中央处理器
()(英語:,英文缩写为CPU)是计算机的主要设备之一,功能主要是解释计算机指令以及处理计算机软件中的数据。1970年代以前,中央处理器由多个独立单元构成,后来发展出由集成电路制造的中央处理器,這些高度收縮的元件就是所謂的微处理器,其中分出的中央处理器最為复杂的电路可以做成单一微小功能强大的单元,也就是所謂的核心。


中央处理器廣義上指一系列可以执行复杂的计算机程序的逻辑机器。这个空泛的定义很容易地将在“CPU”这个名称被普遍使用之前的早期计算机也包括在内。无论如何,至少从1960年代早期开始,这个名称及其缩写已开始在电子计算机产业中得到广泛应用。尽管与早期相比,“中央处理器”在物理形态、设计制造和具体任务的执行上有了极大的发展,但是其基本的操作原理一直没有改变。
早期的中央处理器通常是为大型及特定应用的计算机而定制。但是,这种昂贵的为特定应用定制CPU的方法很大程度上已经让位于开发便宜、标准化、适用于一个或多个目的的处理器类。这个标准化趋势始于由单个晶体管组成的大型机和微机年代,随着集成电路的出现而加速。IC使得更为复杂的中央处理器可以在很小的空间中设计和制造(在微米的數量级)。中央处理器的标准化和小型化都使这一类電子零件在现代生活中的普及程度越來越高。现代处理器出现在包括从汽车、手机到儿童玩具在内的各种物品中。
历史

在现今的CPU出现之前,如同ENIAC之类的计算机在执行不同程序时,必须经过一番线路调整才能启动。由于它们的线路必须被重设才能执行不同的程序,這些机器通常称为「固定程序计算机」(fixed-program computer)。而由于CPU这个词指称为执行软件(计算机程序)的装置,那些最早与储存程序型计算机一同登场的装置也可以被称为CPU。
储存程序型计算机的主意早已体现在ENIAC的设计上,但最终还是被省略以期早日完成。在1945年6月30日,ENIAC完成之前,著名数学家冯·诺伊曼发表名为《关于EDVAC的报告草案》的论文。它揭述储存程序型计算机的计划最終将在1949年8月完成。[1]EDVAC的目标是执行一定数量与种类的指令(或操作),这些指令结合产生出可以让EDVAC执行的有用程序。特別的是,为EDVAC而写的程序是储存在高速计算机内存中,而非由实体线路组合而成。这項设计克服了ENIAC的某些局限——即花费大量时间与精力重设线路以执行新程序。在冯·诺伊曼的设计下,EDVAC可以借由改变内存储存的内容,简单更换它执行的程序(软件)[註 1]。
值得注意的是,尽管冯·诺伊曼由于设计了EDVAC,使得他在发展储存程序型计算机上的贡献最为显著,但其他早于他的研究员如康拉德·楚澤(Konard Zuse)也提出过类似的想法。另外早于EDVAC完成,利用哈佛架构制造的马克一号,也利用打孔带而非电子内存用作储存程序的概念。冯·诺伊曼架构与哈佛架构最主要的不同在于后者将CPU指令与资料分开存放与处置,而前者使用相同的内存位置。大多近代的CPU依照冯·诺伊曼架构设计,但哈佛架构一样常见。
身为数位装置,所有CPU处理不连续状态,因此需要一些转换与区分这些状态的基础元件。在市场接受晶体管前,继电器与真空管常用在这些用途上。虽然这些材料速度上远优于纯粹的机械构造,但是它们有许多不可靠的地方。例如以继电器建造直流时序逻辑回路需要额外的硬件以应付接触点跳动問題。而真空管不会有接触点跳动问题,但它们必须在启用前预热,也必须同时停止运作[註 2]。通常當一根真空管坏了,CPU必须找出损坏元件以置换新管。因此早期的电子真空管式计算机快于电子继电器式计算机,但维修不便。类似EDVAC的真空管计算机每隔八小时便会损坏一次,而较慢较早期的马克一号却不太发生故障。[2]但在最后,由于速度优势,真空管计算机主宰了当时的计算机世界,尽管它们需要较多的维护照顾。大多早期的同步CPU,其时钟频率低于近代的微电子设计(见下列对于时钟频率的讨论)。那时常见的时钟频率为10万赫兹到4百万赫兹,大大受限于内建切换装置的速度。
分立晶体管与集成电路中央处理器

由于许多科技厂家投入更小更可靠的电子装置,使得设计CPU变得越来越复杂。晶体管的面世即是CPU第一个质的飞跃。1950到60年代的晶体管CPU不再以体积庞大、不可靠与易碎的开关元件(例如继电器与真空管)建造。借由这项改良,更加复杂与可靠的CPU便被建造在一个或多个包含分立(离散)元件的印刷电路板上,从而向体积小、可靠与不易损坏方向发展。
在此时期,将许多晶体管放置在拥挤空间中的方法大为普及。積體電路(IC)将大量的晶体管集中在一小块半导体片,或晶片(chip)上。刚开始只有非常基本、非特定用途的数字电路小型化到IC上(例如NOR逻辑閘)。以这些预装式IC为基础的CPU称为小规模集成电路(SSI)装置。SSI IC,例如装置在阿波罗导航计算机上的那些计算机,通常包含数十个晶体管。以SSI IC建构整个CPU需要数千个独立的晶片,但与之前的分立晶体管设计相比,依然省下很多空间与电力。肇因于微電子科技的进步,在IC上的晶体管数量越来越大,因此减少了建构一个完整CPU需要的独立IC数量。「中规模集成电路」(MSI)与「大规模集成电路」(LSI)将内含的晶体管数量增加到成百上千。
1964年IBM推出了System/360计算机架构,此架构让一系列速度与性能不同的IBM计算机可以运行相同的程序。此确实为一项创举,因为当时的计算机大多互不相容,甚至同一家厂商制造的也是如此。为了实践此项创举,IBM提出了微程序概念,此概念依然广泛使用在现代CPU上。[3]System/360架构由于太过成功,因此主宰了大型计算机数十年之久,并留下一系列使用相似架构,名为IBM zSeries的现代主机产品。同一年(1964),迪吉多(DEC)推出另一个深具影响力且瞄准科学与研究市场的计算机,名为PDP-8。DEC稍后推出非常有名的PDP-11,此产品原先计划以SSI IC构组,但在LSI技术成熟后改为LSI IC。与之前SSI和MSI的祖先相比,PDP-11的第一个LSI产品包含了一个只用了4个LSI IC的CPU。[4]
晶体管计算机有许多前一代产品沒有的优点。除了可靠度与低耗电量之外,由于晶体管的状态转换时间比继电器和真空管短得多,CPU也就拥有更快的速度。得益于可靠度的提升和晶体管转换器切换时间的缩短,CPU的时钟频率在此时期达到十几百万赫兹。另外,由于分立晶体管与IC CPU的使用量大增,新的高性能设计,例如SIMD(单指令多数据)、向量处理机开始出现。这些早期的实验性设计,刺激了之后超级计算机(例如克雷公司)的崛起。
中央處理器操作原理
CPU的主要运作原理,不论其外觀,都是执行储存于被称为程序裡的一系列指令。在此討论的是遵循普遍的馮·諾伊曼結構(von Neumann architecture)设计的装置。程序以一系列数字储存在计算机記憶體中。差不多所有的冯·诺伊曼CPU的运作原理可分为四个階段:提取、解碼、执行和写回。
第一階段,提取,从程序内存中檢索指令(为数值或一系列数值)。由程序計数器指定程序記憶體的位置,程序計数器保存供識別目前程序位置的数值。换言之,程序計数器記錄了CPU在目前程序裡的蹤跡。提取指令之后,PC根據指令式長度增加記憶體單元[註 3]。指令的提取常常必须从相对较慢的記憶體尋找,导致CPU等候指令的送入。这个问题主要被论及在現代处理器的快取和管線化架构(见下)。
CPU根據从記憶體提取到的指令来決定其执行行为。在解碼階段,指令被拆解为有意義的片段。根據CPU的指令集架构(ISA)定義将数值解譯为指令[註 4]。一部分的指令数值为运算碼,其指示要进行哪些运算。其它的数值通常供給指令必要的資訊,諸如一个加法运算的运算目标。这样的运算目标也许提供一个常数值(即立即值),或是一个空間的定址值:暫存器或記憶體位址,以定址模式決定。在舊的设计中,CPU裡的指令解碼部分是無法改变的硬体装置。不过在眾多抽象且复杂的CPU和ISA中,一个微程序时常用来幫助转换指令为各種形態的訊号。这些微程序在已成品的CPU中往往可以重写,方便变更解碼指令。
在提取和解碼階段之后,接著进入执行階段。該階段中,連接到各種能夠进行所需运算的CPU部件。例如,要求一个加法运算,算术逻辑单元将会連接到一组輸入和一组輸出。輸入提供了要相加的数值,而且在輸出将含有總和结果。ALU内含電路系統,以于輸出端完成简单的普通运算和逻辑运算(比如加法和位元运算)。如果加法运算產生一个对該CPU处理而言过大的结果,在标誌暫存器裡,溢出标誌可能会被設置(參见以下的数值精度探討)。
最终階段,写回,以一定格式将执行階段的结果简单的写回。运算结果经常被写进CPU内部的暫存器,以供隨后指令快速存取。在其它案例中,运算结果可能写进速度较慢,如容量较大且较便宜的主記憶體。某些类型的指令会操作程序計数器,而不直接產生结果資料。这些一般稱作「跳轉」並在程序中帶来循環行为、條件性执行(透过條件跳轉)和函式[註 5]。许多指令也会改变标誌暫存器的状态位元。这些标誌可用来影響程序行为,緣由于它们时常显出各種运算结果。例如,以一个「比较」指令判斷兩个值的大小,根據比较结果在标誌暫存器上設置一个数值。这个标誌可藉由隨后的跳轉指令来決定程序动向。
在执行指令並写回结果資料之后,程序計数器的值会遞增,反覆整个过程,下一个指令周期正常的提取下一个順序指令。如果完成的是跳轉指令,程序計数器将会修改成跳轉到的指令位址,且程序繼續正常执行。许多复杂的CPU可以一次提取多个指令、解碼,並且同时执行。这个部分一般涉及「經典RISC管線」,那些实際上是在眾多使用简单CPU的電子装置中快速普及(常称为微控制器)[註 6]。
设计与實作
整数范围
CPU数字表示方法是一个设计上的选择,这个选择影响了设备的工作方式。一些早期的数字计算机内部使用电气模型来表示通用的十进制(基于10进位)記數系統数字。还有一些罕见的计算机使用三进制表示数字。几乎所有的现代的CPU使用二进制系统来表示数字,这样数字可以用具有两个值的物理量来表示,例如高低电平[註 7]等等。

与数表示相关的是一个CPU可以表示的数的大小和精度,在二进制CPU情形下,一个位(bit)指的是CPU处理的数中的一个有意义的位,CPU用来表示数的位数量常常被称作“字长”、“位宽”、“数据通路宽度”,或者当严格地涉及到整数(与此相对的是浮点数)时,称作“整数精度”,该数量因体系结构而异,且常常在完全相同的CPU的不同部件中也有所不同。例如:一个8位的CPU可处理在八个二进制数码(每个数码具有两个可能的取值,0或1)表示范围内的数,也就是说,28或256个离散的数值。 实际上,整数精度在CPU可执行的软件所能利用的整数取值范围上设置了硬件限制。[註 8]
整数精度也可影响到CPU可寻址(定址)的内存数量。譬如,如果二进制的CPU使用32位来表示内存地址,而每一个内存地址代表一个八位元组,CPU可定位的容量便是232个位元组或4GB。以上是简单描述的CPU地址空间,通常实际的CPU设计使用更为复杂的寻址方法,例如为了以同样的整数精度寻址更多的内存而使用分页技术。
更高的整数精度需要更多线路以支持更多的数字位元,也因此结构更复杂、更巨大、更花费能源,也通常更昂贵。因此尽管市面上有许多更高精准度的CPU(如16,32,64甚至128位),但依然可见应用软件执行在4或8位的微控制器上。越简单的微控制器通常较便宜,花费较少能源,也因此产生较少热量。这些都是设计电子设备的主要考量。然而,在专业级的应用上,额外的精度给予的效益(大多是给予额外的地址空间)通常显著影响它们的设计。为了同时得到高与低位宽度的优点,许多CPU依照不同功用将各部分设计成不一样的位宽度。例如IBM System/370使用一个原为32位的CPU,但它在其浮点单元使用了128位精度,以得到更佳的精确度与浮点数的表示范围。[3]许多后来的CPU设计使用类似的混合位宽,尤其当处理器设计为通用用途,因而需要合理的整数与浮点数运算能力时。
时钟频率

主頻=外頻×倍頻。
大部分的CPU,甚至大部分的时序逻辑设备,本质上都是同步的。[註 9]也就是说,它们被设计和使用的前題是假设都在同一个同步信号中工作。这个信号,就是众所周知的时脈訊号,通常是由一个周期性的方波(构成)。通过计算电信号在CPU众多不同电路中的分支中循环所需要的最大时间,设计者们可为时脈訊号选择一个适合的周期。
该周期必须比信号在延迟最大的情況下移动或者传播所需的时间更长。设计整个CPU在时钟信号的上升沿和下降沿附近移动数据是可能的。无论是在设计还是元件的维度看来,均对简化CPU有显著的优点。同时,它也存在CPU必须等候回应较慢元件的缺点。此限制已透过多种增加CPU并行运算的方法下被大幅的补偿了。(见下文)
无论如何,结构上的改良无法解決所有同步CPU的弊病。比方說,时脈訊号易受其它的电子信号影响。在逐渐复杂的CPU中,越来越高的时钟频率使其更难与整个单元的时脈訊号同步。是故近代的CPU傾向发展多个相同的时脈訊号,以避免单一信号的延迟使得整个CPU失灵。另一个主要的问题是,时脈訊号的增加亦使得CPU产生的热能增加。持续变动的时钟频率使得许多元件切换(Switch)而不论它们是否处于运作状态。一般来說,一个处于切换状态的元件比处于静止状态还要耗费更多的能源。因此,时钟频率的增加使得CPU需要更有效率的冷却方案。
其中一个处理切换不必要元件的方法称为时脈閘控,即关闭对不必要元件的时钟频率(有效的禁止元件)。但此法被认为太难实行而不见其低耗能通用性。[註 10]另一个对全程时钟信号的方法是同时移除时钟信号。当移除全程时钟信号;使得设计的程序更加复杂时,非同步(或無時脈)设计使其在能源消耗与產生熱能的维度上更有优势。罕见的是,所有的CPU建造在沒有利用全程时钟信号的狀況。兩个值得注意的範例是ARM("Advanced RISC Machine")順从AMULET以及MIPS R3000相容MiniMIPS。与其完全移除时脈訊号,部份CPU的设计允许一定比例的装置不同步,比方說使用不同步算術邏輯單元連接超純量管線以達成一部份的算術效能增进。在不将时脈訊号完全移除的情況下,不同步的设计可使其表現出比同步計数器更少的数学运算。因此,结合了不同步设计極佳的能源耗损量及熱能產生率,使它更適合在嵌入式计算机上运作。[5]
并行

前面描述的CPU结构只能在同一时间点执行一个指令,这种类型的CPU被称为低标量。
这一类型的CPU有一很大的缺点:效率低。由于只能执行一个指令,此类的进程給与低标量CPU固有的低效能。由于每次僅有一个指令能夠被执行,CPU必须等到上个指令完成才能繼續执行。如此便造成下标量CPU延宕在需要兩个以上的时钟循環才能完成的指令。即便增加第二个执行單元(见下文)也不会大幅提升效能;除了單一通道的延宕以外,雙通道的延宕及未使用的晶体管数量亦增加了。如此的设计使得不论CPU可使用的資源有多少,都僅能一次运行一个指令並可能達到标量的效能(一个指令需一个时脈循環)。無论如何,大部份的效能均为下标量(一个指令需超过一个时脈循環)。
为了達成标量目标以及更佳的效能,导致使得CPU傾向平行运算的各種设计越来越多。提到CPU的平行,有兩个字彙常用来區分这些设计的技術。指令平行处理(Instruction Level Parallelism, ILP)以增加CPU执行指令的速率(换句話說,增加on-die执行資源的利用),以及执行緒平行处理(Thread Level Parallelism, TLP)目的在增加执行緒(有效的个別程序)使得CPU可以同时执行。每種方法均可由其如何嵌入或相对有效(对CPU的效能)来區分。[註 11]
- 指令級並行(Instruction level parallelism,ILP):指令管線化与超純量架构

其中一種達成增加平行运算的方法,便是在主要指令完成执行之前,便进行指令提取及解碼。这種最簡易的技術,我們称为指令管線化,且其被利用在泰半現代的泛用CPU中。透过分解执行通道至離散階段,指令管線化可以兩个以上的指令同时执行。相较于已被淘汰的组合管線,指令管線化不再使用等候指令完全在管線中退出才执行下一指令的技術。
指令管線化產生了下一作業需要前一作業才可完成的可能性。此类狀況又常称为相依衝突。解決的方法是,对此类的情況增加额外的注意,及在相依衝突发生时延遲一部份的指令。自然地,此種解決方法需要额外的循環,是故指令管線化的处理器比低标量处理器还要复杂。(虽然不是很显著)一个指令管線化的处理器的效能可能十分接近标量,只需禁止管線推遲即可。(在一个階段需要超过一个以上的循環的指令)
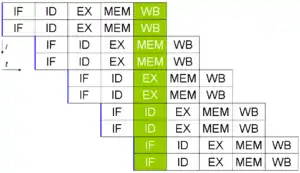
此外,对于指令管線化的改进啟发了減少CPU元件閒置时间的技術。称为超标量的设计包括了一條長指令管線化及多个相同的执行單元。上标量管線的分派器同时讀取及通过数个指令;分派器決定指令是否能夠平行执行(同时执行)並分配到可执行的执行單元。大致上来說,一个上标量的CPU能夠同时分派越多的指令給閒置的执行單元,就能夠完成越多的指令。
上标量CPU结构的设计中,最困難的部份便是創造一个有效率的分派器。分派器必须能夠快速且正確的決定指令是否能夠平行执行,並且讓閒置的执行單元最小化。其需要指令管線化常时的充滿指令流,且提升了在上标量结构中一定数量的CPU快取。其亦催生了危害迴避的技術,如分支預測、投機执行与跨序执行以维持高層次的效能。藉由嘗試預測特定的指令選擇何分支(路徑),CPU能夠最小化整个指令管線等待特定的指令完成的次数。投機执行則是藉著执行部份的指令以得知其是否在整个作業完成后仍被需要而提供適度的效能提升。跨序执行則是重新整理指令执行的命令以降低資料相依。
当不是所有的CPU元件均有上标量效能时,未達上标量的元件效能便会因定序推遲而降低。奔腾的原型有兩个每一时脈循環可接收一个指令的上标量算術逻辑單元,但其浮點算術处理器(Floating Point Unit, FPU)不能在每一时脈循環接收一个指令。因此P5的效能只能算是整数上标量而非浮點上标量。英特爾Pentium结构的下一代P6加入了浮點运算处理器的上标量能力,因此在浮點指令上有显著的效能提升。
此兩種简单的管線及上标量设计,均能透过允许單一处理器在一个时钟循环完成一个指令[註 12],提升指令管線化的效能。多数的近代CPU设计至少都在上标量以上,且几乎所有十年内的泛用CPU均達上标量。近年来,一些重視高指令管線化的计算机将其从CPU的硬体移至软件。超長指令字元(的策略使得一部份的指令管線化成为软件,減少CPU推动指令管線化的工作量,並降低了CPU的设计复杂度。
- 執行緒級並行(Thread-level parallelism,TLP):同时执行緒执行或线程级并行处理
另一个常用以增加CPU平行运算效能的策略是讓CPU有同时执行多个执行緒的能力。大致上說来,高同时执行緒平行执行(TLP)CPU比高指令平行执行来的有用。许多由克雷公司(Cray)公司于1970年代及1980年代晚期所首創的同时执行緒平行执行,專于該方法而啟发了龐大的計算效力。(就时间上而言)事实上,TLP多线程运算自从1950年就已经开始被运用了(Smotherman 2005)。在单处理器设计中,两种主要实现TLP的设计方法是芯片级多处理(CMP)芯片层多线程处理和同步多執行緒(simultaneous multithreading,SMT)。同级别层多线程处理。在更高级层中,一台计算机中有多个单独的处理器,常常运用对称多处理机(SMP)和non-uniform memory access(NUMA)非独立内存访问的方式来组织。[註 13]这些非常不同的方法,全部为了实现同一个目标,就是增加CPU同时处理多个线程的能力。
CMP和SMP这两种方法其实是非常相似的,而且是最直接的方法。这里有一些概念上的东西关于如何实两个或是两个以上完全单独的CPU。在CMP中,多个处理器内核会被放入同一个包中,有时会在非常相近的集成电路中。[註 14]另一方面SMP包含多个包在其中,NUMA和SMP很相像,但是NUMA使用非单一的内存访问方式。这些对于一台有着多个CPU的电脑来说是非常重要的,因为每个处理器访问内存的时间会很快的被SMP分享的模块消耗掉,因些会造成很严重的延迟,因为CPU要等待可用的内存.这时NUMA是个不错的选择,它可以允许有多个CPU同时存在一台电脑中而且SMP也可以同时实现.SMT有一些不同之处,就是SMT会尽可能的减少CPU处理能力的分布。TLP的实现实际上和超标量体系结构的实现有些相似,其实上它常常被用在超标量体系结构处理器中,如IBM的POWER5。相比于复制整个CPU,SMT会复制需要的部分来提取指令,加密和分配,就像计算机中的一般的寄存器一样。因此这样会使SMT CPU保持处理单位运作的连续,一些通常会提供给处理单位多个指令而且来自不同的软件线程,这和ILP结构很相似。相比于处理多个指令来自同一个线程,它会同时处理来自不同线程的多个指令。
数据并行
上面提及过的处理器都是一些常量儀器[註 15],而針对向量处理的CPU是较不常见的类型,但它的重要性却越来越高。事实上,在计算机計算上,向量处理是很常见的。顾名思義,向量处理器能在一个命令週期(one instruction)处理多項数據,这有別于只能在一个命令週期内处理單一数據的常量处理器。这兩種不同处理数據的方法,普遍分別称为『單指令,多資料』(SIMD)及『單指令,單資料』(SISD)。向量处理器最大的优點就是能夠在同一个命令週期中对不同的工作进行优化,例如:求一大堆数據的總和及向量的数量积,更典型的例子就是多媒体應用程序(畫像、影像、及聲音)与及眾多不同總类的科學及工程上的工作。当常量处理器只能針对一组数據于單一命令週期内完全执行提取、解碼、执行和写回四个階段的同时,向量处理器已能对较大型的数據如相同时间内执行相同动作。当然,这假設了这个應用程序于單一命令週期内对处理器进行多次要求。
大多数早期的向量处理器,例如Cray-1,大多都只会用于和科研及密碼學有關的應用程序。但是,隨著多媒体向数位媒体轉移,对于能做到『單指令,多資料』的普通用途处理器需求大增。于是,在浮點計算器普及化不久,擁有『單指令,多資料』功能的普通用途处理器便面世了。有些早期的『單指令,多資料』規格,如英特爾的MMX,只能作整数运算。因为大多数要求『單指令,多資料』的應用程序都要处理浮點数字,所以这个規格对软件开发者無疑是一个主要障礙。幸好,这些早期的设计慢慢地被改进和重新设计为現时普遍的『單指令,多資料』新規格,AMD公司也推出了第一个真正能执行浮點SIMD指令集3DNow!,在每个时脈週期可得到4个單精確度浮點数结果,是当时一般x87浮點处理器的4倍。新規格通常都于一ISA關連著。近年,一些值得注意的例子一定要数英特爾的SSE和PowerPC相關的AltiVec(亦称为VMX)。[註 16]

多核心
多核心中央處理器是在中央處理器晶片或封裝中包含多個處理器核心,以偶數為核心數目較為常見,一般共用快取。現今使用雙核心和四核心以上處理器的個人電腦已相當普遍。
第一颗双核心处理器为IBM POWER4处理器,2012年IBM发布了最新8核心的POWER 7+处理器,拥有80MB L3缓存/芯片。
性能
CPU的性能和速度取決於时钟频率(一般以赫茲或十億赫兹計算,即hz与Ghz)和每週期可處理的指令(IPC),兩者合併起來就是每秒可處理的指令(IPS)。[6] IPS值代表了CPU在幾種人工指令序列下“高峰期”的執行率,指示和應用。而現實中CPU組成的混合指令和應用,可能需要比IPS值顯示的,用更長的時間來完成。而內存層次結構的性能也大大影響中央处理器的性能。通常工程師便用各種已標準化的測試去測試CPU的性能,已標準化的測試通常被稱為“基準”(Benchmarks)。如SPECint,此軟仵試圖模擬現實中的環境。測量各常用的應用程序,試圖得出現實中CPU的績效。
提高電腦的處理性能,亦使用多核心處理器。原理基本上是一個集成電路插入兩個以上的個別處理器(意義上稱為核心)[7]。在理想的情況下,雙核心處理器性能將是單核心處理器的兩倍。然而,在現實中,因不完善的軟件算法,多核心處理器性能增益遠遠低於理論,增益只有50%左右。但增加核心數量的處理器,依然可增加一台計算機可以處理的工作量。這意味著該處理器可以處理大量的不同步的指令和事件,可分擔第一核心不堪重負的工作。有時,第二核心將和相鄰核心同時處理相同的任務,以防止崩潰。
CPU发热原理
CPU是计算机系统中的核心组件,负责执行各种计算和指令操作。当CPU运行时,它会进行大量的电子计算和数据处理操作,这需要电流通过芯片内部的导线和晶体管进行传输和开关操作。这个过程会导致电子之间的摩擦和碰撞,产生能量损耗,进而转化为热能。
另外,现代CPU在高性能的同时也具有较高的功耗。当CPU运行时,它会消耗相当的电能,其中一部分会被转化为热能。
實際應用
中央处理器大規模應用在個人電腦上,現今電腦可進入家庭。全因集成電路的發展,令PC在大小、性能以及價位等多個方面均有長足的進步。現今中央处理器價錢平宜,用戶可自行組裝個人電腦。主機板等主要電腦元件,均配合中央处理器設計。不同類型的中央处理器安裝到主機板上不同類型的CPU插槽中(如英特爾的LGA 1700、超微半導體的Socket AM5),令中央處理器變得更省電,溫度更低。大多數IBM PC兼容機(Pentium以後被稱為「標準PC」(Standard PC))使用x86架構的处理器,他們主要由英特爾和超微半導體兩家公司生産,此外威盛電子也有參與中央处理器的生產。但與IBM PC兼容機不同,在2006年之前蘋果電腦所使用的處理器一直是IBM PowerPC RISC,之後的蘋果電腦轉而採用英特爾的處理器,以及EFI韌體。可見中央处理器在現代電腦的重要地位。
著名公司
以下公司曾經或正在生產中央處理器;包含已經倒閉、退出市場或被併購的公司。
- AMD(超微)
- Intel(英特爾)
- Andes (晶心科技)
- ARM(安謀)
- Apple(蘋果)
- Broadcom Limited(博通)
- Cirrus Logic(凌雲邏輯)
- Cyrix(賽瑞克斯)
- 龍芯(中國科學院)
- DEC(迪吉多)
- Fairchild(仙童)
- Fujitsu(富士通)
- Harris(哈瑞斯)
- Hewlett Packard(惠普)
- Hitachi(日立),見Renesas(瑞薩)
- HUAWEI (華為)
- IBM(國際商業機器)
- IDT
- Intersil
- Maxwell(麦克斯韦)
- MHS
- Microsystems International
- MIPS Technologies(美普思科技)
- Mitsubishi(三菱),見Renesas(瑞薩)
- MOS Technology
- Motorola (摩托罗拉)
- MediaTek(聯發科)
- NS(國家半導體)
- NEC(日本電氣),見Renesas(瑞薩)
- NexGen
- OKI(沖電氣)
- OPTi
- Philips(飛利浦)
- Qualcomm(高通)
- RCA(美國無綫電)
- Renesas(瑞薩)
- Rise
- Rockwell(洛克威爾)
- Samsung (三星)
- SGS,見ST(意法半導體)
- Sharp
- ST(意法半導體)
- Siemens(西門子)
- Synertek
- Sun(昇陽)
- Thompson(托馬森)
- Thomson(湯姆遜半導體),見ST(意法半導體)
- TSMC(台積電)
- TI(德克薩斯儀器)
- Toshiba(東芝)
- Transmeta(全美達)
- UMC(聯電)
- VIA(威盛)
- Western Design Center(西部設計中心)
- Western Electric(西部電氣)
- ZiLOG
注释
- 虽然EDVAC在ENIAC建造之前几年(2015)就已在设计,ENIAC已在1948年改造成能执行储存程序的计算机,此时EDVAC正在建造。虽然建造时因费用与时限的关系而将储存程序功能从ENIAC的蓝图中移除,ENIAC依然早于EDVAC成为第一个储存程序型计算机。
- 在正常运作时造成的阴极劣化最终将导致真空管停止运作。另外,有时候真空管的封口有缺陷也会加速阴极劣化,请参照真空管。
- 因为程序计数器记录的是内存地址,而不是指令,所以它的增长取决于指令在内存中所占的单位数。在固定长度指令ISA中,每个指令所占用的内存单位是相同的。例如一个32位的ISA固定长度指令将使用8位内存单位,而且每次将增加4个PC单位。使用变量长度的ISA指令,如x86,它的PC在内存中的增长量取决于最后一个指令的长度。这里要注意的是在更复杂的CPU中,最后一个指令的运行不一定会导至PC单位的增长,特别的是在大量数据传输和超标量体系结构中。
- 因为CPU指令集的结构是基于它的介面和使用方法,所以它经常用来区别CPU的"种类"。例如一个PowerPC CPU会用到许多不的Power ISA变量。有一些CPU,如英特尔Itanium,可以解译多个ISA指令;不过这项工作大多由软件来完成。多于直接将它在硬件中实现。(參见模拟器)
- 一些早期的电脑如马克一号并不支持任何"jump"指令,因些而限制了程序的复杂性。这理由很大程度上导致它们不被认为是严格意义上的CPU,尽管它们和存储程序计算机相似。
- 这里的描述事实上是一个简单的关于經典RISC管線的介绍。它很大程度上没有考虑到CPU缓存的重要性,因而也少了对数据传输访问的介绍。如果想了解更多信息请查阅相关资料。
- 物理概念上的電壓是一种模拟值,实际上可能的值可以有无限多种。为了物理上表达二进制数,我们把特定范围的電壓的值定为1或者是0。電壓的范围通常是构建CPU的部件的运作参数,例如晶体管的阈值限制,所决定。
- 当CPU的整数精确度范围被限制的时候,它可以透过软件和硬件技术相互合作的方法来克服。当我们使用额外的内存时,软件可以处理比CPU限制大几个数量级的整数。有时CPU的ISA也会提供相关的指令,帮助软件更快速地处理大整数。虽然这种处理大整数的方法会比使用拥有高整数精确度的CPU要慢一些,对于处理那些需要大精确度整数的应用,它是一种可取的方法,特别是整数精确度的原生支援成本过高的时候。
- 事实上所有同步运算CPU都运用了时序逻辑电路和组合逻辑电路的结合。(参见布尔逻辑)
- 运用时钟门控技术的一个最近的设计是基于IBM PowerPC的Xbox 360。它大量利用时钟门控技术来减少在运行视频游戏时所需电量的消耗。
- 我们要注意的是不管是ILP或TLP都不可以做为对方的上层控制。它们在增强CPU平行处理能力上有着不同的意义。它们有着各自的优缺点,而且取决于CPU可处理软件种类。High-TLP CPUs经常被用来处理一些可以很自身分解成许多小程序的软件中.因而称它为"embarrassingly parallel problems." 因此high TLP设计方法可以连续快速的处理一些运算问题,比如SMP会使用太多的时间来处理ILP设备(超标量体系结构的CPU),反之亦然。
- 最佳(或最高)IPC率在超标量体系结构中是很难保持不变的,它可能导致使传输总是失败.因此在高超标量体系CPU中,平均相同IPC的方法的使用,多于最佳(或最高)IPC的使用.
- 尽管SMP和NUMA都是在系统层中的TLP设计方案,但它们还是需要CPU在设计中的支持.
- 因TPL的使用比ILP时间更长,所以芯片层多处理技术或多或少的只可以在以后的基于集成电路的微处理器。集成电路多处理技术中看到。导至这种情况的原因是,它不在适和早期的分立元件设备,而且也只被运用了几年(1990-2000),如今注意力都集中在设计高运算能力的CPU,这些CPU都运用了超标量结构的IPC设计方案,如英特尔Pentium 4。尽管如此,以前的技术似乎又被运用到现在CPU设计中来,又换回到稍底层的High -TLP传输中。它表现在增值双核或多核CMP的设计中,如英特尔最新的设计中少了一些超标量体系结构的设计p6,之后的CPU多运用了CMP,包括x86-64、Opteron和Athlon 64 x2,还有Sparc UltraSparc T1,IBM Power4和Power5。还有一些其它的视频游戏机的CPU,如x360中的三核PowerPC设计。
- 早期scalar被用来比较不同ILP方案的IPC(instructions per cycle)的间隔数量。在这里它表示数学中用来比较向量大小的的一个概念。
- 虽然在英特尔的主流CPU中,MMX已经被SSE/SSE2/SSE3所取代,但在之后的CPU中仍然支持MMX技术,通常使用拥有丰富的SSE指令集的相同的硬件来提供大部分的MMX功能。
参考文献
- (PDF). Moore School of Electrical Engineering, University of Pennsylvania. 1945 [2022-07-02]. (原始内容存档 (PDF)于2021-03-09).
- Weik, Martin H. . Ballistic Research Laboratory. 1961 [2006-03-16]. (原始内容存档于2017-09-11).
- Amdahl, G. M.; Blaauw, G. A.; Brooks, F. P. Jr. . IBM Journal of Research and Development (IBM). April 1964, 8 (2): 87–101. ISSN 0018-8646. doi:10.1147/rd.82.0087.
- (PDF). 2nd. Maynard, Massachusetts: Digital Equipment Corporation. November 1975: 4–3 [2022-07-02]. (原始内容存档 (PDF)于2021-10-10).
- Garside, J. D.; Furber, S. B.; Chung, S-H. . University of Manchester Computer Science Department. 1999. (原始内容存档于December 10, 2005).
- "CPU Frequency". CPU World Glossary. CPU World. 25 March 2008. Retrieved 1 January 2010.
- "What is (a) multi-core processor?". Data Center Definitions. SearchDataCenter.com. 27 March 2007. Retrieved 1 January 2010.
外部連結
- CPU简史
- CPU封裝
- CPU历史上的十个第一
- CMP簡要介紹 (页面存档备份,存于) - 簡要的介紹了片上多核處理器,對常見的片上多核處理器採用的技術進行了綜述
- Processor Design: An Introduction - 詳盡地介紹微处理器的设计,虽然有些資料未完成和落伍,但仍具參考價值。
- 微处理器如何运作(页面存档备份,存于)
- Pipelining: An Overview (页面存档备份,存于) - CPU管線技術的簡介,由Ars Technica成员所写。
- SIMD Architectures (页面存档备份,存于) - SIMD的介紹与說明,尤其著重于SIMD与桌上型计算机的关系。一样由Ars Technica所写。
- 微处理器生產商
- Advanced Micro Devices(页面存档备份,存于) - AMD,其中一个生產相容x86计算机的CPU生產商
- ARM Ltd(页面存档备份,存于) - 安謀國際科技,少数只授權其CPU设计而沒有自行制造的公司。嵌入式應用软件最常被ARM架构微处理器执行。
- Freescale Semiconductor(页面存档备份,存于) -(前身是Motorola的)飞思卡尔,设计数款嵌入装置以及SoC PowerPC处理器。
- IBM Microelectronics - IBM的微電子分公司,设计出许多IBM POWER与PowerPC,包括许多的CPU。
- Intel Corp(页面存档备份,存于) - 英特爾,许多著名CPU的生產者,包括IA-32、IA-64与XScale。也是许多用在他們自家CPU的週邊產品的制造者。
- MIPS Technologies(页面存档备份,存于) - MIPS科技公司,MIPS架构的制造者,在RISC设计領域的先鋒。
- Sun Microsystems(页面存档备份,存于) - 升阳,SPARC架构(RISC)的制造者。
- Texas Instruments - 德州仪器,半导体公司,许多以他們自產半导体组成的低耗電微控制器的设计与生產者。
- Transmeta(页面存档备份,存于) - 全美達,低電力X86相容CPU的創造者,例如Crusoe与Efficeon。
- VIA(页面存档备份,存于) - 威盛,低功率X86相容CPU的制造商,例如C3。
参见
| 维基共享资源上的相关多媒体资源:中央处理器 |
| 維基學院中的相關研究或學習資源:中央处理器 |
- 微处理機、微控制器、單晶片
- CPU鎖頻、倍頻器
- 指令集(CISC、RISC)
- MMX、EMMI、3DNow!、SSE、SSE2、SSE3
- 真实模式、保護模式、虛擬86模式
- Pentium OverDrive
- 总线(BUS)、前端匯流排(FSB)
- 浮点运算器(FPU)
- 電機工程學