支持向量机
在机器学习中, (,英語:,常简称為SVM,又名支援向量网络[1])是在分类与迴歸分析中分析数据的監督式學習模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法建立一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
| 机器学习与 |
|---|
除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。
当数据未被标记时,不能进行监督式学习,需要用非監督式學習,它会尝试找出数据到簇的自然聚类,并将新数据映射到这些已形成的簇。将支援向量机改进的聚类算法被称为支援向量聚类[2],当数据未被标记或者仅一些数据被标记时,支援向量聚类经常在工业应用中用作分类步骤的预处理。
动机
.svg.png.webp)
将数据进行分类是机器学习中的一项常见任务。 假设某些给定的数据点各自属于两个类之一,而目标是确定新数据点将在哪个类中。对于支持向量机来说,数据点被视为 维向量,而我们想知道是否可以用 维超平面来分开这些点。这就是所谓的线性分类器。可能有许多超平面可以把数据分类。最佳超平面的一个合理选择是以最大间隔把两个类分开的超平面。因此,我们要选择能够让到每边最近的数据点的距离最大化的超平面。如果存在这样的超平面,则称为最大间隔超平面,而其定义的线性分类器被称为最大间隔分类器,或者叫做最佳稳定性感知器。


定义
更正式地来说,支持向量机在高维或无限维空间中构造超平面或超平面集合,其可以用于分类、回归或其他任务。直觀來說,分類邊界距離最近的訓練資料點越遠越好,因為這樣可以缩小分類器的泛化誤差。

尽管原始问题可能是在有限维空间中陈述的,但用于区分的集合在该空间中往往线性不可分。为此,有人提出将原有限维空间映射到维数高得多的空间中,在该空间中进行分离可能会更容易。为了保持计算负荷合理,人们选择适合该问题的核函数 来定义SVM方案使用的映射,以确保用原始空间中的变量可以很容易计算点积。[3] 高维空间中的超平面定义为与该空间中的某向量的点积是常数的点的集合。定义超平面的向量可以选择在数据集中出现的特征向量 的图像的参数 的线性组合。通过选择超平面,被映射到超平面上的特征空间中的点集 由以下关系定义: 注意,如果随着 逐渐远离 , 变小,则求和中的每一项都是在衡量测试点 与对应的数据基点 的接近程度。这样,上述内核的总和可以用于衡量每个测试点相对于待分离的集合中的数据点的相对接近度。






应用
- 用于文本和超文本的分类,在归纳和直推方法中都可以显著减少所需要的有类标的样本数。
- 用于图像分类。实验结果显示:在经过三到四轮相关反馈之后,比起传统的查询优化方案,支持向量机能够取得明显更高的搜索准确度。这同样也适用于图像分割系统,比如使用Vapnik所建议的使用特权方法的修改版本SVM的那些图像分割系统。[4][5]
- 用于手写字体识别。
- 用于医学中分类蛋白质,超过90%的化合物能够被正确分类。基于支持向量机权重的置换测试已被建议作为一种机制,用于解释的支持向量机模型。[6][7] 支持向量机权重也被用来解释过去的SVM模型。[8] 为识别模型用于进行预测的特征而对支持向量机模型做出事后解释是在生物科学中具有特殊意义的相对较新的研究领域。
历史
原始SVM算法是由蘇聯數學家弗拉基米尔·瓦普尼克和亞歷克塞·澤范蘭傑斯于1963年发明的。1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎贝尔·M·盖昂(Isabelle M. Guyon)和瓦普尼克提出了一种通过将核技巧应用于最大间隔超平面来创建非线性分类器的方法。[9] 当前标准的前身(软间隔)由科琳娜·科特斯和瓦普尼克于1993年提出,并于1995年发表。[1]
线性SVM
我们考虑以下形式的 点测试集:


其中 是 1 或者 −1,表明点 所属的类。 中每个都是一个 维实向量。我们要求将 的点集 与 的点集分开的 “最大间隔超平面”,使得超平面与最近的点 之间的距离最大化。




任何超平面都可以写作满足下面方程的点集

-
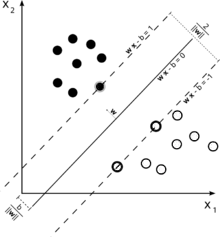 设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在边缘上的样本点称为支持向量。
设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在边缘上的样本点称为支持向量。

其中 (不必是归一化的)是该法向量。参数 决定从原点沿法向量 到超平面的偏移量。


硬间隔
如果这些训练数据是线性可分的,可以选择分离两类数据的两个平行超平面,使得它们之间的距离尽可能大。在这两个超平面范围内的区域称为“间隔”,最大间隔超平面是位于它们正中间的超平面。这些超平面可以由方程:

或是

来表示。通过几何不难得到这两个超平面之间的距离是 ,因此要使两平面间的距离最大,我们需要最小化 。同时为了使得样本数据点都在超平面的间隔区以外,我们需要保证对于所有的 满足其中的一个条件:



- 若

或是
- 若


这些约束表明每个数据点都必须位于间隔的正确一侧。
这两个式子可以写作:

可以用这个式子一起来得到优化问题:
“在 条件下,最小化 ,对于 "


这个问题的解 与 决定了我们的分类器 。


此几何描述的一个显而易见却重要的结果是,最大间隔超平面完全是由最靠近它的那些 确定的。这些 叫做支持向量。
软间隔
为了将SVM扩展到数据线性不可分的情况,我们引入铰链损失函数,

当约束条件 (1) 满足时(也就是如果 位于边距的正确一侧)此函数为零。对于间隔的错误一侧的数据,该函数的值与距间隔的距离成正比。 然后我们希望最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\vec {w}}\cdot {\vec {x_{i}}}-b)\right)\right]+\lambda \lVert {\vec {w}}\rVert ^{2},}](../I/edfd21a4d3cb290e872f527487f0df3d29a90ce7.svg)
其中参数 用来权衡增加间隔大小与确保 位于间隔的正确一侧之间的关系。因此,对于足够小的 值,如果输入数据是可以线性分类的,则软间隔SVM与硬间隔SVM将表现相同,但即使不可线性分类,仍能学习出可行的分类规则。

非线性分类
弗拉基米尔·瓦普尼克在1963年提出的原始最大间隔超平面算法构造了一个线性分类器。而1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎贝尔·M·盖昂(Isabelle M. Guyon)和瓦普尼克提出了一种通过将核技巧(最初由Aizerman et al.[10]提出)应用于最大边界超平面来创建非线性分类器的方法。[11] 所得到的算法形式上类似,除了把点积换成了非线性核函数。这就允许算法在变换后的特征空间中拟合最大间隔超平面。该变换可以是非线性的,而变换空间是高维的;虽然分类器是变换后的特征空间中的超平面,但它在原始输入空间中可以是非线性的。
值得注意的是,更高维的特征空间增加了支持向量机的泛化误差,但给定足够多的样本,算法仍能表现良好。[12]
常见的核函数包括:








由等式 ,核函数与变换 有关。变换空间中也有 w 值,。与 w 的点积也要用核技巧来计算,即 。




计算SVM分类器
计算(软间隔)SVM分类器等同于使下面表达式最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.\qquad (2)}](../I/80a65393b87bcf565f42cdc02cf9caafe49ec14a.svg)
如上所述,由于我们关注的是软间隔分类器, 选择足够小的值就能得到线性可分类输入数据的硬间隔分类器。下面会详细介绍将(2)简化为二次规划问题的经典方法。之后会讨论一些最近才出现的方法,如次梯度下降法和坐标下降法。
原型
最小化(2)可以用下面的方式改写为目标函数可微的约束优化问题。
对所有 我们引入变量 。注意到 是满足 的最小非负数。




因此,我们可以将优化问题叙述如下


这就叫做原型问题。
对偶型
通过求解上述问题的拉格朗日对偶,得到简化的问题


这就叫做对偶问题。由于对偶最小化问题是受线性约束的 的二次函数,所以它可以通过二次规划算法高效地解出。 这里,变量 定义为满足

.

此外,当 恰好在间隔的正确一侧时 ,且当 位于间隔的边界时 。因此, 可以写为支持向量的线性组合。 可以通过在间隔的边界上找到一个 并求解



得到偏移量 。(注意由于 因而 。)


核技巧
假设我们要学习与变换后数据点 的线性分类规则对应的非线性分类规则。此外,我们有一个满足 的核函数 。



我们知道变换空间中的分类向量 满足

其中 可以通过求解优化问题

得到。与前面一样,可以使用二次规划来求解系数 。同样,我们可以找到让 的索引 ,使得 位于变换空间中间隔的边界上,然后求解
![{\displaystyle {\begin{aligned}b={\vec {w}}\cdot \varphi ({\vec {x}}_{i})-y_{i}&=\left[\sum _{k=1}^{n}c_{k}y_{k}\varphi ({\vec {x}}_{k})\cdot \varphi ({\vec {x}}_{i})\right]-y_{i}\\&=\left[\sum _{k=1}^{n}c_{k}y_{k}k({\vec {x}}_{k},{\vec {x}}_{i})\right]-y_{i}.\end{aligned}}}](../I/beb6300a0eb50faa0574ba613a7e960b612aaf91.svg)
最后,可以通过计算下式来分类新点
![{\displaystyle {\vec {z}}\mapsto \operatorname {sgn}({\vec {w}}\cdot \varphi ({\vec {z}})+b)=\operatorname {sgn} \left(\left[\sum _{i=1}^{n}c_{i}y_{i}k({\vec {x}}_{i},{\vec {z}})\right]+b\right).}](../I/122836b654fa6e79b1e5f4250eeb07695c217198.svg)
现代方法
用于找到SVM分类器的最近的算法包括次梯度下降和坐标下降。当处理大的稀疏数据集时,这两种技术已经被证明有着显著的优点——当存在许多训练实例时次梯度法是特别有效的,并且当特征空间的维度高时,坐标下降特别有效。
![{\displaystyle f({\vec {w}},b)=\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.}](../I/1025985789e0160e43d58d13fc27bda0f5ab9296.svg)



性质
SVM属于广义线性分类器的一族,并且可以解释为感知器的延伸。它们也可以被认为是吉洪诺夫正则化的特例。它们有一个特别的性质,就是可以同时最小化经验误差和最大化几何边缘区; 因此它们也被称为最大间隔分类器。
Meyer、Leisch和Hornik对SVM与其他分类器进行了比较。[15]
参数选择
SVM的有效性取决于核函数、核参数和软间隔参数 C 的选择。 通常会选只有一个参数 的高斯核。C 和 的最佳组合通常通过在 C 和 为指数增长序列下网格搜索来选取,例如 ; 。通常情况下,使用交叉驗證来检查参数选择的每一个组合,并选择具有最佳交叉验证精度的参数。或者,最近在贝叶斯优化中的工作可以用于选择C和γ,通常需要评估比网格搜索少得多的参数组合。或者,贝叶斯优化的最近进展可以用于选择 C 和 ,通常需要计算的参数组合比网格搜索少得多。然后,使用所选择的参数在整个训练集上训练用于测试和分类新数据的最终模型。[16]



问题
SVM的潜在缺点包括以下方面:
- 需要对输入数据进行完全标记
- 未校准类成员概率
- SVM仅直接适用于两类任务。因此,必须应用将多类任务减少到几个二元问题的算法;请参阅多类SVM一节。
- 解出的模型的参数很难理解。
延伸
- 支持向量聚類:支持向量聚類是一種建立在核函數上的類似方法,同適用於非監督學習和數據挖掘。它被認為是數據科學中的一種基本方法。
- 轉導支持向量機
- 多元分類支持向量機:SVM算法最初是為二值分類問題設計的,實現多分類的主要方法是將一個多分類問題轉化為多個二分類問題。常見方法包括“一對多法”和“一對一法”,一對多法是將某個類別的樣本歸為一類,其他剩餘的樣本歸為另一類,這樣k個類別的樣本就構造出了k個二分類SVM;一對一法則是在任意兩類樣本之間設計一個SVM。
- 支持向量回歸
- 結構化支持向量機:支持向量機可以被推廣為結構化的支持向量機,推廣後標籤空間是結構化的並且可能具有無限的大小。
实现
最大间隔超平面的参数是通过求解优化得到的。有几种专门的算法可用于快速解决由SVM产生的QP问题,它们主要依靠启发式算法将问题分解成更小、更易于处理的子问题。
另一种方法是使用内点法,其使用类似牛顿法的迭代找到卡羅需-庫恩-塔克條件下原型和对偶型的解。[17] 这种方法不是去解决一系列分解问题,而是直接完全解决该问题。为了避免求解核矩阵很大的线性系统,在核技巧中经常使用矩阵的低秩近似。
另一个常见的方法是普莱特的序列最小优化算法(SMO),它把问题分成了若干个可以解析求解的二维子问题,这样就可以避免使用数值优化算法和矩阵存储。[18]
线性支持向量机的特殊情况可以通过用于优化其类似问题邏輯斯諦迴歸的同类算法更高效求解;这类算法包括次梯度下降法(如PEGASOS[19])和坐标下降法(如LIBLINEAR[20])。LIBLINEAR有一些引人注目的训练时间上的特性。每次收敛迭代花费在读取训练数据上的时间是线性的,而且这些迭代还具有Q-线性收敛特性,使得算法非常快。
一般的核SVM也可以用次梯度下降法(P-packSVM[21])更快求解,在允许并行化时求解速度尤其快。
许多机器学习工具包都可以使用核SVM,有LIBSVM、MATLAB、SAS[22]、SVMlight、kernlab[23]、scikit-learn、Shogun、Weka、Shark[24]、JKernelMachines[25]、OpenCV等。
参考文献
引用
- Cortes, C.; Vapnik, V. . Machine Learning. 1995, 20 (3): 273–297. doi:10.1007/BF00994018.
- Ben-Hur, Asa, Horn, David, Siegelmann, Hava, and Vapnik, Vladimir; "Support vector clustering" (2001) Journal of Machine Learning Research, 2: 125–137.
-
- Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, B. P. . 3rd. New York: Cambridge University Press. 2007 [2016-11-06]. ISBN 978-0-521-88068-8. (原始内容存档于2011-08-11).
- Vapnik, V.: Invited Speaker. IPMU Information Processing and Management 2014)
- Barghout, Lauren. "Spatial-Taxon Information Granules as Used in Iterative Fuzzy-Decision-Making for Image Segmentation." Granular Computing and Decision-Making. Springer International Publishing, 2015. 285-318.
- Bilwaj Gaonkar, Christos Davatzikos Analytic estimation of statistical significance maps for support vector machine based multi-variate image analysis and classification
- R. Cuingnet, C. Rosso, M. Chupin, S. Lehéricy, D. Dormont, H. Benali, Y. Samson and O. Colliot, Spatial regularization of SVM for the detection of diffusion alterations associated with stroke outcome, Medical Image Analysis, 2011, 15 (5): 729–737
- Statnikov, A., Hardin, D., & Aliferis, C. (2006). Using SVM weight-based methods to identify causally relevant and non-causally relevant variables. sign, 1, 4.
- Boser, B. E.; Guyon, I. M.; Vapnik, V. N. . . 1992: 144. ISBN 089791497X. doi:10.1145/130385.130401.
- Aizerman, Mark A.; Braverman, Emmanuel M. & Rozonoer, Lev I. . Automation and Remote Control. 1964, 25: 821–837.
- Boser, B. E.; Guyon, I. M.; Vapnik, V. N. . . 1992: 144. ISBN 089791497X. doi:10.1145/130385.130401.
- Jin, Chi; Wang, Liwei. . Advances in Neural Information Processing Systems. 2012 [2016-11-06]. (原始内容存档于2015-04-02).
- Shalev-Shwartz, Shai; Singer, Yoram; Srebro, Nathan; Cotter, Andrew. . Mathematical Programming. 2010-10-16, 127 (1): 3–30 [2016-11-06]. ISSN 0025-5610. doi:10.1007/s10107-010-0420-4. (原始内容存档于2016-08-25).
- Hsieh, Cho-Jui; Chang, Kai-Wei; Lin, Chih-Jen; Keerthi, S. Sathiya; Sundararajan, S. . Proceedings of the 25th International Conference on Machine Learning. ICML '08 (New York, NY, USA: ACM). 2008-01-01: 408–415. ISBN 978-1-60558-205-4. doi:10.1145/1390156.1390208.
- Meyer, D.; Leisch, F.; Hornik, K. . Neurocomputing. 2003, 55: 169. doi:10.1016/S0925-2312(03)00431-4.
- Hsu, Chih-Wei; Chang, Chih-Chung & Lin, Chih-Jen. (PDF) (技术报告). Department of Computer Science and Information Engineering, National Taiwan University. 2003 [2016-11-06]. (原始内容存档 (PDF)于2013-06-25).
- Ferris, M. C.; Munson, T. S. . SIAM Journal on Optimization. 2002, 13 (3): 783. doi:10.1137/S1052623400374379.
- John C. Platt. (PDF). NIPS. 1998 [2016-11-06]. (原始内容存档 (PDF)于2015-07-02).
- Shai Shalev-Shwartz; Yoram Singer; Nathan Srebro. (PDF). ICML. 2007 [2016-11-06]. (原始内容存档 (PDF)于2013-12-15).
- R.-E. Fan; K.-W. Chang; C.-J. Hsieh; X.-R. Wang; C.-J. Lin. . Journal of Machine Learning Research. 2008, 9: 1871–1874.
- Zeyuan Allen Zhu; et al. (PDF). ICDM. 2009 [2016-11-06]. (原始内容存档 (PDF)于2014-04-07).
- SAS (页面存档备份,存于)
- kernlab
- Shark (页面存档备份,存于)
- JKernelMachines (页面存档备份,存于)
来源
- Theodoridis, Sergios; and Koutroumbas, Konstantinos; "Pattern Recognition", 4th Edition, Academic Press, 2009, ISBN 978-1-59749-272-0
- Cristianini, Nello; and Shawe-Taylor, John; An Introduction to Support Vector Machines and other kernel-based learning methods, Cambridge University Press, 2000. ISBN 0-521-78019-5 (SVM Book)
- Huang, Te-Ming; Kecman, Vojislav; and Kopriva, Ivica (2006); Kernel Based Algorithms for Mining Huge Data Sets (页面存档备份,存于), in Supervised, Semi-supervised, and Unsupervised Learning, Springer-Verlag, Berlin, Heidelberg, 260 pp. 96 illus., Hardcover, ISBN 3-540-31681-7
- Kecman, Vojislav; Learning and Soft Computing — Support Vector Machines, Neural Networks, Fuzzy Logic Systems (页面存档备份,存于), The MIT Press, Cambridge, MA, 2001.
- Schölkopf, Bernhard; and Smola, Alexander J.; Learning with Kernels, MIT Press, Cambridge, MA, 2002. ISBN 0-262-19475-9
- Schölkopf, Bernhard; Burges, Christopher J. C.; and Smola, Alexander J. (editors); Advances in Kernel Methods: Support Vector Learning, MIT Press, Cambridge, MA, 1999. ISBN 0-262-19416-3.
- Shawe-Taylor, John; and Cristianini, Nello; Kernel Methods for Pattern Analysis (页面存档备份,存于), Cambridge University Press, 2004. ISBN 0-521-81397-2 (Kernel Methods Book)
- Steinwart, Ingo; and Christmann, Andreas; Support Vector Machines, Springer-Verlag, New York, 2008. ISBN 978-0-387-77241-7 (SVM Book)
- Tan, Peter Jing; and Dowe, David L. (页面存档备份,存于) (2004); MML Inference of Oblique Decision Trees (页面存档备份,存于), Lecture Notes in Artificial Intelligence (LNAI) 3339, Springer-Verlag, pp. 1082–1088. (This paper uses minimum message length (MML) and actually incorporates probabilistic support vector machines in the leaves of decision trees.)
- Vapnik, Vladimir N.; The Nature of Statistical Learning Theory, Springer-Verlag, 1995. ISBN 0-387-98780-0
- Vapnik, Vladimir N.; and Kotz, Samuel; Estimation of Dependences Based on Empirical Data, Springer, 2006. ISBN 0-387-30865-2, 510 pages [this is a reprint of Vapnik's early book describing philosophy behind SVM approach. The 2006 Appendix describes recent development].
- Fradkin, Dmitriy; and Muchnik, Ilya; Support Vector Machines for Classification in Abello, J.; and Carmode, G. (Eds); Discrete Methods in Epidemiology, DIMACS Series in Discrete Mathematics and Theoretical Computer Science, volume 70, pp. 13–20, 2006. Succinctly describes theoretical ideas behind SVM.
- Bennett, Kristin P.; and Campbell, Colin; Support Vector Machines: Hype or Hallelujah? (页面存档备份,存于), SIGKDD Explorations, 2, 2, 2000, 1–13. Excellent introduction to SVMs with helpful figures.
- Ivanciuc, Ovidiu; Applications of Support Vector Machines in Chemistry (页面存档备份,存于), in Reviews in Computational Chemistry, Volume 23, 2007, pp. 291–400.
- Catanzaro, Bryan; Sundaram, Narayanan; and Keutzer, Kurt; Fast Support Vector Machine Training and Classification on Graphics Processors, in International Conference on Machine Learning, 2008
- Campbell, Colin; and Ying, Yiming; Learning with Support Vector Machines (页面存档备份,存于), 2011, Morgan and Claypool. ISBN 978-1-60845-616-1.
- Ben-Hur, Asa, Horn, David, Siegelmann, Hava, and Vapnik, Vladimir; "Support vector clustering" (2001) Journal of Machine Learning Research, 2: 125–137.
外部链接
- www.support-vector.net The key book about the method, "An Introduction to Support Vector Machines" with online software
- Burges, Christopher J. C.; A Tutorial on Support Vector Machines for Pattern Recognition (页面存档备份,存于), Data Mining and Knowledge Discovery 2:121–167, 1998
- www.kernel-machines.org (页面存档备份,存于) (general information and collection of research papers)
- www.support-vector-machines.org (页面存档备份,存于) (Literature, Review, Software, Links related to Support Vector Machines — Academic Site)
- svmtutorial.online (页面存档备份,存于) A simple introduction to SVM, easily accessible to anyone with basic background in mathematics
- videolectures.net (页面存档备份,存于) (SVM-related video lectures)
- Karatzoglou, Alexandros et al.; Support Vector Machines in R (页面存档备份,存于), Journal of Statistical Software April 2006, Volume 15, Issue 9.
- libsvm (页面存档备份,存于), LIBSVM is a popular library of SVM learners
- liblinear (页面存档备份,存于) is a library for large linear classification including some SVMs
- Shark is a C++ machine learning library implementing various types of SVMs
- dlib (页面存档备份,存于) is a C++ library for working with kernel methods and SVMs
- SVM light is a collection of software tools for learning and classification using SVM
- SVMJS live demo (页面存档备份,存于) is a GUI demo for JavaScript implementation of SVMs
- Gesture Recognition Toolkit (页面存档备份,存于) contains an easy to use wrapper for libsvm (页面存档备份,存于)