DBSCAN
DBSCAN(英語:),是1996年由馬丁·愛胥特、漢斯-彼得·克里戈爾、約爾格·桑德(Jörg Sander)及Xiaowei Xu提出的聚類分析算法, 這個算法是以密度為本的:給定某空間裡的一個點集合,這算法能把附近的點分成一組(有很多相鄰點的點),並標記出位於低密度區域的局外點(最接近它的點也十分遠),DBSCAN是其中一個最常用的聚類分析算法,也是其中一個科學文章中最常引用的。
| 机器学习与 |
|---|
在2014年,這個算法在領頭數據挖掘會議KDD上獲頒發了Test of Time award,該獎項是頒發給一些於理論及實際層面均獲得持續性的關注的算法。
基礎知識
考慮在某空間裡將被聚類的點集合,為了進行 DBSCAN 聚類,所有的點被分為核心點、(密度)可達點及局外點,詳請如下:
- 如果一個點 p 在距離 ε 範圍內有至少 minPts 個點(包括自己),則這個點被稱為核心點,那些 ε 範圍內的則被稱為由 p 直接可達的。根據定義,沒有任何點是由非核心點直接可達的。
- 如果存在一條道路 p1, ..., pn ,有 p1 = p和pn = q, 且每個 pi+1 都是由 pi 直接可達的(道路上除了 q 以外所有點都一定是核心點),則稱 q 是由 p 可達的。
- 所有不由任何點可達的點都被稱為局外點。
如果 p 是核心點,則它與所有由它可達的點(包括核心點和非核心點)形成一個聚類,每個聚類擁有最少一個核心點,非核心點也可以是聚類的一部分,但它是在聚類的「邊緣」位置,因為它不能達至更多的點。
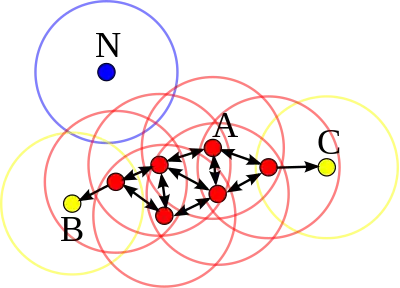
「可達性」(英文:Reachability )不是一個對稱關係,因為根據定義,沒有點是由非核心點可達的,但非核心點可以是由其他點可達的。所以為了正式地界定 DBSCAN 找出的聚類,進一步定義兩點之間的「連結性」(英文:Connectedness) :如果存在一個點 o 使得點 p 和點 q 都是由 o 可達的,則點 p 和點 q 被稱為(密度)連結的,而連結性是一個對稱關係。
定義了連結性之後,每個聚類都符合兩個性質:
- 一個聚類裡的每兩個點都是互相連結的;
- 如果一個點 p 是由一個在聚類裡的點 q 可達的,那麼 p 也在 q 所屬的聚類裡。
算法
DBSCAN 需要兩個參數:ε (eps) 和形成高密度區域所需要的最少點數 (minPts),它由一個任意未被訪問的點開始,然後探索這個點的 ε-鄰域,如果 ε-鄰域裡有足夠的點,則建立一個新的聚類,否則這個點被標籤為雜音。注意這個點之後可能被發現在其它點的 ε-鄰域裡,而該 ε-鄰域可能有足夠的點,屆時這個點會被加入該聚類中。
如果一個點位於一個聚類的密集區域裡,它的 ε-鄰域裡的點也屬於該聚類,當這些新的點被加進聚類後,如果它(們)也在密集區域裡,它(們)的 ε-鄰域裡的點也會被加進聚類裡。這個過程將一直重覆,直至不能再加進更多的點為止,這樣,一個密度連結的聚類被完整地找出來。然後,一個未曾被訪問的點將被探索,從而發現一個新的聚類或雜音。
算法可以以下偽代碼表達,當中變數根據原本刊登時的命名:
DBSCAN(D, eps, MinPts) {
C = 0
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) < MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point P' in NeighborPts {
if P' is not visited {
mark P' as visited
NeighborPts' = regionQuery(P', eps)
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
}
if P' is not yet member of any cluster
add P' to cluster C
}
}
regionQuery(P, eps)
return all points within P's eps-neighborhood (including P)
注意這個算法可以以下方式簡化:其一,"has been visited" 和 "belongs to cluster C" 可被結合起來,另外 "expandCluster" 副程式不必被抽出來,因為它只在一個位置被调用。以上算法沒有以簡化方式呈現,以反映原本出版的版本。另外,regionQuery 是否包含 P 並不重要,它等價於改變 MinPts 的值。
複雜度
DBSCAN對資料庫裡的每一點進行訪問,可能多於一次(例如作為不同聚類的候選者),但在現實的考慮中,時間複雜度主要受regionQuery的调用次數影響,DBSCAN對每點都進行剛好一次调用,且如果使用了特別的編號結構,則總平均時間複雜度為,最差時間複雜度則為。可以使用空間複雜度的距離矩陣以避免重複計算距離,但若不使用距離矩陣,DBSCAN的空間複雜度為。




優點
- 相比 K-平均算法,DBSCAN 不需要預先聲明聚類數量。
- DBSCAN 可以找出任何形狀的聚類,甚至能找出一個聚類,它包圍但不連接另一個聚類,另外,由於 MinPts 參數,single-link effect (不同聚類以一點或極幼的線相連而被當成一個聚類)能有效地被避免。
- DBSCAN 能分辨噪音(局外點)。
- DBSCAN 只需兩個參數,且對資料庫內的點的次序幾乎不敏感(兩個聚類之間邊緣的點有機會受次序的影響被分到不同的聚類,另外聚類的次序會受點的次序的影響)。
- DBSCAN 被設計成能配合可加速範圍訪問的資料庫結構,例如 R*樹。
- 如果對資料有足夠的了解,可以選擇適當的參數以獲得最佳的分類。
缺點
- DBSCAN 不是完全決定性的:在兩個聚類交界邊緣的點會視乎它在資料庫的次序決定加入哪個聚類,幸運地,這種情況並不常見,而且對整體的聚類結果影響不大——DBSCAN 對核心點和噪音都是決定性的。DBSCAN* 是一種變化了的演算法,把交界點視為噪音,達到完全決定性的結果。
- DBSCAN 聚類分析的質素受函數 regionQuery(P,ε) 裡所使用的度量影響,最常用的度量是歐幾里得距離,尤其在高維度資料中,由於受所謂「維數災難」影響,很難找出一個合適的 ε ,但事實上所有使用歐幾里得距離的演算法都受維數災難影響。
- 如果資料庫裡的點有不同的密度,而該差異很大,DBSCAN 將不能提供一個好的聚類結果,因為不能選擇一個適用於所有聚類的 minPts-ε 參數組合。
- 如果沒有對資料和比例的足夠理解,將很難選擇適合的 ε 參數。
注意
參考文獻
延伸閱讀
- Arlia, Domenica; Coppola, Massimo. "Experiments in Parallel Clustering with DBSCAN". Euro-Par 2001: Parallel Processing: 7th International Euro-Par Conference Manchester, UK August 28–31, 2001, Proceedings. Springer Berlin.
- Kriegel, Hans-Peter; Kröger, Peer; Sander, Jörg; Zimek, Arthur (2011). "Density-based Clustering"(页面存档备份,存于). WIREs Data Mining and Knowledge Discovery. 1 (3): 231–240. doi:10.1002/widm.30.