半监督学习
半监督学习(英語:)是机器学习的一个分支,它在训练时使用了少量的有标签数据(Labeled data)和大量的无标签数据(Unlabeled data)。半监督学习介于无监督学习(训练数据全部无标签)和有监督学习(训练数据全部有标签)之间。半监督学习旨在缓解训练数据中有标签数据有限的问题。
| 机器学习与 |
|---|
无监督学习适用的的问题往往有着大量的无标签样本,同时获得有标签样本成本较高。部分其它机器学习分支有着相同动机,但是遵从不同的假设和方法,例如主动学习和弱监督学习。将无标签样本和少量有标签样本同时使用时,会对学习的准确性产生极大改善。为特定问题获得有标签的数据通常需要熟练工(例如转录音频片段)或进行物理实验(例如确定蛋白质的三维结构,或者确定特定地点是否有油气)。由此,获得有标签样本的成本往往较高,获取大型的、完全标注的样本集是不可行的;同时,获取无标签的样本成本往往相对较低。此时,半监督学习具有较大的使用价值。半监督学习在机器学习和人类学习的建模方面也具有理论价值。
正式的来说,半监督学习假设有个独立同分布的样本及对应的标签,和个无标签的样本。半监督学习结合这些样本来获得相比于放弃无标签样本进行有监督学习或放弃有标签样本进行无监督学习更好的分类性能。





半监督学习可以是推断学习或归纳学习。[1]推断学习的目的是推断给定无标签样本的正确标签;归纳学习的目的是推断到的正确映射。



直观地说,学习问题可以看成一次考试,有标签样本是为了帮助学习,由老师解答的样题。推断学习中,未解决的问题是考试题目;归纳学习中,它们是会构成考试的练习题。
对整个输入空间进行推断学习没有必要(依据Vapnik准则,也是不够谨慎的)。然而在实践中,为推断学习和归纳学习设计的算法通常交替使用。
假设
为了充分利用无标签数据,数据分布必须有某种潜在的规律。以下是半监督学习可能用到的假设:[2]
连续性、光滑性假设
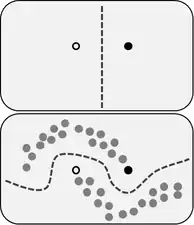
「相近的数据点往往更可能有相同的标签。」这也是有监督学习中的一般假设,该假设同时对几何学上的简单决策边界有所偏好。由于很少有点相互接近但属于不同的类别,因此半监督学习的平滑性假设还产生了对低密度区域的决策边界的偏好。
聚类假设
「数据倾向形成离散的集群,在同一个集群中的数据点往往更可能由相同的标签(尽管具有相同标签的数据点可能分散在多个集群中)。」这是平滑性假设的特例,产生了带有聚类算法的特征学习。
历史
启发式的自训练方法(self-training,也称自学习(slef-learning)或自标记(self-labeling))是历史上最古老的半监督学习方法,[2]其应用实例起源于20世纪60年代。[4]
推断学习的框架是由弗拉基米尔·瓦普尼克于20世纪70年代正式提出[5],对使用生成模型的归纳学习的兴趣也起源于同一时期。1995年,Ratsaby和Venkatesh证明了高斯混合模型半监督学习概率近似正确学习(Probably approximately correct learning,PAC Learning)的边界。[6]
半监督学习近期的流行是因为在实践中,大量的应用可以获得无标签数据(例如网页中的文本、蛋白质序列或图片)。[7]
方法
参考文献
- Chapelle, Olivier; Schölkopf, Bernhard; Zien, Alexander. . Cambridge, Mass.: MIT Press. 2006. ISBN 978-0-262-03358-9.
- . 2007. CiteSeerX 10.1.1.99.9681
 .
. - Chapelle, Schölkopf & Zien 2006.
- Stevens, Kenneth N., 1924-. . Cambridge, Mass.: MIT Press. 1998. ISBN 0-585-08720-2. OCLC 42856189.
- Scudder, H. . IEEE Transactions on Information Theory. July 1965, 11 (3): 363–371. ISSN 1557-9654. doi:10.1109/TIT.1965.1053799.
- Vapnik, V.; Chervonenkis, A. . Moscow: Nauka. 1974 (俄语). cited in Chapelle, Schölkopf & Zien 2006,第3頁
- Ratsaby, J.; Venkatesh, S. (PDF). [2023-03-22]. (原始内容存档 (PDF)于2017-08-09). in . New York, New York, USA: ACM Press. 1995: 412–417. ISBN 0-89791-723-5. S2CID 17561403. doi:10.1145/225298.225348.. Cited in Chapelle, Schölkopf & Zien 2006,第4頁
- Zhu, Xiaojin. (PDF). University of Wisconsin-Madison. 2008 [2023-03-22]. (原始内容存档 (PDF)于2016-03-03).