熵 (信息论)
在信息论中,熵(英語:)是接收的每条消息中包含的信息的平均量,又被稱為信息熵、信源熵、平均自信息量。这里,“消息”代表来自分布或数据流中的事件、样本或特征。(熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。)来自信源的另一个特征是样本的概率分布。这里的想法是,比较不可能发生的事情,当它发生了,会提供更多的信息。由于一些其他的原因,把信息(熵)定义为概率分布的对数的相反数是有道理的。事件的概率分布和每个事件的信息量构成了一个随机变量,这个随机变量的均值(即期望)就是这个分布产生的信息量的平均值(即熵)。熵的单位通常为比特,但也用Sh、nat、Hart计量,取决于定义用到对数的底。
采用概率分布的对数作为信息的量度的原因是其可加性。例如,投掷一次硬币提供了1 Sh的信息,而掷m次就为m位。更一般地,你需要用log2(n)位来表示一个可以取n个值的变量。
在1948年,克劳德·艾尔伍德·香农將熱力學的熵,引入到信息论,因此它又被稱為香农熵(Shannon entropy)[1][2]。
简介
熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。但是在信息世界,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
英语文本数据流的熵比较低,因为英语很容易读懂,也就是说很容易被预测。即便我们不知道下一段英语文字是什么内容,但是我们能很容易地预测,比如,字母e总是比字母z多,或者qu字母组合的可能性总是超过q与任何其它字母的组合。如果未经压缩,一段英文文本的每个字母需要8个比特来编码,但是实际上英文文本的熵大概只有4.7比特。這是由於英文的編碼包含了各式符號,如逗號、引號等。因此英文輸入法使用了8個位元來表達一共256個字母及符號。
如果压缩是无损的,即通过解压缩可以百分之百地恢复初始的消息内容,那么压缩后的消息携带的信息和未压缩的原始消息是一样的多。而压缩后的消息可以通过较少的比特传递,因此压缩消息的每个比特能携带更多的信息,也就是说压缩信息的熵更加高。熵更高意味着比较难于预测压缩消息携带的信息,原因在于压缩消息里面没有冗余,即每个比特的消息携带了一个比特的信息。香农的信源编码定理揭示了,任何无损压缩技术不可能让一比特的消息携带超过一比特的信息。消息的熵乘以消息的长度决定了消息可以携带多少信息。
香农的信源编码定理同时揭示了,任何无损压缩技术不可能缩短任何消息。根据鸽笼原理,如果有一些消息变短,则至少有一条消息变长。在实际使用中,由于我们通常只关注于压缩特定的某一类消息,所以这通常不是问题。例如英语文档和随机文字,数字照片和噪音,都是不同类型的。所以如果一个压缩算法会将某些不太可能出现的,或者非目标类型的消息变得更大,通常是无关紧要的。但是,在我们的日常使用中,如果去压缩已经压缩过的数据,仍会出现问题。例如,将一个已经是FLAC格式的音乐文件压缩为ZIP文件很难使它占用的空间变小。
熵的计算
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。因此,使用一枚正常硬币进行若干次抛掷,这个事件的熵是一比特,因为结果不外乎两个——正面或者反面,可以表示为0, 1编码,而且两个结果彼此之间相互独立。若进行n次独立实验,则熵为n,因为可以用长度为n的比特流表示。[3]但是如果一枚硬币的两面完全相同,那个这个系列抛硬币事件的熵等于零,因为结果能被准确预测。现实世界里,我们收集到的数据的熵介于上面两种情况之间。
另一个稍微复杂的例子是假设一个随机变量X,取三种可能值,概率分别为,那么编码平均比特长度是:。其熵为3/2。



因此熵实际是对随机变量的比特量和顺次发生概率相乘再总和的数学期望。
定义
依据Boltzmann's H-theorem,香农把随机变量X的熵值 Η(希腊字母Eta)定义如下,其值域为{x1, ..., xn}:
- 。
![{\displaystyle \mathrm {H} (X)=\mathrm {E} [\mathrm {I} (X)]=\mathrm {E} [-\ln(\mathrm {P} (X))]}](../I/ad96d27b76b011b9cb7c41665e3e25edf04b3515.svg)
其中,P为X的機率質量函數(probability mass function),E为期望函數,而I(X)是X的資訊量(又稱為資訊本體)。I(X)本身是個隨機變數。
当取自有限的样本时,熵的公式可以表示為:

在這裏b是對數所使用的底,通常是2,自然常數e,或是10。當b = 2,熵的單位是bit;當b = e,熵的單位是nat;而當b = 10,熵的單位是Hart。
pi = 0时,对於一些i值,对应的被加数0 logb 0的值将会是0,这与极限一致。
- 。

还可以定义事件 X 与 Y 分别取 xi 和 yj 时的条件熵为

其中p(xi, yj)为 X = xi 且 Y = yj 时的概率。这个量应当理解为你知道Y的值前提下随机变量 X 的随机性的量。
範例
如果有一个系统S内存在多个事件S = {E1,...,En},每个事件的機率分布P = {p1, ..., pn},则每个事件本身的訊息(資訊本體)为:
- (对数以2为底,单位是位元(bit))

- (对数以为底,单位是纳特/nats)


如英语有26个字母,假如每个字母在文章中出现次数平均的话,每个字母的訊息量为:

以日文五十音平假名作為相對範例,假設每個平假名日語文字在文章中出現的機率相等,每個平假名日語文字可攜帶的資訊量為:

而汉字常用的有2500个,假如每个汉字在文章中出现次数平均的话,每个汉字的信息量为:

实际上每个字母和每个汉字在文章中出现的次数并不平均,比方说较少见字母(如z)和罕用汉字就具有相对高的信息量。但上述计算提供了以下概念:使用书写单元越多的文字,每个单元所包含的訊息量越大。
熵是整个系统的平均消息量,即:

因为和热力学中描述热力学熵的玻尔兹曼公式本质相同(仅仅单位不同,一纳特的信息量即相当于k焦耳每开尔文的热力学熵),所以也称为“熵”。
如果两个系统具有同样大的消息量,如一篇用不同文字写的同一文章,由于汉字的信息量较大,中文文章应用的汉字就比英文文章使用的字母要少。所以汉字印刷的文章要比其他应用总体数量少的字母印刷的文章要短。即使一个汉字占用两个字母的空间,汉字印刷的文章也要比英文字母印刷的用纸少。
熵的特性
可以用很少的标准来描述香农熵的特性,将在下面列出。任何满足这些假设的熵的定义均正比以下形式

其中,K是与选择的度量单位相对应的一个正比常数。
下文中,pi = Pr(X = xi)且

连续性
该量度应连续,概率值小幅变化只能引起熵的微小变化。
对称性
符号xi重新排序后,该量度应不变。
- 等。

极值性
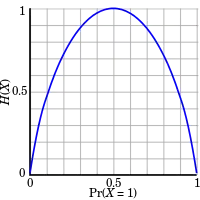
当所有符号有同等機會出现的情况下,熵达到最大值(所有可能的事件同等概率时不确定性最高)。
- 。

等概率事件的熵应随符号的数量增加。


进一步性质
香农熵满足以下性质,藉由將熵看成「在揭示随机变量X的值後,從中得到的信息量(或消除的不确定性量)」,可來幫助理解其中一些性質。
- 增減一概率为零的事件不改变熵:

- 可用琴生不等式证明
- 具有均匀概率分布的信源符号集可以有效地达到最大熵logb(n):所有可能的事件是等概率的时候,不确定性最大。
![{\displaystyle \mathrm {H} (X)=\operatorname {E} \left[\log _{b}\left({\frac {1}{p(X)}}\right)\right]\leq \log _{b}\left(\operatorname {E} \left[{\frac {1}{p(X)}}\right]\right)=\log _{b}(n)}](../I/e25cc561059371b9c345934747aa8b3902daf136.svg)
- 计算 (X,Y)得到的熵或信息量(即同时计算X和Y)等于通过进行两个连续实验得到的信息:先计算Y的值,然后在你知道Y的值条件下得出X的值。写作
- 。

- 如果Y=f(X),其中f是确定性的,那么Η(f(X)|X) = 0。应用前一公式Η(X, f(X))就会产生
- 所以Η(f(X)) ≤ Η(X),因此当后者是通过确定性函数传递时,变量的熵只能降低。

- 如果X和Y是两个独立实验,那么知道Y的值不影响我们对X值的认知(因为两者独立,所以互不影响):
- 。

- 两个事件同时发生的熵不大于每个事件单独发生的熵的总和,且仅当两个事件是独立的情况下相等。更具体地说,如果X和Y是同一概率空间的两个随机变量,而 (X,Y)表示它们的笛卡尔积,则
- 。
- 在前两条熵的性质基础上,很容易用数学证明这一点。

和热力学熵的联系
物理学家和化学家对一个系统自发地从初始状态向前演进过程中,遵循热力学第二定律而发生的熵的变化更感兴趣。在传统热力学中,熵被定义为对系统的宏观测定,并没有涉及概率分布,而概率分布是信息熵的核心定义。
根据Jaynes(1957)的观点,热力学熵可以被视为香农信息理论的一个应用: 热力学熵被解釋成與定義系統的微態細節所需的進一步香农資訊量成正比,波茲曼常數為比例系數,其中系統與外界無交流,只靠古典熱力學的巨觀變數所描述。加熱系統會提高其热力学熵,是因為此行為增加了符合可測巨觀變數 的系統微態的數目,也使得所有系統的的完整敘述變得更長。(假想的)麦克斯韦妖可利用每個分子的状态信息,來降低热力学熵,但是羅夫·蘭道爾(於1961年)和及其同事則證明了,让小妖精行使职责本身——即便只是了解和储存每个分子最初的香农信息——就会给系统带来热力学熵的增加,因此总的来说,系统的熵的总量没有减少。这就解决了Maxwell思想实验引发的悖论。蘭道爾原理也為現代計算機處理大量資訊時所產生的熱量給出了下限,雖然現在計算機的廢熱遠遠比這個限制高。
参考
- Shannon, Claude E. . Bell System Technical Journal. July 1948, 27 (3): 379–423. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:10338.dmlcz/101429. (PDF, archived from here (页面存档备份,存于))
- Shannon, Claude E. . Bell System Technical Journal. October 1948, 27 (4): 623–656. doi:10.1002/j.1538-7305.1948.tb00917.x. hdl:11858/00-001M-0000-002C-4317-B. (PDF, archived from here (页面存档备份,存于))
- Douglas Robert Stinson; Maura Paterson. . [密码学理论与实践] 2.
- 詹姆斯·格雷克. . [信息简史]. 高博 (翻译), 楼伟珊 (审校), 高学栋 (审校), 李松峰 (审校) 1. 人民邮电出版社. 2013: 265. ISBN 978-7-115-33180-9 (中文(中国大陆)).
根据在贝尔实验室里流传的一个说法,是约翰·冯·诺依曼建议香农使用这个词,因为没有人懂这个词的意思,所以他与人争论时可以无往而不利。这件事虽然子虚乌有,但听起来似乎有点道理。
外部链接
- Hazewinkel, Michiel (编), , , Springer, 2001, ISBN 978-1-55608-010-4