 | |
| Language(s) | Chinese, Japanese, Korean |
|---|---|
| Standard | MARC-8, ANSI/NISO Z39.64 (both EACC version) |
| Current status | Used mainly by library systems |
| Classification | TBCS for CJK based on the ISO 2022 structure, JACKPHY component of MARC |
The Chinese Character Code for Information Interchange (Chinese: 中文資訊交換碼) or CCCII is a character set developed by the Chinese Character Analysis Group in Taiwan. It was first published in 1980, and significantly expanded in 1982 and 1987.[1]
It is used mostly by library systems.[2][3] It is one of the earliest established and most sophisticated encodings for traditional Chinese (predating the establishment of Big5 in 1984 and CNS 11643 in 1986).[2] It is distinguished by its unique system for encoding simplified versions and other variants of its main set of hanzi characters.[1]
A variant of an earlier version of CCCII is used by the Library of Congress as part of MARC-8, under the name East Asian Character Code (EACC, ANSI/NISO Z39.64),[4] where it comprises part of MARC 21's JACKPHY support. However, EACC contains fewer characters than the most recent versions of CCCII.[5][1] Work at Apple based on Research Libraries Group's CJK Thesaurus, which was used to maintain EACC, was one of the direct predecessors of Unicode's Unihan set.[6]
Design

Byte ranges
CCCII is designed as an 94n set, as defined by ISO/IEC 2022.[1] Each Chinese character is represented by a 3-byte code in which each byte is 7-bit, between 0x21 and 0x7E inclusive. Thus, the maximum number of Chinese characters representable in CCCII is 94×94×94 = 830584. In practice the number of characters encodable by CCCII would be less than this number, because variant characters are encoded in related ISO 2022 planes under CCCII, so most of the code points would have to be reserved for variants.
In practice, however, bytes outside of these ranges are sometimes used. The code 0x212320 is used by some implementations as an ideographic space.[8] A CCCII specification used by libraries in Hong Kong uses codes starting with 0x2120 for punctuation and symbols.[9] The first byte 0x7F is used by some variants to encode codes for some otherwise unavailable Unified Repertoire and Ordering or CJK Unified Ideographs Extension A hanzi (e.g. 0x7F3449 for U+3449 or 0x7F796E for U+796E;[9] notice how the continuation bytes match the UCS-2BE code), and this may include bytes outside of the 0x21–0x7E or even 0x20–0x7F range, e.g. 0x7F551C for U+551C,[10] 0x7F5AA4 for U+5AA4[10] or 0x7F8EDA for U+8EDA.[9]
Interaction with ISO 2022
CCCII/EACC is not registered in the International Registry of Coded Character Sets to be Used with Escape Sequences,[11] and as such, does not have a standard designation escape for use with ISO 2022. MARC-8 assigns EACC the private-use F-byte 0x31 (1) in its implementation of ANSI X3.41 (ISO 2022).[12]
Layers and variant characters
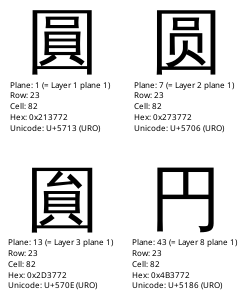
The 94 ISO 2022 planes are grouped into 16 layers of 6 planes each (except for layer 16, which contains the four planes 91–94).[1] Layer 1 contains both non-hanzi and hanzi characters, with the non-hanzi and most frequently used hanzi being placed in plane 1, and with the remaining five planes consisting of less common hanzi.[1] Layer 2 contains simplified Chinese characters, with their row and cell numbers being the same as their traditional Chinese equivalents in layer 1. Layers 3 through 12 contain further variant forms, at row and cell numbers homologous to the first two layers.[13]
The last four layers are used for other purposes. Specifically, layer 13 contains additional characters for Japanese language support (kana and Japanese kokuji), and layer 14 contains additional characters for Korean language support (hangul).[13] Layer 15 is unused (reserved), while layer 16 is used for other characters.[1]
This distinctive design has been criticized by Christian Wittern of the International Research Institute for Zen Buddhism at Hanazono University, who asserts that the relationship of character variants "is very complex and can not be expressed in a fixed, one-dimensional, hard-wired codetable".[3] Ken Lunde describes it as "one of the most well thought-out character set standards from Taiwan", describing its structure as "to be truly admired", but concluding that OpenType variant form substitution can provide the same level of functionality.[1]
CCCII defines roughly 53940 code points as of its 1987 edition, although a more recent draft from 1989 extends this to 75684 code points (comprising 44167 unique characters and 31517 variants). EACC, the variant used by the Library of Congress, includes only a smaller set of 15686 characters.[1]
Adoption
As of 1995, CCCII or EACC was used mostly in libraries in the United States, Hong Kong and Taiwan. Although CCCII promised pan-CJK coverage, its support was limited to specialized hardware; difficulty ascertaining when the root versus variant character should be used, exacerbated by a lack of firmly established reference glyphs, further limited its adoption, resulting in Big5 being more commonly used for Chinese in those territories outside of library use (since Unicode had yet to become widely adopted at the time).[3]
As of 2009, EACC is still in extensive use for specialized bibliographic purposes.[1] It was also an important precursor to Unicode:[1] work at Apple on a CJK character cross-reference database based on Research Libraries Group's CJK Thesaurus, used to maintain EACC, was directly incorporated into the development of Unicode's Unihan set.[6] Unicode hanzi characters are referenced to their corresponding CCCII and EACC codes in the Unihan database, in the keys kCCCII and kEACC;[4] however, since Unicode's character unification criteria (based on those used by the Japanese JIS X 0208 and on those developed by the Association for a Common Chinese Code in China) differ from those used by CCCII, not all variant characters are individually mapped.[6] Mapping tables for hanzi, hangul, kana and punctuation between EACC and Unicode are available from the Library of Congress.[14]
Punctuation, symbol, kana and jamo charts
Following are charts for punctuation, symbols, kana and Hangul jamo, showing the characters and giving possible Unicode mappings. Where possible, these are referenced against published mapping data.
Unicode mappings for Hangul syllables are omitted below for brevity, but are documented by the Library of Congress.[15] CCCII hanzi number in the tens of thousands[1][3] and are not shown below (except where they are also included in the non-hanzi range, as radicals or numerals), but mappings to Unicode are available from the Unihan database[4] and from elsewhere.[10][9]
Character set 0x2120 (plane 1, row 0: Hong Kong punctuation)
Although CCCII is usually a 94n set,[1] and therefore does not usually use codes starting with 0x2120,[10] the following layout is used by a variant used by libraries in Hong Kong:[9]
| CCCII (Hong Kong)[9] (prefixed with 0x2120) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | 、 | 。 | ・ | ゙ | ゚ | ´ | ` | ¨ |  ̄ | ヽ | ヾ | ゝ | ゞ | |||
| 3x | 〃 | 〆 | ‖ | … | ‥ | |||||||||||
| 4x | “ | 〔 | 〕 | 「 | 」 | 『 | 』 | 【 | 】 | ± | × | ÷ | ||||
| 5x | ≠ | ≦ | ≧ | ∞ | ∴ | ♂ | ♀ | ° | ℃ | ¢ | £ | § | ☆ | ★ | ○ | ● |
| 6x | ′ | ″ | ◎ | |||||||||||||
| 7x | ◇ | ◆ | □ | ■ | △ | ▲ | ▽ | ▼ | ※ | 〒 | → | ← | ↑ | ↓ | ||
Character set 0x2121 (plane 1, row 1: reserved for controls)
No characters are assigned in plane 1 row 1, which is reserved for control codes.[1]
Character set 0x2122 (plane 1, row 2: mathematical operators)
This row contains mathematical operators. EACC leaves this row empty.[14] The following table is referenced against sources from Taiwan.[2][10]
| CCCII (Taiwan)[10][16] (prefixed with 0x2122) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ∞ | + | − | ± | × | ⋅ | ÷ | ∕ | = | ≠ | ≡ | ≈ | ∼ | ∝ | < | |
| 3x | > | ≮ | ≯ | ≤ | ≥ | ≪ | ≫ | ∂ | ∫ | Δ | ∆ | ∇ | ▫ | ∠ | ⊤ | ∥ |
| 4x | ≅ | ≞ | ∴ | ∃ | ∀ | ∪ | ∩ | ⊂ | ⊃ | ⇒ | ⇔ | ∋ | ∈ | ∉ | ∑ | ㏒ |
| 5x | ㏑ | ℯ | π | √ | ︕ | ⎸ | ⎹ | 〈 | 〉 | |||||||
| 6x | ||||||||||||||||
| 7x | ||||||||||||||||
The following table is referenced against CCCII data provided by the Hong Kong Innovative Users Group, a group of libraries in Hong Kong, and hosted by the University of Hong Kong.[17][9] It uses an entirely different layout in this row:
| CCCII (Hong Kong)[9] (prefixed with 0x2122) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ∈ | ∋ | ⊆ | ⊇ | ⊂ | ⊃ | ∪ | ∩ | ∧ | ∨ | ¬ | ⇒ | ⇔ | ∀ | ∃ | |
| 3x | ∠ | ⊥ | ⌒ | ∂ | ∇ | ≡ | ≒ | ≪ | ≫ | √ | ∽ | ∝ | ∵ | ∫ | ∬ | |
| 4x | Å | ‰ | ♯ | ♭ | ♪ | † | ‡ | ¶ | ◯ | |||||||
| 5x | ─ | │ | ┌ | ┐ | ┘ | └ | ├ | ┬ | ┤ | ┴ | ┼ | ━ | ┃ | ┏ | ┓ | ┛ |
| 6x | ┗ | ┣ | ┳ | ┫ | ┻ | ╋ | ┠ | ┯ | ┨ | ┷ | ┿ | ┝ | ┰ | ┥ | ┸ | ╂ |
| 7x | ||||||||||||||||
Character set 0x2123 (plane 1, row 3: Roman and punctuation)
This row includes punctuation, western Arabic numerals and Roman letters.[10] Compare row 3 of Wansung code and row 3 of GB 2312.
Different variants variously encode the ideographic space (U+3000) at 0x212320 (which the MARC specification acknowledges),[8][9] 0x212321 (which is listed in the ANSI standard, and is also acknowledged by MARC),[8][9] or 0x21635F.[10] EACC includes only the hyphen-minus, parentheses and ideographic space in this set.[8]
| CCCII/EACC[14][10][16] (prefixed with 0x2123) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | IDSP[lower-alpha 1] | !/IDSP[lower-alpha 2] | " | # | $ | % | & | ' | (/( | )/) | * | + | , | -/- | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ↑ | _ |
| 6x | `/' | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | |
Character set 0x212A (plane 1, row 10: internal IME characters and geta mark)
In EACC, this row includes several Private Use Area mapped characters used internally to represent character components by the RLIN input method,[18] which is used by the Library of Congress for non-Roman cataloging.[19] These component characters should only be used internally by an IME and, if encountered elsewhere, may be replaced with the geta mark (U+3013),[18] which this row also includes at 0x212A46. This row is unassigned in CCCII,[1] but the geta mark is also listed at that location in some mappings for CCCII.[10]
| EACC[14] (prefixed with 0x212A) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | � | � | � | � | � | � | � | � | � | � | � | � | � | � | ||
| 3x | � | � | � | � | � | � | � | � | � | � | � | � | � | � | � | |
| 4x | � | � | � | � | � | � | 〓 | |||||||||
| 5x | ||||||||||||||||
| 6x | ||||||||||||||||
| 7x | ||||||||||||||||
Character set 0x212B (plane 1, row 11: punctuation)
This row contains various punctuation marks used in Chinese,[1][8] in addition to other symbols. CCCII includes a set of 35 punctuation marks in this row.[1] EACC includes only 13 characters in this row (shown boxed below).[8]
| CCCII/EACC[14][10][16] (prefixed with 0x212B) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ︵ | ︶ | ﹁ | ﹂ | 「 | 」 | ︳ | _ | ﹃ | ﹄ | 『 | 』 | ︴ | ﹏ | ︹ | |
| 3x | ︺ | 〔/[ | 〕/] | 。 | ・/. | 、 | ⋮ | ⋯ | , | ; | : | ? | ︱ | ! | ︲ | ︱ |
| 4x | ‘ | ’ | “ | ” | 《 | 》 | 【 | 】 | 〖 | 〗 | ||||||
| 5x | $ | ¢ | ₡ | £ | ¥ | ₨ | d. | s. | / | # | % | ⅌ | @ | ¶ | ® | |
| 6x | © | ℅ | & | § | † | ‡ | * | |||||||||
| 7x | ヽ | ヾ | ゝ | ゞ | α | 〒 | ||||||||||
Character sets 0x212C–0x212E (plane 1, rows 12–14: radicals and ordinals)
These rows contain Chinese radicals,[1] Roman numerals,[10] celestial stems and terrestrial branches.[16]
| CCCII[16] (prefixed with 0x212C) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ⼀ | ⼁ | ⼂ | ⼃ | ⼄ | ⼅ | ⼆ | ⼇ | ⼈ | ⼉ | ⼊ | ⼋ | ⼌ | |||
| 3x | ⼍ | ⼎ | ⼏ | ⼐ | ⼑ | ⼒ | ⼓ | ⼔ | ⼕ | ⼖ | ⼗ | ⼘ | ⼙ | ⼚ | ⼛ | ⼜ |
| 4x | ⼝ | ⼞ | ⼟ | ⼠ | ⼡ | ⼢ | ⼣ | ⼤ | ⼥ | ⼦ | ⼧ | ⼨ | ⼩ | ⼪ | ⼫ | |
| 5x | ⼬ | ⼭ | ⼮ | ⼯ | ⼰ | ⼱ | ⼲ | ⼳ | ⼴ | ⼵ | ⼶ | ⼷ | ⼸ | ⼹ | ⼺ | ⼻ |
| 6x | ⼼ | ⼽ | ⼾ | ⼿ | ⽀ | ⽁ | ⽂ | ⽃ | ⽄ | ⽅ | ⽆ | ⽇ | ⽈ | ⽉ | ⽊ | |
| 7x | ⽋ | ⽌ | ⽍ | ⽎ | ⽏ | ⽐ | ⽑ | ⽒ | ⽓ | ⽔ | ⽕ | ⽖ | ⽗ | ⽘ | ⽙ | |
| CCCII[9][16] (prefixed with 0x212D) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ⽚ | ⽛ | ⽜ | ⽝ | ⽞ | ⽟ | ⽠ | ⽡ | ⽢ | ⽣ | ⽤ | ⽥ | ⽦ | ⽧ | ||
| 3x | ⽨ | ⽩ | ⽪ | ⽫ | ⽬ | ⽭ | ⽮ | ⽯ | ⽰ | ⽱ | ⽲ | ⽳ | ⽴ | ⽵ | ⽶ | |
| 4x | ⽷ | ⽸ | ⽹ | ⽺ | ⽻ | ⽼ | ⽽ | ⽾ | ⽿ | ⾀ | ⾁ | ⾂ | ⾃ | ⾄ | ⾅ | ⾆ |
| 5x | ⾇ | ⾈ | ⾉ | ⾊ | ⾋ | ⾌ | ⾍ | ⾎ | ⾏ | ⾐ | ⾑ | ⾒ | ⾓ | ⾔/訁 | ⾕ | |
| 6x | ⾖ | ⾗ | ⾘ | ⾙ | ⾚ | ⾛ | ⾜ | ⾝ | ⾞ | ⾟ | ⾠ | ⾡ | ⾢ | ⾣ | ⾤ | ⾥ |
| 7x | ⾦/釒 | ⾧ | ⾨ | ⾩ | ⾪ | ⾫ | ⾬ | ⾭ | ⾮ | ⾯ | ⾰ | ⾱ | ⾲ | |||
| CCCII[10][9][16] (prefixed with 0x212E) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ⾳ | ⾴ | ⾵ | ⾶ | ⾷/飠 | ⾸ | ⾹ | ⾺ | ⾻ | ⾼ | ⾽ | ⾾ | ⾿ | ⿀ | ||
| 3x | ⿁ | ⿂ | ⿃ | ⿄ | ⿅ | ⿆ | ⿇ | ⿈ | ⿉ | ⿊ | ⿋ | ⿌ | ⿍ | |||
| 4x | ⿎ | ⿏ | ⿐ | ⿑ | ⿒ | ⿓ | ⿔ | ⿕ | ||||||||
| 5x | 甲 | 乙 | 丙 | 丁 | 戊 | 己 | 庚 | 辛 | 壬 | 癸 | ||||||
| 6x | 子 | 丑 | 寅 | 卯 | 辰 | 巳 | 午 | 未 | 申 | 酉 | 戌 | 亥 | ||||
| 7x | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ | Ⅺ | Ⅻ | ||||
Character set 0x212F (plane 1, row 15: Chinese numerals and bopomofo)
This row includes Chinese numerals and bopomofo characters.[1] EACC includes only the ideographic zero (〇).[8]
| CCCII/EACC[14][16][10] (prefixed with 0x212F) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | 〡 | 〢 | 〣 | 〤 | 〥 | 〦 | 〧 | 〨 | 〩 | 〸 | 〹 | 〺 | ||||
| 3x | 〇 | 一 | 二 | 三 | 四 | 五 | 六 | 七 | 八 | 九 | 十 | 百 | 千 | 万 | ||
| 4x | 零 | 壹 | 貳 | 參 | 肆 | 伍 | 陸 | 柒 | 捌 | 玖 | 拾 | 佰 | 仟 | 萬 | 億 | |
| 5x | ˊ | ˇ | ˋ | ˙/﹒[lower-alpha 3] | ㄅ | ㄆ | ㄇ | ㄈ | ㄉ | ㄊ | ㄋ | ㄌ | ㄍ | ㄎ | ㄏ | ㄐ |
| 6x | ㄑ | ㄒ | ㄓ | ㄔ | ㄕ | ㄖ | ㄗ | ㄘ | ㄙ | ㄚ | ㄛ | ㄜ | ㄝ | ㄞ | ㄟ | ㄠ |
| 7x | ㄡ | ㄢ | ㄣ | ㄤ | ㄥ | ㄦ | ㄧ | ㄨ | ㄩ | ü | ||||||
Character set 0x272B (plane 7, row 11: reference mark)
This row contains the reference mark (kome jirushi).[10]
| CCCII[10] (prefixed with 0x272B) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 6x | ※ | |||||||||||||||
Character set 0x272E–0x272F (plane 7, rows 14–15: alternative bopomofo)
A variant used by libraries in Hong Kong does not include bopomofo characters in plane 1 row 15, but includes them in a different layout in plane 7.[9]
| CCCII (Hong Kong)[9] (prefixed with 0x272E) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 7x | ㄅ | ㄆ | ㄇ | ㄈ | ㄉ | ㄊ | ㄋ | ㄌ | ㄍ | ㄎ | ||||||
| CCCII (Hong Kong) (prefixed with 0x272F) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ㄏ | ㄐ | ㄑ | ㄒ | ㄓ | ㄔ | ㄕ | ㄖ | ㄗ | ㄘ | ㄙ | ㄚ | ㄛ | ㄜ | ㄝ | |
| 3x | ㄞ | ㄟ | ㄠ | ㄡ | ㄢ | ㄣ | ㄤ | ㄥ | ㄦ | ㄧ | ㄨ | ㄩ | ||||
Character set 0x6921 (plane 73, row 1: Japanese punctuation)
This row is in plane 73, the first plane of layer 13, which contains characters included for Japanese language support.[13] It contains punctuation.[8] Compare row 1 of JIS X 0208, which this row tends to follow the layout of for the characters it includes.
| CCCII/EACC[14][10][9] (prefixed with 0x6921) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ・ | |||||||||||||||
| 3x | 々 | 〆 | ー | |||||||||||||
| 4x | ||||||||||||||||
| 5x | 〈 | 〉 | 《 | 》 | ||||||||||||
| 6x | ||||||||||||||||
| 7x | ||||||||||||||||
Character set 0x6924 (plane 73, row 4: hiragana)
This row contains hiragana. Compare row 4 of JIS X 0208.
| CCCII/EACC[14][10][9] (prefixed with 0x6924) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ぁ | あ | ぃ | い | ぅ | う | ぇ | え | ぉ | お | か | が | き | ぎ | く | |
| 3x | ぐ | け | げ | こ | ご | さ | ざ | し | じ | す | ず | せ | ぜ | そ | ぞ | た |
| 4x | だ | ち | ぢ | っ | つ | づ | て | で | と | ど | な | に | ぬ | ね | の | は |
| 5x | ば | ぱ | ひ | び | ぴ | ふ | ぶ | ぷ | へ | べ | ぺ | ほ | ぼ | ぽ | ま | み |
| 6x | む | め | も | ゃ | や | ゅ | ゆ | ょ | よ | ら | り | る | れ | ろ | ゎ | わ |
| 7x | ゐ | ゑ | を | ん | ||||||||||||
Character set 0x6925 (plane 73, row 5: katakana)
This row contains katakana. Compare row 5 of JIS X 0208, which this row corresponds to, besides the addition of the separate dakuten and handakuten.
| CCCII/EACC[14][10] (prefixed with 0x6925) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ァ | ア | ィ | イ | ゥ | ウ | ェ | エ | ォ | オ | カ | ガ | キ | ギ | ク | |
| 3x | グ | ケ | ゲ | コ | ゴ | サ | ザ | シ | ジ | ス | ズ | セ | ゼ | ソ | ゾ | タ |
| 4x | ダ | チ | ヂ | ッ | ツ | ヅ | テ | デ | ト | ド | ナ | ニ | ヌ | ネ | ノ | ハ |
| 5x | バ | パ | ヒ | ビ | ピ | フ | ブ | プ | ヘ | ベ | ペ | ホ | ボ | ポ | マ | ミ |
| 6x | ム | メ | モ | ャ | ヤ | ュ | ユ | ョ | ヨ | ラ | リ | ル | レ | ロ | ヮ | ワ |
| 7x | ヰ | ヱ | ヲ | ン | ヴ | ヵ | ヶ | ◌゙/゛ | ◌゚/゜ | |||||||
Character set 0x6F24–0x6F25 (plane 79, rows 4–5: jamo)
These rows contains Korean jamo.
| EACC[14] (prefixed with 0x6F24) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 5x | ㄱ | ㄴ | ㄷ | ㄹ | ㅁ | ㅂ | ㅅ | ㅇ | ㅈ | |||||||
| 6x | ㅊ | ㅋ | ㅌ | ㅍ | ㅎ | ㄲ | ㄸ | ㅃ | ||||||||
| 7x | ㅆ | ㅉ | ㅏ | ㅐ | ㅑ | ㅓ | ㅔ | ㅕ | ㅗ | ㅘ | ㅛ | |||||
| EACC[14] (prefixed with 0x6F25) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ㅜ | ㅠ | ㅡ | ㅢ | ㅣ | |||||||||||
Character set 0x6F76 (plane 79, row 86: archaic Hangul)
This row contains several historic Hangul characters no longer in regular use. Several of these are mapped to the Private Use Area.[18]
| EACC[14] (prefixed with 0x6F76) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2x | ㆁ | ㆆ | ㅿ | � | ㆍ | |||||||||||
| 3x | ||||||||||||||||
| 4x | � | � | � | � | � | � | � | � | � | � | � | � | � | � | � | � |
| 5x | � | � | � | � | � | � | � | � | ||||||||
| 6x | ||||||||||||||||
| 7x | ||||||||||||||||
Character set 0x7B25 (plane 91, row 5: supplementary Katakana)
This row contains additional katakana used to write foreign phonemes.[10]
| CCCII[10] (prefixed with 0x7B25) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 7x | ヷ | ヸ | ヹ | |||||||||||||
See also
Footnotes
- ↑ Outside of the trail byte range of an ISO 2022 94n set, but noted as being in use by some implementations.[8]
- ↑ Coding of the ideographic space specified in the ANSI standard for EACC.[8] This is used as an exclamation mark in CCCII,[10] in addition to the exclamation mark at 0x212B3D.[16] The Hong Kong HKIUG variant of CCCII follows EACC here.[9]
- ↑ The Encode::HanExtra mappings use U+FE52 for this character.[10] However, it appears here following ˊ, ˇ and ˋ,[16] which the other three tone marks for bopomofo. The mapping U+02D9 is more commonly used for this tone mark in bopomofo ranges of encodings, for example Big5.[20]
References
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Lunde, Ken (2009). CJKV Information Processing: Chinese, Japanese, Korean & Vietnamese Computing (2nd ed.). Sebastopol, CA: O'Reilly. pp. 122–124. ISBN 978-0-596-51447-1.
- 1 2 3 Tang, Audrey (2007-11-10). "Encode::HanExtra - Extra sets of Chinese encodings".
CCCII: The earliest (and most sophisticated) Traditional Chinese encoding... used mostly in library systems.... Map for "CCCII" is supplied by the Koha Taiwan project.
- 1 2 3 4 Wittern, Christian (1995-05-01). "Chinese character codes: an update". International Research Institute for Zen Buddhism / Hanazono University. Archived from the original on 2004-10-12.
- 1 2 3 Jenkins, John H.; Cook, Richard; Lunde, Ken (2020-03-05). "Unicode Han Database (Unihan)". Unicode Standard Annex #38.
- ↑ "Archived copy". Archived from the original on 2016-06-15. Retrieved 2016-06-15.
{{cite web}}: CS1 maint: archived copy as title (link) - 1 2 3 "Appendix E: Han Unification History" (PDF). The Unicode Standard Version 15.0 – Core Specification. Unicode Consortium. 2022.
- ↑ Kangxi Dictionary, p. 1296, char. 1
- 1 2 3 4 5 6 7 8 9 10 Library of Congress (2007-12-05). "Code Table East Asian Punctuation Marks". MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Hong Kong Innovative Users Group Unicode Task Force. "HKIUG Code Table for CJK Characters: Mapping to Unicode". University of Hong Kong Libraries.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Tang, Audrey; Koha Taiwan. "Map for CCCII". Encode::HanExtra. CPAN.
- ↑ "2.4: Multiple byte graphic character sets". International Register of Coded Character Sets to be Used With Escape Sequences (ISO-IR) (PDF). ITSCJ/IPSJ. p. 14.
- ↑ Library of Congress (2007-12-05). "Technique 2: Using standard alternate graphic character sets". MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- 1 2 3 Lunde, Ken (1995-12-18). "2.5.2: CCCII". CJK.INF Version 1.9.
- 1 2 3 4 5 6 7 8 9 10 11 12 Library of Congress (2007-12-05). "East Asian Code Tables". MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- ↑ Library of Congress (2007-12-05). "Code Table Korean Hangul". MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- 1 2 3 4 5 6 7 8 9 10 Characters shown are, in part, cross-referenced against a representative BDF font for CCCII, distributed by Koichi Yasuoka of Kyoto University.
- ↑ Hong Kong Innovative Users Group (2013-01-07). "Introduction to Hong Kong Innovative Users Group". University of Hong Kong Libraries.
- 1 2 3 Library of Congress (2004-09-02). "Summary List of MARC 21 Characters Assigned to the Private Use Area (PUA)". MARC 21 Specifications for Record Structure, Character Sets, and Exchange Media.
- ↑ Morris, Susan (2007). "Finding JACKPHY: Online Cataloging to Include Arabic, Hebrew, Other Scripts". Library of Congress Information Bulletin. Vol. 66, no. 12.
- ↑ van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
{kind=link}
- Some information on this page is based on the information on the CNS official website.
External links
- CNS 11643 official web site (English version of pages available) has information about the CCCII character set in the "Chinese Information Code" section
- Full mapping of EACC to Unicode, from Library of Congress
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |