13, 0.15, 0.18)。
利用通常的方法计算两个向量之间的夹角 (参见 数量积), 未中心化 的相关系数是:

我们发现以上的数据特意选定为完全相关: y = 0.10 + 0.01 x。 于是,皮尔逊相关系数应该等于1。将数据中心化 (通过E(x) = 3.8移动 x 和通过 E(y) = 0.138 移动 y ) 得到 x = (−2.8, −1.8, −0.8, 1.2, 4.2) 和 y = (−0.028, −0.018, −0.008, 0.012, 0.042), 从中,


![{\displaystyle [-1,1]}](../I/51e3b7f14a6f70e614728c583409a0b9a8b9de01.svg)
![{\displaystyle [0,2]}](../I/120ef5837b0c64a40a2333f5aefd3c36fc458e91.svg)
统计推断:显著性检验与置信区间
基于皮尔逊相关系数的统计推断通常关注以下两个目标。
随机采样方法
显著性检验提供了一种假设检验和构造置信区间的直接方法。
对皮尔逊相关系数的显著性检验包括以下两个步骤:
- 随机地将原始的数据对 (xi, yi)重新定义成数据集 (xi, yi′), 其中 i′ 表示数列 {1,...,n}。 数列 i′ 的选取是随机的, 以相同的概率落在 n! 种可能的数列中。这等价于随机地"不可重复地"从数列{1,..., n}中选取 i′。一种相近的且合乎情理的方法(自助抽样法)是“可重复地”从数列{1,..., n}中选取 i 和 i′
- 由随机数据构造相关系数r。
为了完成显著性检验,需要多次重复步骤(i)和(ii) 。显著性检验的P值是由测试数据除以步骤(ii)得到的r,其中r大于由原始数据计算出的皮尔逊相关系数。在这里“大”可能是绝对值比较大或者是数值比较大,这取决于测试使用的是双尾检验或者是单尾检验。
自助抽样法
自助抽样法可以被用来构造皮尔逊系数的置信区间。在"非参数"的自助抽样法中,“可重复”地从观测数据集n中重新采样n 对的 (xi, yi) 数据,用来计算相关系数r。这个过程重复了大量次数,。重新采样后数据的 r值的分布被用来估计统计学上的样本分布。ρ的95%的置信区间可以被定义成重新采样样本 r值的%2.5到%97.5之间。
基于数学近似的方法
对于近似高斯分布的数据,皮尔逊相关系数的样本分布近似於自由度为N − 2的t分布。特别地,如果两个变量服从双变量正态分布,变量

也會服从不相关的t分布。[14] 如果样本容量不是特别小,这个结论也大致成立,即便观测数据不是正态分布的。[15]如果需要构建置信区间和进行有力的分析,还需要采用如下的可逆变换

或者,也可以采用大量采样数据的方法。
早期对样本相关系数的研究得益于R. A. Fisher[16][17]和A. K. Gayen.[18]的工作。 另一篇早期的论文[19] 给出了在小样本的情况下总体相关系数 ρ的图表, 并讨论了相关的计算方法。
准确服从高斯分布的数据



注意到 , 因此 r 是的一个有偏估计。一种获得无偏估计的方法是解的方程 。 然而,解 是次优的。 一种无偏估计, 可以从 n较大情况下的最小方差和有偏序列 , 通过最大化 , 也就是获得。



![{\displaystyle {\breve {\rho }}=r\left[1+{\frac {1-r^{2}}{2\left(n-1\right)}}\right]}](../I/0689cb013d4ff0b3595891f892fed486f52473a2.svg)


![{\displaystyle {\hat {\rho }}=r\left[1-{\frac {1-r^{2}}{2\left(n-1\right)}}\right]}](../I/ca0d8412be5001c355ee56bce88d2fe2fbb7f997.svg)
特殊情况下,当 时,分布可以被写成


其中 是贝塔函数。

費雪轉換
实际应用中, 与ρ相关的置信区间和假设检验通常是通过費雪轉換获得

如果F(r)是r的費雪轉換,n 是样本容量,那么F(r)近似服从正态分布
- and standard error


也就是Z-分數是
![{\displaystyle z={\frac {x-{\text{mean}}}{\text{SE}}}=[F(r)-F(\rho _{0})]{\sqrt {n-3}}}](../I/da7a3d54a70f9005e3bf9a2accf62cbf0fa0ea71.svg)
对 进行零假设,可以设想样本数据对是独立同分布并且服从双变量正态分布。因此P值估计可以从正态分布概率表中获得。比如,如果观测数据 z = 2.2,并且要用双尾p值对 进行零假设检验,p值是 2·Φ(−2.2) = 0.028, 其中Φ是正态分布的累积分布函数。


置信区间
为了获得ρ的置信区间,首先,我们应该计算 F()的置信区间:

![{\displaystyle 100(1-\alpha )\%{\text{CI}}:\operatorname {arctanh} (\rho )\in [\operatorname {arctanh} (r)\pm z_{\alpha /2}SE]}](../I/1490ea1bc209de8b98cf1621cf02edec8ea1d388.svg)
通过可逆Fisher变换可以获得相关尺度上的区间。
![{\displaystyle 100(1-\alpha )\%{\text{CI}}:\rho \in [\operatorname {tanh} (\operatorname {arctanh} (r)-z_{\alpha /2}SE),\operatorname {tanh} (\operatorname {arctanh} (r)+z_{\alpha /2}SE)]}](../I/9d4cd775618f5f9f87f345df3b050030ba58d2bb.svg)
举例来说,假设我们观测到 r = 0.3,样本容量 n=50,并且我们期望获得ρ的95%的置信区间。变换后的值是artanh(r) = 0.30952,所以在变换尺度上的置信区间是 0.30952 ± 1.96/√47,或者 (0.023624, 0.595415)。变换回相关尺度上是 (0.024, 0.534)。
皮尔逊相关系数和最小方差回归分析
样本相关系数的平方,亦称作决定系数,利用简单线性回归估计由X引起的Y的变化。一开始,Yi围绕它们平均值上的变化可以分解成

其中 是作回归分析时的适应值。 整理后得


两个被加数是由X (右边)引起的Y的变化和不是由X(左边)引起的变化。
接下来, 我们利用最小方差回归模型, 使 和 的样本协方差为0。 于是, 观测数据和适应值的样本相关系数可以被写成

![{\displaystyle {\begin{aligned}r(Y,{\hat {Y}})&={\frac {\sum _{i}(Y_{i}-{\bar {Y}})({\hat {Y}}_{i}-{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\&={\frac {\sum _{i}(Y_{i}-{\hat {Y}}_{i}+{\hat {Y}}_{i}-{\bar {Y}})({\hat {Y}}_{i}-{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\&={\frac {\sum _{i}[(Y_{i}-{\hat {Y}}_{i})({\hat {Y}}_{i}-{\bar {Y}})+({\hat {Y}}_{i}-{\bar {Y}})^{2}]}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\&={\frac {\sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\&={\sqrt {\frac {\sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}{\sum _{i}(Y_{i}-{\bar {Y}})^{2}}}}.\end{aligned}}}](../I/b0287deb80f92b1168d30932370fac2a2d4c7d55.svg)
于是

是由X的线性方程引起的Y的平均变化。
数据分布的敏感度
存在性
总体皮尔逊相关系数被定义成 矩,因此任意的双变量概率分布是非零的,也就是说是由总体协方差和边缘总体方差定义的。一些概率分布,如柯西分布的方差未定义,因此若X或Y服从这种分布,ρ便是未定义的。在实际应用中,若有懷疑数据服从重尾分布,就需要重视這个条件。然而,相关系数的存在性通常無關緊要,例如若分布有界,則ρ必有意义。
大样本的特性
在双变量正态分布的案例中,只要边缘均值和方差是已知的,总体相关系数描述的是便是联合分布。在其他的双变量分布中,这个结论并不正确。总之,不论两个随机变量的联合分布是不是正态的,相关系数都對研究它们之间的线性依赖性有帮助。[2]样本相关系数是对两个正态分布变量总体相关系数的最大似然估计,并且是渐进无偏和有效率的。換言之,如果数据是遵循正态分佈,并且样本容量不太小,就不可能构造出一个比样本相关系数更准确的估计。对于非正态的数据,样本相关系数大致上是无偏的,但有可能是无效的。只要样本均值、方差和协方差是一致的(当大数定理可以应用的情况下),样本相关系数是总体相关系数的一致估计 。
稳健性
与其他常用的统计指标類似,样本指标r不穩健[22] 。因此如果由離群值,这个指标是有误导性的。[23][24]特别地,PMCC既不是稳健分布的,也不是异常值稳健的[22] (見穩健統計)。观察X和Y的散点图,可以認出是否缺乏稳健性,在这种情况下,采用的联合的方法是比较明智的。注意到,虽然大多数稳健的估计量,都有某程度的统计依赖,但总括而言,在总体相关系数的尺度上都是可辨的。
基于皮尔逊相关系数的统计推断,对数据分布敏感。如果数据大致是正态分布的,可以使用精确检验和基于费雪变换的渐进检验,但是它们可能有误导性。在一些情况下,自助采样可以用来构造置信区间。同时,重复抽样可以应用在假设检验中。这些非参数化的方法在某些情况下,如不能保证是双变量正态分布时,可能得出更有意义的结论。然而,这些方法的标准形式,依赖于数据要可交換。这也就意味着要分析的数据没有顺序的和组别之分,否則可能会影响估计相关系数的特性。
分层分析是一种容许缺少双变量正态性的方法,或者说是用来隔离相互关联因素的关联结果。如果W代表聚类成员或者其它需要控制的因素,則可以分离基于W的数据,然后可以再逐层计算相关系数。当控制变量W,便能在层的等级上估计与所有相关系数相关的各自的相关系数。[25]
计算加权相关系数
假设我们要计算关联性的观测数据有着不同的重要程度,表示成权值向量 w。 利用权值向量w (总长度 n)计算向量 x 和 y 的相关系数,[26]
- 加权均值:

- 加权协方差

- 加权相关系数

去除相关性
我们总是可以通过一定的线性变换去除随机变量之间的相关性, 即便变量间的关系是非线性的。 Cox & Hinkley[27]给出了在总体相关系数中的表达形式。
与此相应的,样本相关系数也存在这样的结论,使得样本相关系数变为0。假设长度为 n 的随机变量被随机采样 m 次。 令 X 是一个矩阵,其中 是第i次采样的第 j个变量。 令 是一个所有元素都为1的 m * m 的方阵。 那么 D 是变换后的数据,使得随机变量的均值为0, 并且 T 是变换后的数据,使得所有的变量均值为0和与除自身外的其他变量的相关系数为0 - T的矩作为身份矩阵。 为了得到单位方差,还需要除以标准差。 虽然变换后的数据有可能不是独立的,但他们一定是不相关的。




其中,指数-1/2表示矩阵置换后的矩阵方根。T的协方差被当做身份矩阵。如果新的样本数据x是n个元素的向量, 那么相同的变换可以应用到x中以获得变换向量d和t:


这个去相关性的方法被应用到多变量的主成分分析中。
反射相关性
反射相关系数是皮尔逊相关系数的变体,数据并不是以他们的均值为中心。总体反射相关系数是
![{\displaystyle {\text{Corr}}_{r}(X,Y)={\frac {E[XY]}{\sqrt {EX^{2}\cdot EY^{2}}}}.}](../I/48bbcef8471f3859016e0cb30195ce20b91d5cf3.svg)
反射相关系数是对称的, 但在如下的变换中并不是不变的

样本反射相关系数是

样本加权相关系数是

比例关系
规模的相关性是一个变种的皮尔森相关数据的范围限制故意以受控的方式揭示时间序列之间的快速成分的相关性。比例相关的定义是在短数据段的平均相关性。 对于给定规模S,令K为可以适应信号的总长度的段数:

比例相关的整个信号的rs的计算公式为

rs为k的部分皮尔森相关系数。 通过对参数s的选择,减少值的范围和较长的时间尺度上的相关性被过滤掉,只有在很短的时间尺度上的相关性被发现。因此,慢分量的贡献被删除,快分量被保留。
强噪声条件下
强噪声条件下,提取相关系数两个随机变量之间的是平凡的,特别是在典型相关分析报告在退化的相关值的情况下,由于存在大量噪声。一种概括的方法在其他地方给出。
相關條目
註釋
参考文献
- "The human disease network", Albert Barabasi et al., Plos.org
- J. L. Rodgers and W. A. Nicewander. Thirteen ways to look at the correlation coefficient (页面存档备份,存于). The American Statistician, 42(1):59–66, February 1988.
- Stigler, Stephen M. . Statistical Science. 1989, 4 (2): 73–79. JSTOR 2245329. doi:10.1214/ss/1177012580.
- Galton, F. . Nature. 5–19 April 1877, 15 (388, 389, 390): 492–495 ; 512–514 ; 532–533 [2022-06-05]. Bibcode:1877Natur..15..492.. S2CID 4136393. doi:10.1038/015492a0
 . (原始内容存档于2022-07-03). In the "Appendix" on page 532, Galton uses the term "reversion" and the symbol r.
. (原始内容存档于2022-07-03). In the "Appendix" on page 532, Galton uses the term "reversion" and the symbol r. - Galton, F. . Nature. 24 September 1885, 32 (830): 507–510 [2022-06-05]. (原始内容存档于2022-07-03).
- Galton, F. . Journal of the Anthropological Institute of Great Britain and Ireland. 1886, 15: 246–263 [2022-06-05]. JSTOR 2841583. doi:10.2307/2841583. (原始内容存档于2022-07-03).
- Pearson, Karl. . Proceedings of the Royal Society of London. 20 June 1895, 58: 240–242 [2022-06-05]. Bibcode:1895RSPS...58..240P. (原始内容存档于2022-07-03).
- Stigler, Stephen M. . Statistical Science. 1989, 4 (2): 73–79. JSTOR 2245329. doi:10.1214/ss/1177012580 .
- . Mem. Acad. Roy. Sci. Inst. France. Sci. Math, et Phys. 1844, 9: 255–332 [2022-07-10]. (原始内容存档于2022-07-05) –Google Books (法语).
- Wright, S. . Journal of Agricultural Research. 1921, 20 (7): 557–585.
- A. Buda and A.Jarynowski (2010) Life-time of correlations and its applications vol.1, Wydawnictwo Niezalezne: 5–21, December 2010, ISBN 978-83-915272-9-0
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.)
- Fulekar (Ed.), M.H. (2009) Bioinformatics: Applications in Life and Environmental Sciences, Springer (pp. 110) ISBN 1402088795
- N.A Rahman, A Course in Theoretical Statistics; Charles Griffin and Company, 1968
- Kendall, M.G., Stuart, A. (1973)The Advanced Theory of Statistics, Volume 2: Inference and Relationship, Griffin. ISBN 0852642156 (Section 31.19)
- Fisher, R.A. . Biometrika. 1915, 10 (4): 507–521. doi:10.1093/biomet/10.4.507.
- Fisher, R.A. (PDF). Metron. 1921, 1 (4): 3–32 [2009-03-25].
- Gayen, A.K. . Biometrika. 1951, 38: 219–247. doi:10.1093/biomet/38.1-2.219.
- Soper, H.E., Young, A.W., Cave, B.M., Lee, A., Pearson, K. (1917). "On the distribution of the correlation coefficient in small samples. Appendix II to the papers of "Student" and R. A. Fisher. A co-operative study", Biometrika, 11, 328-413. doi:10.1093/biomet/11.4.328
- Kenney, J. F. and Keeping, E. S., Mathematics of Statistics, Pt. 2, 2nd ed. Princeton, NJ: Van Nostrand, 1951.
- Weisstein, Eric W. (编). . at MathWorld--A Wolfram Web Resource. Wolfram Research, Inc. [2012-03-17]. (原始内容存档于2012-05-11) (英语).
- Wilcox, Rand R. . Academic Press. 2005.
- Devlin, Susan J; Gnanadesikan, R; Kettenring J.R. . Biometrika. 1975, 62 (3): 531–545. JSTOR 2335508. doi:10.1093/biomet/62.3.531.
- Huber, Peter. J. . Wiley. 2004.
- Katz., Mitchell H. (2006) Multivariable Analysis - A Practical Guide for Clinicians. 2nd Edition. Cambridge University Press. ISBN 9780521549851. ISBN 052154985X doi:10.2277/052154985X
- http://sci.tech-archive.net/Archive/sci.stat.math/2006-02/msg00171.html</ref><ref>A MATLAB Toolbox for computing Weighted Correlation Coefficients (页面存档备份,存于)
- Cox, D.R., Hinkley, D.V. (1974) Theoretical Statistics, Chapman & Hall (Appendix 3) ISBN 0412124203
外部連結
- 相關係數:使用皮爾森檢定與斯皮爾曼等級檢定的研究問題(中國醫藥大學,生物統計課程)
- 相關係數:資料型態與適用統計方法(中國醫藥大學,生物統計課程)