注意力机制
注意力机制(英語:)是人工神经网络中一种模仿认知注意力的技术。这种机制可以增强神经网络输入数据中某些部分的权重,同时减弱其他部分的权重,以此将网络的关注点聚焦于数据中最重要的一小部分。数据中哪些部分比其他部分更重要取决于上下文。可以通过梯度下降法对注意力机制进行训练。
| 机器学习与 |
|---|
类似于注意力机制的架构最早于1990年代提出,当时提出的名称包括乘法模块(multiplicative module)、sigma pi单元、超网络(hypernetwork)等。[1]注意力机制的灵活性来自于它的“软权重”特性,即这种权重是可以在运行时改变的,而非像通常的权重一样必须在运行时保持固定。注意力机制的用途包括神经图灵机中的记忆功能、可微分神经计算机中的推理任务[2]、Transformer模型中的语言处理、Perceiver(感知器)模型中的多模态数据处理(声音、图像、视频和文本)。[3][4][5][6]
概述
假设我们有一个以索引排列的标记(token)序列。对于每一个标记,神经网络计算出一个相应的满足的非负软权重。每个标记都对应一个由词嵌入得到的向量。加权平均即是注意力机制的输出结果。





可以使用查询-键机制(query-key mechanism)计算软权重。从每个标记的词嵌入,我们计算其对应的查询向量和键向量。再计算点积的softmax函数便可以得到对应的权重,其中代表当前标记、表示与当前标记产生注意力关系的标记。




某些架构中会采用多头注意力机制(multi-head attention),其中每一部分都有独立的查询(query)、键(key)和值(value)。
语言翻译示例
下图展示了将英语翻译成法语的机器,其基本架构为编码器-解码器结构,另外再加上了一个注意力单元。在图示的简单情况下,注意力单元只是循环层状态的点积计算,并不需要训练。但在实践中,注意力单元由需要训练的三个完全连接的神经网络层组成。这 三层分别被称为查询(query)、键(key)和值(value)。
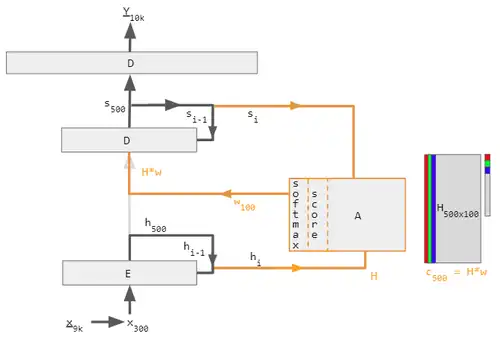 加入注意力机制的编码器-解码器架构。图中使用具体的数值表示向量的大小,使其更为直观。左侧黑色箭头表示的是编码器-解码器,中间橘色箭头表示的是注意力单元,右侧灰色与彩色方块表示的是计算的数据。矩阵H与向量w中的灰色区域表示零值。数值下标表示向量大小。字母下标i与i-1表示计算步。
|
||||||||||||||||||||||||||||||||
|
下表是每一步计算的示例。为清楚起见,表中使用了具体的数值或图形而非字母表示向量与矩阵。嵌套的图形代表了每个h都包含之前所有单词的历史记录。在这里,我们引入注意力分数以得到所需的注意力权重。
| 步 | x | h, H = 编码器输出 大小为500×1的向量,以图形表示 | s = 解码器提供给注意力单元的输入 | 对准分数 | w = 注意力权重 = softmax(分数) | c = 上下文向量 = H*w | y = 解码器输出 |
| 1 | I | - | - | - | - | - | |
| 2 | love | - | - | - | - | - | |
| 3 | you | - | - | - | - | - | |
| 4 | - | - | 解码器尚未初始化,故使用编码器输出h3对其初始化 | [.63 -3.2 -2.5 .5 .5 ...] | [.94 .02 .04 0 0 ...] | .94 * | je |
| 5 | - | - | s4 | [-1.5 -3.9 .57 .5 .5 ...] | [.11 .01 .88 0 0 ...] | .11 * | t' |
| 6 | - | - | s5 | [-2.8 .64 -3.2 .5 .5 ...] | [.03 .95 .02 0 0 ...] | .03 * | aime |
以矩阵展示的注意力权重表现了网络如何根据上下文调整其关注点。
| I | love | you | |
| je | .94 | .02 | .04 |
| t' | .11 | .01 | .88 |
| aime | .03 | .95 | .02 |
对注意力权重的这种展现方式回应了人们经常用来批评神经网络的可解释性问题。对于一个只作逐字翻译而不考虑词序的网络,其注意力权重矩阵会是一个对角占优矩阵。这里非对角占优的特性表明注意力机制能捕捉到更为细微的特征。在第一次通过解码器时,94%的注意力权重在第一个英文单词“I”上,因此网络的输出为对应的法语单词“je”(我)。而在第二次通过解码器时,此时88%的注意力权重在第三个英文单词“you”上,因此网络输出了对应的法语“t'”(你)。最后一遍时,95%的注意力权重在第二个英文单词“love”上,所以网络最后输出的是法语单词“aime”(爱)。
变体
注意力机制有许多变体:点积注意力(dot-product attention)、QKV注意力(query-key-value attention)、强注意力(hard attention)、软注意力(soft attention)、自注意力(self attention)、交叉注意力(cross attention)、Luong注意力、Bahdanau注意力等。这些变体重新组合编码器端的输入,以将注意力效果重新分配到每个目标输出。通常而言,由点积得到的相关式矩阵提供了重新加权系数(参见图例)。
| 1. 编码器-解码器点积 | 2. 编解码器QKV | 3. 编码器点积 | 4. 编码器QKV | 5. Pytorch示例 |
|---|---|---|---|---|
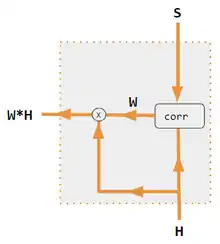 同时需要编码器与解码器来计算注意力。[8] |
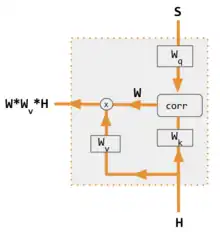 同时需要编码器与解码器来计算注意力。[9] |
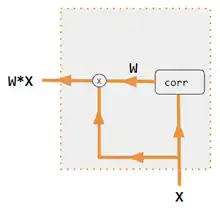 解码器不用于计算注意力。因为只有一个输入,W是自相关点积,即w ij = x i * x j。[10] |
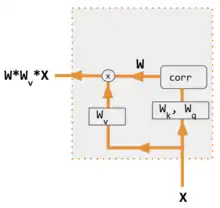 解码器不用于计算注意力。[11] |
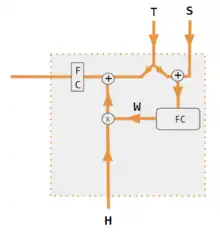 使用FC层而非相关性点积计算注意力。[12] |
| 标签 | 描述 |
|---|---|
| 变量 X,H,S,T | 大写变量代表整句语句,而不仅仅是当前单词。例如,H代表编码器隐状态的矩阵——每列代表一个单词。 |
| S, T | S = 解码器隐状态,T = 目标词嵌入。在 Pytorch示例变体训练阶段,T 在两个源之间交替,具体取决于所使用的教师强制(teacher forcing)级别。 T可以是网络输出词的嵌入,即embedding(argmax(FC output))。或者当使用教师强制进行训练时,T可以是已知正确单词的嵌入。可以指定其发生的概率(如1/2)。 |
| X, H | H = 编码器隐状态,X = 输入词嵌入 |
| W | 注意力系数 |
| Qw, Kw, Vw, FC | 分别用于查询、键、向量的权重矩阵。 FC是一个全连接的权重矩阵。 |
| 带圈+,带圈x | 带圈+ = 向量串联。带圈x = 矩阵乘法 |
| corr | 逐列取softmax(点积矩阵)。点积在变体3中的定义是x i * x j ,在变体1中是h i * s j ,在变体2中是 列i(Kw*H) * 列j (Qw*S),在变体4中是 列i(Kw*X) * 列j (Qw*X)。变体5则使用全连接层来确定系数。对于QKV变体,则点积由 sqrt(d) 归一化,其中d是QKV矩阵的高度。 |
参考文献
- Yann Lecun. . 事件发生在 53:00. 2020 [2022-03-08]. (原始内容存档于2023-07-09).
- Graves, Alex; Wayne, Greg; Reynolds, Malcolm; Harley, Tim; Danihelka, Ivo; Grabska-Barwińska, Agnieszka; Colmenarejo, Sergio Gómez; Grefenstette, Edward; Ramalho, Tiago; Agapiou, John; Badia, Adrià Puigdomènech; Hermann, Karl Moritz; Zwols, Yori; Ostrovski, Georg; Cain, Adam; King, Helen; Summerfield, Christopher; Blunsom, Phil; Kavukcuoglu, Koray; Hassabis, Demis. . Nature. 2016-10-12, 538 (7626): 471–476 [2022-06-07]. Bibcode:2016Natur.538..471G. ISSN 1476-4687. PMID 27732574. S2CID 205251479. doi:10.1038/nature20101. (原始内容存档于2022-10-02) (英语).
- Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia. . 2017-12-05. arXiv:1706.03762
 [cs.CL].
[cs.CL]. - Ramachandran, Prajit; Parmar, Niki; Vaswani, Ashish; Bello, Irwan; Levskaya, Anselm; Shlens, Jonathon. . 2019-06-13. arXiv:1906.05909 [cs.CV].
- Jaegle, Andrew; Gimeno, Felix; Brock, Andrew; Zisserman, Andrew; Vinyals, Oriol; Carreira, Joao. . 2021-06-22. arXiv:2103.03206 [cs.CV].
- Ray, Tiernan. . ZDNet. [2021-08-19]. (原始内容存档于2021-10-29) (英语).
- . [December 2, 2021].
- Luong, Minh-Thang. . 2015-09-20. arXiv:1508.04025v5 [cs.CL].
- Neil Rhodes. . 事件发生在 06:30. 2021 [2021-12-22]. (原始内容存档于2022-10-21).
- Alfredo Canziani & Yann Lecun. . 事件发生在 05:30. 2021 [2021-12-22]. (原始内容存档于2023-03-22).
- Alfredo Canziani & Yann Lecun. . 事件发生在 20:15. 2021 [2021-12-22]. (原始内容存档于2023-03-22).
- Robertson, Sean. . pytorch.org. [2021-12-22].