| Ḹ | |
|---|---|
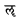 | |
| Example glyphs | |
| Bengali-Assamese | ৡ |
| Tibetan | ཨླཱྀ |
| Malayalam | ൡ |
| Sinhala | ඐ |
| Ashoka Brahmi | |
| Devanagari | |
| Cognates | |
| Hebrew | ל |
| Greek | Λ |
| Latin | L, Ł, Ɬ |
| Cyrillic | Л, Љ, Ԓ, Ӆ |
| Properties | |
| Phonemic representation | /l̩ː/ |
| IAST transliteration | ḹ Ḹ |
| ISCII code point | 00 (0) |
| Indic letters | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Consonants | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Vowels | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Other marks | |||||||||||||||||||||||||||||||||||||||||||||||||
| Punctuation | |||||||||||||||||||||||||||||||||||||||||||||||||
Ḹ is a vowel of Indic abugidas. In modern Indic scripts, Ḹ is derived from the early "Ashoka" Brahmi letter ![]() . As an Indic vowel, Ḹ comes in two normally distinct forms: 1) as an independent letter, and 2) as a vowel sign for modifying a base consonant. Bare consonants without a modifying vowel sign have the inherent "A" vowel.
. As an Indic vowel, Ḹ comes in two normally distinct forms: 1) as an independent letter, and 2) as a vowel sign for modifying a base consonant. Bare consonants without a modifying vowel sign have the inherent "A" vowel.
Āryabhaṭa numeration
Aryabhata used Devanagari letters for numbers, very similar to the Greek numerals, even after the invention of Indian numerals. The "Ḹ" sign was used to modify a consonant's value ×108, but the vowel letter did not have an inherent value by itself.[1]
Historic Ḹ
There are three different general early historic scripts - Brahmi and its variants, Kharoṣṭhī, and Tocharian, the so-called slanting Brahmi. Ḹ as found in Brahmi was missing in earlier geometric styles, but emerged during more flowing styles of Brahmi, such as the Kushana and Gupta. In both Tocharian and Kharoṣṭhī, Ḹ is not currently known from any source materials.
Brahmi Ḹ
The Brahmi letter Ḹ is only found as a vowel mark, and is derived from the consonant La, and therefore is probably from the Aramaic Lamed ![]() . This would make it related to the modern Latin L and Greek Lambda.[2] Several identifiable styles of writing the Brahmi Ḹ can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[3] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, but Ḹ must be back-formed from later forms to match the reference geometric writing style, and the reference image for the independent letter
. This would make it related to the modern Latin L and Greek Lambda.[2] Several identifiable styles of writing the Brahmi Ḹ can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[3] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, but Ḹ must be back-formed from later forms to match the reference geometric writing style, and the reference image for the independent letter ![]() is just the vowel mark enlarged to the size of a full letter.
is just the vowel mark enlarged to the size of a full letter.
Devanagari Ḹ

Ḹ (ॡ) is a vowel of the Devanagari abugida. It ultimately arose from the Brahmi letter ![]() . Letters that derive from it are the Gujarati letter ૡ, and the Modi letter 𑘉.
. Letters that derive from it are the Gujarati letter ૡ, and the Modi letter 𑘉.
Devanagari Using Languages
The Devanagari script is used to write the Hindi language, Sanskrit and the majority of Indo-Aryan languages. In most of these languages, ॡ is pronounced as [ḹ]. Like all Indic scripts, Devanagari vowels come in two forms: an independent vowel form for syllables that begin with a vowel sound, and a vowel sign attached to base consonant to override the inherent /ə/ vowel.
Bengali Ḹ


Ḹ (ৡ) is a vowel of the Bengali abugida. It is derived from the Siddhaṃ letter ![]() , and is marked a lack of horizontal head line and less geometric shape than its Devanagari counterpart, ॡ.
, and is marked a lack of horizontal head line and less geometric shape than its Devanagari counterpart, ॡ.
Bengali Script Using Languages
The Bengali script is used to write several languages of eastern India, notably the Bengali language and Assamese. In most languages, ৡ is pronounced as [ḹ]. Like all Indic scripts, Bengali vowels come in two forms: an independent vowel form for syllables that begin with a vowel sound, and a vowel sign attached to base consonant to override the inherent /ɔ/ vowel.
Gujarati Ḹ


Ḹ (ૡ) is a vowel of the Gujarati abugida. It is derived from the Devanagari Ḹ ![]() , and ultimately the Brahmi letter
, and ultimately the Brahmi letter ![]() .
.
Gujarati-using Languages
The Gujarati script is used to write the Gujarati and Kutchi languages. In both languages, ૡ is pronounced as [ḹ]. Like all Indic scripts, Gujarati vowels come in two forms: an independent vowel form for syllables that begin with a vowel sound, and a vowel sign attached to base consonant to override the inherent /ə/ vowel.
Javanese Ḹ
Telugu Ḹ


Ḹ (ౡ) is a vowel of the Telugu abugida. It ultimately arose from the Brahmi letter ![]() Ḹ. It is closely related to the Kannada letter ೡ. Like in other Indic scripts, Telugu vowels have two forms: and independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of Telugu consonant letters. Ḹ is a non-attaching vowel sign, and does not alter the underlying consonant or contextually shape itself in any way.
Ḹ. It is closely related to the Kannada letter ೡ. Like in other Indic scripts, Telugu vowels have two forms: and independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of Telugu consonant letters. Ḹ is a non-attaching vowel sign, and does not alter the underlying consonant or contextually shape itself in any way.

Malayalam Ḹ


Ḹ (ൡ) is a vowel of the Malayalam abugida. It ultimately arose from the Brahmi letter ![]() , via the Grantha letter
, via the Grantha letter ![]() ḹ. Like in other Indic scripts, Malayalam vowels have two forms: an independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of consonant letters. Vowel signs in Malayalam usually sit adjacent to its base consonant - below, to the left, right, or both left and right, but are always pronounced after the consonant sound.
ḹ. Like in other Indic scripts, Malayalam vowels have two forms: an independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of consonant letters. Vowel signs in Malayalam usually sit adjacent to its base consonant - below, to the left, right, or both left and right, but are always pronounced after the consonant sound.
Odia Ḹ


Ḹ (ୡ) is a vowel of the Odia abugida. It ultimately arose from the Brahmi letter ![]() , via the Siddhaṃ letter
, via the Siddhaṃ letter ![]() ḹ. Like in other Indic scripts, Odia vowels have two forms: an independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of consonant letters. Vowel signs in Odia usually sit adjacent to its base consonant - below, to the left, right, or both left and right, but are always pronounced after the consonant sound. No base consonants are altered in form when adding a vowel sign, and there are no consonant+vowel ligatures in Odia.
ḹ. Like in other Indic scripts, Odia vowels have two forms: an independent letter for word and syllable-initial vowel sounds, and a vowel sign for changing the inherent "a" of consonant letters. Vowel signs in Odia usually sit adjacent to its base consonant - below, to the left, right, or both left and right, but are always pronounced after the consonant sound. No base consonants are altered in form when adding a vowel sign, and there are no consonant+vowel ligatures in Odia.
Comparison of Ḹ
The various Indic scripts are generally related to each other through adaptation and borrowing, and as such the glyphs for cognate letters, including Ḹ, are related as well.
| Comparison of Ḹ in different scripts |
|---|
|
Notes
|
Character encodings of Ḹ
Most Indic scripts are encoded in the Unicode Standard, and as such the letter Ḹ in those scripts can be represented in plain text with unique codepoint. Ḹ from several modern-use scripts can also be found in legacy encodings, such as ISCII.
| Preview | ৡ | ౡ | ୡ | ೡ | ൡ | ૡ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | DEVANAGARI LETTER VOCALIC LL | BENGALI LETTER VOCALIC LL | TELUGU LETTER VOCALIC LL | ORIYA LETTER VOCALIC LL | KANNADA LETTER VOCALIC LL | MALAYALAM LETTER VOCALIC LL | GUJARATI LETTER VOCALIC LL | |||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 2401 | U+0961 | 2529 | U+09E1 | 3169 | U+0C61 | 2913 | U+0B61 | 3297 | U+0CE1 | 3425 | U+0D61 | 2785 | U+0AE1 |
| UTF-8 | 224 165 161 | E0 A5 A1 | 224 167 161 | E0 A7 A1 | 224 177 161 | E0 B1 A1 | 224 173 161 | E0 AD A1 | 224 179 161 | E0 B3 A1 | 224 181 161 | E0 B5 A1 | 224 171 161 | E0 AB A1 |
| Numeric character reference | ॡ | ॡ | ৡ | ৡ | ౡ | ౡ | ୡ | ୡ | ೡ | ೡ | ൡ | ൡ | ૡ | ૡ |
| ISCII | ||||||||||||||
| Preview | Ashoka Kushana Gupta | 𑍡 | ||||
|---|---|---|---|---|---|---|
| Unicode name | BRAHMI LETTER VOCALIC LL | SIDDHAM LETTER VOCALIC LL | GRANTHA LETTER VOCALIC LL | |||
| Encodings | decimal | hex | dec | hex | dec | hex |
| Unicode | 69646 | U+1100E | 71049 | U+11589 | 70497 | U+11361 |
| UTF-8 | 240 145 128 142 | F0 91 80 8E | 240 145 150 137 | F0 91 96 89 | 240 145 141 161 | F0 91 8D A1 |
| UTF-16 | 55300 56334 | D804 DC0E | 55301 56713 | D805 DD89 | 55300 57185 | D804 DF61 |
| Numeric character reference | 𑀎 | 𑀎 | 𑖉 | 𑖉 | 𑍡 | 𑍡 |
| Preview | 𑐉 | 𑆌 | ||
|---|---|---|---|---|
| Unicode name | NEWA LETTER VOCALIC LL | SHARADA LETTER VOCALIC LL | ||
| Encodings | decimal | hex | dec | hex |
| Unicode | 70665 | U+11409 | 70028 | U+1118C |
| UTF-8 | 240 145 144 137 | F0 91 90 89 | 240 145 134 140 | F0 91 86 8C |
| UTF-16 | 55301 56329 | D805 DC09 | 55300 56716 | D804 DD8C |
| Numeric character reference | 𑐉 | 𑐉 | 𑆌 | 𑆌 |
| Preview | ၕ | |
|---|---|---|
| Unicode name | MYANMAR LETTER VOCALIC LL | |
| Encodings | decimal | hex |
| Unicode | 4181 | U+1055 |
| UTF-8 | 225 129 149 | E1 81 95 |
| Numeric character reference | ၕ | ၕ |
| Preview | ឮ | |
|---|---|---|
| Unicode name | KHMER INDEPENDENT VOWEL LYY | |
| Encodings | decimal | hex |
| Unicode | 6062 | U+17AE |
| UTF-8 | 225 158 174 | E1 9E AE |
| Numeric character reference | ឮ | ឮ |
| Preview | ඐ | ꢋ | ||
|---|---|---|---|---|
| Unicode name | SINHALA LETTER ILUUYANNA | SAURASHTRA LETTER VOCALIC LL | ||
| Encodings | decimal | hex | dec | hex |
| Unicode | 3472 | U+0D90 | 43147 | U+A88B |
| UTF-8 | 224 182 144 | E0 B6 90 | 234 162 139 | EA A2 8B |
| Numeric character reference | ඐ | ඐ | ꢋ | ꢋ |
| Preview | 𑘉 | |
|---|---|---|
| Unicode name | MODI LETTER VOCALIC LL | |
| Encodings | decimal | hex |
| Unicode | 71177 | U+11609 |
| UTF-8 | 240 145 152 137 | F0 91 98 89 |
| UTF-16 | 55301 56841 | D805 DE09 |
| Numeric character reference | 𑘉 | 𑘉 |
| Preview | 𑒊 | |
|---|---|---|
| Unicode name | TIRHUTA LETTER VOCALIC LL | |
| Encodings | decimal | hex |
| Unicode | 70794 | U+1148A |
| UTF-8 | 240 145 146 138 | F0 91 92 8A |
| UTF-16 | 55301 56458 | D805 DC8A |
| Numeric character reference | 𑒊 | 𑒊 |
| Preview | ᬎ | ꦋ | ||
|---|---|---|---|---|
| Unicode name | BALINESE LETTER LA LENGA TEDUNG | JAVANESE LETTER NGA LELET RASWADI | ||
| Encodings | decimal | hex | dec | hex |
| Unicode | 6926 | U+1B0E | 43403 | U+A98B |
| UTF-8 | 225 172 142 | E1 AC 8E | 234 166 139 | EA A6 8B |
| Numeric character reference | ᬎ | ᬎ | ꦋ | ꦋ |
References
- ↑ Ifrah, Georges (2000). The Universal History of Numbers. From Prehistory to the Invention of the Computer. New York: John Wiley & Sons. pp. 447–450. ISBN 0-471-39340-1.
- ↑ Bühler, Georg (1898). "On the Origin of the Indian Brahmi Alphabet". archive.org. Karl J. Trübner. Retrieved 10 June 2020.
- ↑ Evolutionary chart, Journal of the Asiatic Society of Bengal Vol 7, 1838